

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Similar to Sigmoid, tanh, and ReLU, Softmax is a type of activation function that plays a crucial role in the neural network. Activation functions introduce non-linear properties to the model, enabling it to learn complex data patterns. We can find Softmax in many signature deep neural networks, such as Seq2Seq Model, Transformers, and GPT-2.
In this tutorial, we’ll look at the Softmax function, which is widely used in classification problems. In addition, we’ll compare it with Log Softmax.
Softmax is an activation function commonly applied as the output of a neural network in multi-class classification tasks. It converts a vector of real numbers into a vector of probabilities. In the classification task, the value within the probability vector represents each class’s probability. We can calculate the Softmax layer as follows.
![\[\sigma(x_i)=\frac{e^{x_i}}{\Sigma_{k}e^{x_k}}\]](/wp-content/ql-cache/quicklatex.com-ceb7f0c23653ec03f9c11c98c81a2d36_l3.svg "Rendered by QuickLaTeX.com")
Where  is the input vector,
is the input vector,  represents the number of classes in the multi-class classifier, and
represents the number of classes in the multi-class classifier, and  is the standard exponential function.
is the standard exponential function.
To understand the Softmax function, let’s imagine a neural network is trying to classify an image into “dog”, “cat”, “bird”, or “fish”. The final layer of the network will produce a set of scores for each category. However, these scores are difficult to interpret. This is where Softmax comes into play.
The Softmax function takes these scores and squashes them into probabilities that sum up to 1. Introducing the Softmax function makes it extremely useful for classification tasks where we need a clear, probabilistic understanding of each class’s likelihood.
The following figure gives an example of a network with a Softmax layer as the output:
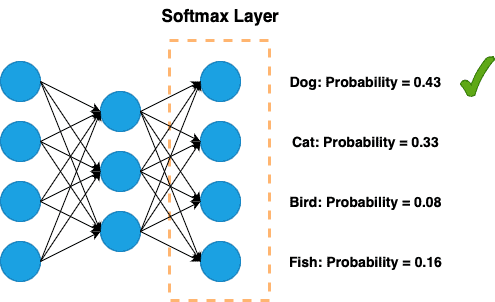
As shown in the figures, the Softmax layer calculates the probability of each class. The class with the most significant probability is the actual prediction of the network. Furthermore, the sum of the probabilities between the four categories is equal to 1.
The figure below illustrates the sigmoid and tanh functions:
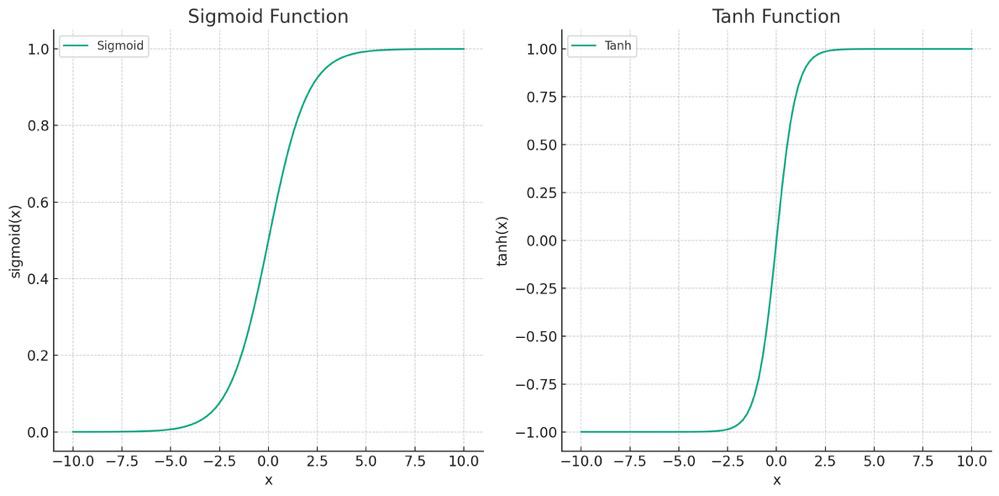
The -axis is the value from the final layer of the network. Compared to sigmoid and tanh functions, Softmax can be applied to multi-class classification instead of just binary classification.
