

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In this tutorial, we’ll talk about a 3D reconstruction technique called Space Carving.
We’ll go through the 3D reconstruction of objects in general, and then we’ll see what are the use cases and the assumptions for using space carving. In the end, we’ll discuss the limitations of the approach.
2. 3D Reconstruction
In the field of Computer Vision, a particularly interesting problem with a diverse range of practical applications is the process of generating the 3D representation of an object, given a set of 2D images.
This task can be easily done by human beings, even on the basis of only one image, if the object is regular and familiar enough. For example, we can intuitively figure out what the entire 3D shape of a cup, a ball, or a book should look like, even if we can only see it from one perspective. The same principle is leveraged by deep learning-based approaches that manage to produce 3D representations of objects from very few images, provided similar objects were used in the training process.
In contrast to these approaches, we’ll see that Space Carving doesn’t assume anything about the shape of the object to be reconstructed. It pieces together information that can be gathered from multiple perspective pictures.
3. Space Carving
In the general case, the reconstruction of a 3D object involves taking multiple photos of the object from as many points of view as possible. This is done either by using multiple cameras placed strategically around the object or by using a single camera and successively moving and rotating the object. In both cases, the background against which the object is placed should be as simple as possible in order for the segmentation process to be done using only color information.
Space carving starts with a voxel grid, which is similar to the pixel representation of an image, but in 3 dimensions. We’ll assume that the object is fully contained in this grid.
By using information from the first picture we have, we can easily decide what voxels aren’t part of the object itself.
Thus, we’re able to carve out the voxels that we’re able to see in a similar way to carving a statue from a block of marble. Then, using information from subsequent pictures taken from different perspectives, we can cut out more and more from the object until we end up with a good approximation in voxel space.
The following image showcases a top-down view of the space-carving process:
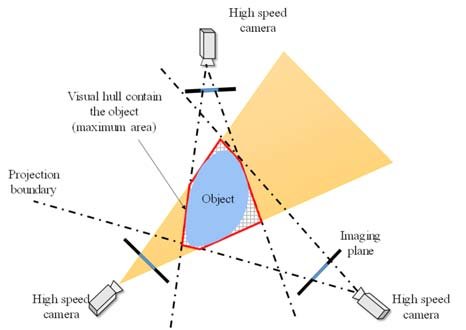
There are 3 cameras set in different locations around the object. Each camera has its own field of view that gets wider the further away we get from it. The real object will be located inside the intersection of the 3 fields of view.
Naturally, the more cameras we have, the better the reconstruction will be, as we’ll able to carve from more angles.
4. Limitations
Let’s now discuss the limitations. If the camera that takes the pictures used in the reconstruction doesn’t have a depth-detection mechanism (such as a lidar), it’s not possible to reconstruct the contents of holes inside of the object; The simplest example is reconstructing empty space inside of a regular cup. The reason for this is the fact that space carving doesn’t use information about lighting and shadows. It considers each pixel of the original image as either being part of the object or part of the background.
5. Conclusion
In this article, we discussed the main principles and applications of Space Carving. We started with a general overview of the 3D reconstruction problem; then, we detailed the steps taken by this approach. Finally, we mentioned the limitations of Space Carving as a technique and explained how they could be overcome by the use of special cameras including depth information.