

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about skip lists. They are a popular probabilistic alternative to balanced trees. We’ll explain how the skip lists work and show how to implement three standard operations on them: insertion, search, and deletion.
Let’s imagine a sorted linked list with  numbers:
numbers:

If we search for a number in it, we’ll traverse all elements in the worst case (when the sought value is greater than the list’s maximum). We start from the first node and follow all the pointers to the last one.
Now, let’s add a pointer two nodes ahead to every other node:

Starting from the first node, we can skip two nodes at a time, so we won’t visit more than  nodes in the worst case before we either find the number we seek or conclude it’s not in the list:
nodes in the worst case before we either find the number we seek or conclude it’s not in the list:

What would happen if we gave every fourth node a pointer four nodes ahead of it? Then, the number of nodes we visit in the worst case would be approximately  . In general, if every
. In general, if every  -th node has a pointer to the node nodes ahead of it, we reduce the number of nodes we have to examine in the worst-case search scenario to
-th node has a pointer to the node nodes ahead of it, we reduce the number of nodes we have to examine in the worst-case search scenario to  .
.
That’s the main idea behind skip lists. They contain nodes with more than one forward pointer, thus allowing for fast lookup. A node with  forward pointers is called a level- node. Half the nodes are level 1,
forward pointers is called a level- node. Half the nodes are level 1,  of the nodes are level 2,
of the nodes are level 2,  are level 3,
are level 3,  nodes are level , and so on.
nodes are level , and so on.
However, deletion and insertion would be impractical in the case of the above skip list. After deleting or inserting an element, we’ll have to update the pointers to keep pointing to the new nodes at appropriate positions.
A way to avoid the overhead is to keep the changes local. We can do that if we don’t fix the positions of the higher-level nodes. For example, we can decide the level of a new node randomly so that higher-level nodes aren’t necessarily  (
( ) nodes from one another. Instead, a level- pointer will point to the next level- node wherever it is in the list. That way, insertions, and deletions won’t lead to rearranging the pointers other than that pointed to the node immediately after the inserted one. The analogous reasoning holds for deletion.
) nodes from one another. Instead, a level- pointer will point to the next level- node wherever it is in the list. That way, insertions, and deletions won’t lead to rearranging the pointers other than that pointed to the node immediately after the inserted one. The analogous reasoning holds for deletion.
To keep the logarithmic complexity of the search, we can maintain the same ratio of the levels’ sizes from the above example. We do that by setting to  the probability to advance a level-(
the probability to advance a level-( ) node to the level while inserting it into the list. In that case, we’ll have approximately nodes at level
) node to the level while inserting it into the list. In that case, we’ll have approximately nodes at level  .
.
Therefore, a skip list is a multilevel linked list with its nodes’ levels decided randomly.
If we don’t limit the levels in advance, they’ll depend only on the chosen chance to advance a node during insertion. We don’t have to use as in the above example. Any  can serve as the probability, and the time complexity of search will still be .
can serve as the probability, and the time complexity of search will still be .
Here’s the pseudocode for selecting a new node’s level:
algorithm RandomLevel(p, maxLevel):
// INPUT
// p = the probability to advance a node from one level to the next
// maxLevel = the maximal allowed level, infinity if unrestricted
// OUTPUT
// The randomly selected level of a new node
level <- 1
// RANDOM draws a random number from the uniform distribution over [0, 1]
while (RANDOM() <= p) and (level < maxLevel):
level <- level + 1
return levelA node cannot be at the level without first becoming a level- node. So, the probability of a node being at level
node. So, the probability of a node being at level  is
is  (we subtract 1 because we don’t toss the dice for deciding the first level). From there, we see that a node’s level minus 1 follows a geometric distribution with
(we subtract 1 because we don’t toss the dice for deciding the first level). From there, we see that a node’s level minus 1 follows a geometric distribution with  as the “success probability”. So, the expected value of a node’s level is:
as the “success probability”. So, the expected value of a node’s level is:
(1)
There are pointers in a single-linked list with nodes. One of them points to the head, while the rest form the links between the nodes. Since all the nodes’ levels are  , we know there will be level-1 pointers.