In the Softmax function, one key element is the exponential function. The use of exponential functions simplifies the calculation of the gradient while using negative log likelihood as the loss function. Therefore, it helps train a large complex network.
The combination of Softmax and negative log likelihood is also known as cross-entropy loss. We can consider the cross entropy loss for a multi-class classification problem as the sum of the negative log likelihood for each individual class.
However, using the exponential function also brings challenges to training the neural work. For example, the exponential of an output value can be a very large number.
When the number is used in further calculations (like during loss computation), it can lead to numerical instability due to the limitations of floating-point representations in computers.
Log Softmax, as the name indicated, computes the logarithm of the softmax function.
![\[Log\_Softmax (x)= \log{\sigma(x)}\]](/wp-content/ql-cache/quicklatex.com-f8722d165c8c47839c974fd462d8b08a_l3.svg "Rendered by QuickLaTeX.com")
The figure below illustrates the difference between Softmax and Log Softmax, giving the same value from the network:flog
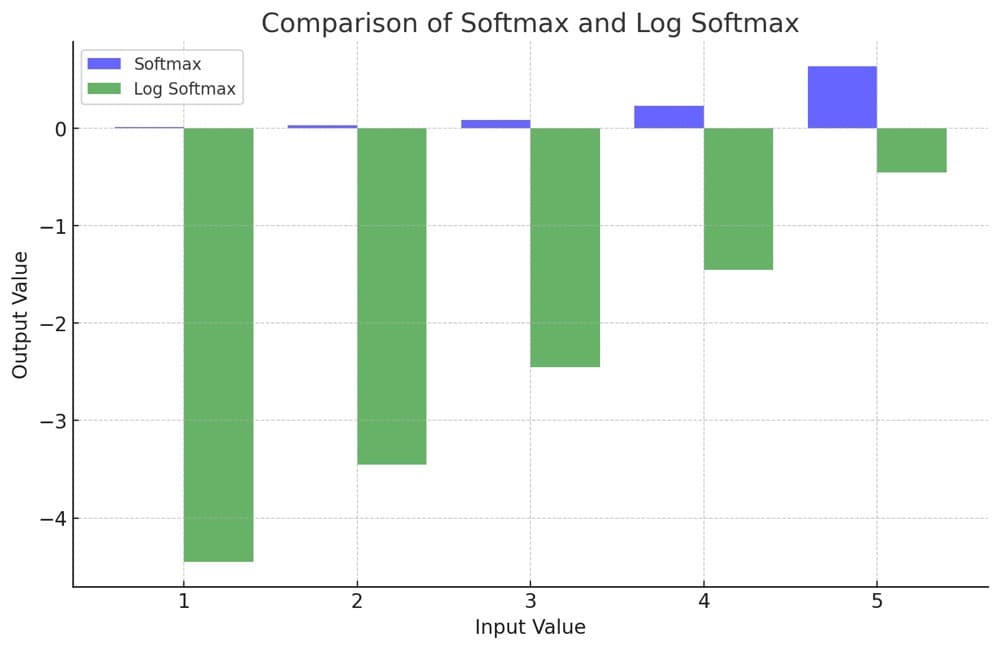
As we can see in the plot, the process of taking the log of the Softmax transforms large numbers into a much smaller scale. Moreover, the probability can sometimes be very small and exceed the limitation of floating-point representations. Applying Log Softmax also transfers the small probability into a negative number with a larger scale. This reduces the risk of numerical problems.
Compared to the Softmax function, Log Softmax has the following advantages when training a neural network:
Despite the fact that Softmax and log Softmax play an important role in multi-class classification, there are some limitations:
In this article, we looked at Softmax and Log Softmax. Softmax provides a way to interpret neural network outputs as probabilities, and Log Softmax improves standard Softmax by offering numerical stability and computational efficiency. Both of them are leveraged in multi-class classification tasks in deep learning.
On the other hand, they also have some limitations, such as overconfidence and sensitivity to outliners. Thus, we need to choose the activation functions depending on the task and the data.