, we know there will be level-1 pointers.
At the second level, we expect to have  pointers, the same as the expected number of level-2 nodes. The same applies to the higher levels. So, the expected number of pointers is (if
pointers, the same as the expected number of level-2 nodes. The same applies to the higher levels. So, the expected number of pointers is (if  is
is  ):
):
With the maximal level set to  , the number of pointers is bounded from above by
, the number of pointers is bounded from above by  . Since
. Since  is independent of , the expected memory complexity of a skip list is
is independent of , the expected memory complexity of a skip list is  , same as the space complexity of a linked list. Moreover, we see that we won’t ever use more than twice the pointers a single-linked list has (since
, same as the space complexity of a linked list. Moreover, we see that we won’t ever use more than twice the pointers a single-linked list has (since  ).
).
We’ll consider a node the data structure with the following attributes:
 : the value it contains
: the value it contains : the array of pointers to the successors at various levels
: the array of pointers to the successors at various levelsSimilarly, we’ll assume that the list is a data structure with two attributes:
– the current maximal level of the list – the array of pointers to the heads at the levels
– the array of pointers to the heads at the levels 
To insert a node with value  into a skip list, we have to do three things:
into a skip list, we have to do three things:
We’ve already seen how to choose the level  of the new node
of the new node  . To find where to place it, we start from the head node at the top level and follow the pointers until we reach two consecutive nodes,
. To find where to place it, we start from the head node at the top level and follow the pointers until we reach two consecutive nodes,  and
and  , such that
, such that  . If such nodes exist and isn’t greater than the current level (i.e., the top-level), we should update
. If such nodes exist and isn’t greater than the current level (i.e., the top-level), we should update  to point to and set the new node to point to
to point to and set the new node to point to  . Then, we repeat the steps until we reach the bottom layer.
. Then, we repeat the steps until we reach the bottom layer.
If the new node’s level is higher than the current maximal level of the entire list, we should insert new levels. We do that by setting the new node as their head.
Here’s the pseudocode of insertion:
algorithm InsertIntoSkipList(head, v, maxLevel):
// INPUT
// head = the head of the skip list
// v = the value to insert
// maxLevel = the maximal level of a new node
// OUTPUT
// v is inserted into the list
level <- RandomLevel(maxLevel)
if level > list.maxLevel:
for k <- list.maxLevel + 1 to level:
list.heads[k] <- make an empty node (NULL)
list.maxLevel <- level
update <- make an empty array with level reserved elements
y <- make a node whose value is v
for k <- list.maxLevel down to 1:
x <- list.heads[k]
if x is empty:
list.heads[k] <- y
else:
z <- x.successors[k]
while (z != NULL) and (v > z.value):
x <- z
z <- z.pointers[k]
x.successors[k] <- y
y.successors[k] <- zLet’s say that we want to insert the number  into this skip list:
into this skip list:
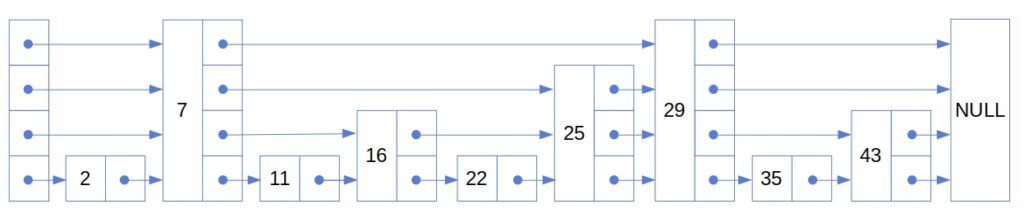
We follow these pointers to find where to place it:
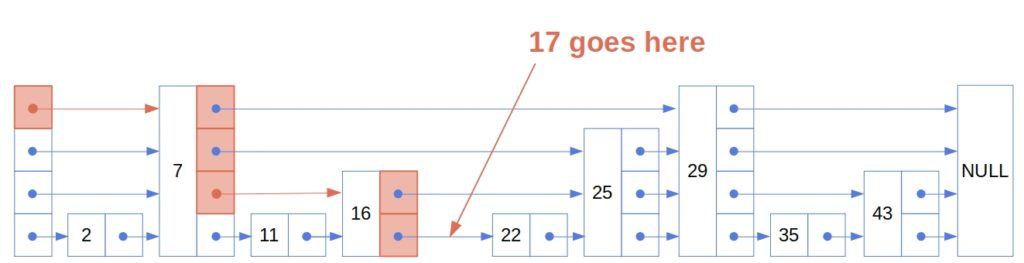
Let’s also say that we chose to set it up as a level-2 node. This is what the list looks like after insertion (the new node and new pointers are in red):

The complexity of insertion, as well as deletion, is dominated by the complexity of the search. To see why, let’s observe that before inserting a new element, we need to locate where to put it. The same goes for deleting a node. We have to find it before deleting it.
Let’s see how we search a skip list for some value . It’s similar to inserting into the list, but we don’t have to update any pointers. We can start at the top level and follow the pointers until we find  or a value greater than . In the former case, we return the corresponding node. In the latter, we step one level down and repeat the steps. The search ends when we find or cascade to the bottom-level node greater than . The node right before it must contain if the value is in the list. Otherwise, we return
or a value greater than . In the former case, we return the corresponding node. In the latter, we step one level down and repeat the steps. The search ends when we find or cascade to the bottom-level node greater than . The node right before it must contain if the value is in the list. Otherwise, we return  .
.
Here’s the pseudocode of search:
algorithm Search(list, v):
// INPUT
// list = the skip list to search
// v = the value to find
// OUTPUT
// x = the node containing v, or failure if v is not in the list
x <- list.heads[list.maxLevel]
for k <- list.maxLevel to 1:
if x = NULL:
x <- list.heads[k]
while x.successors[k] != NULL and x.successors[k].value < v:
x <- x.successors[k]
// At this point: x.value < v <= x.successors[1].value
if x.successors[1] != NULL and x.successors[1].value = v:
return x.successors[1]
else:
return failureHere are the steps we make while searching for 17 in the above list:
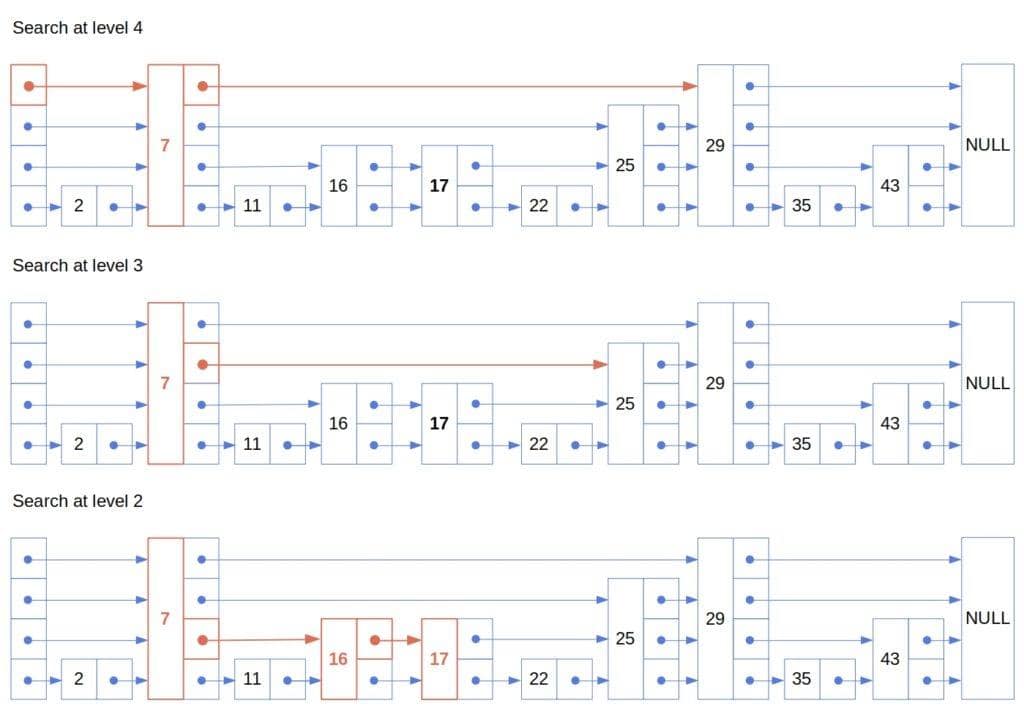
We’ll express the expected complexity of the search as the expected length of a search path. It starts in the top-left node (whose level is  ) and ends in the goal node (
) and ends in the goal node ( levels below ).
levels below ).
It’s easier to derive the expected length by analyzing the path in reverse. We’ll split it into two parts:
![list.heads[list.maxLevel]](/wp-content/ql-cache/quicklatex.com-d0f72a977d1523415704bd34180556a5_l3.svg "Rendered by QuickLaTeX.com") ) and the first top node we got to in reverse
) and the first top node we got to in reverseLet  be the expected length of the first part. Since skip lists are non-deterministic, we take the expectation over their possible structures. So, from a node levels below the top, we can either go back one level up with probability or move left with probability :
be the expected length of the first part. Since skip lists are non-deterministic, we take the expectation over their possible structures. So, from a node levels below the top, we can either go back one level up with probability or move left with probability :
Since  (no need to move to the top level if we’re already at it), we get:
(no need to move to the top level if we’re already at it), we get:
We’ve already solved the second part when we analyzed the number of nodes at different levels. So, we expect the top level to contain  nodes. Therefore, the total expected complexity of the search is:
nodes. Therefore, the total expected complexity of the search is:
(2)
The idea is to choose in such a way that  becomes a constant
becomes a constant  . So, we solve the corresponding equation for :
. So, we solve the corresponding equation for :
So, the first part in Equation (2) becomes  , and the second part reduces to
, and the second part reduces to  . Therefore, the total expected complexity will be logarithmic if we set
. Therefore, the total expected complexity will be logarithmic if we set  to a logarithm of
to a logarithm of  .
.
In this analysis, we assumed that was the list’s max level and that we always start the search from the top-level head.
In the worst case, the skip list degenerates to a single-linked list, and we’re looking for a value greater than the maximum. So, the worst-case complexity is because we traverse the whole list.
Even though it’s a pessimistic result, skip lists still pay off. The reasoning is similar to the case of Quicksort with random pivot selection. The theoretically worst possible performance may be poor, but it occurs rarely. In practice, skip lists are very efficient. The logarithmic expected complexity shows it.
Deletion is similar to insertion and search. We first find the node containing the value we want to delete. In the process, we memorize which nodes point to it. If we find the node, we unlink it from its predecessors and point them to the node’s successors at the appropriate levels:
algorithm Delete(list, v):
// INPUT
// list = the skip list
// v = the value to delete
// OUTPUT
// if present, a node whose value is v is deleted from list
update <- make an empty array with list.maxLevel NULL elements
for k <- list.maxLevel down to 1:
x <- list.heads[k]
y <- x.successors[k]
while y != NULL and v > y.value:
x <- y
y <- x.successors[k]
if y != NULL:
// At this point we have that y.value >= v
if y.value = v:
// y will be deleted, and we will point x to y's k-th successor
update[k] <- x
if y.value = v:
// v is in the list, so we delete y by removing any links to it
for k <- 1 to list.maxLevel:
if update[k] != NULL:
update[k].successors[k] <- y.successors[k]
// We decrease the max level if it has been completely deleted
while list.maxLevel > 1 and list.heads[list.maxLevel] = NULL:
list.maxLevel <- list.maxLevel - 1In this article, we presented skip lists. We showed three algorithms for skip lists: insertion, search, and deletion. Also, we analyzed the lists as a non-deterministic data structure and showed how to get the logarithmic expected complexity of the search.
Since the complexity of search dominates that of insertion and deletion, the latter two operations can also be made logarithmic. Even though the worst-case complexity is linear, using skip lists still pays off as the worst-case scenario isn’t likely in practice.

![\[\begin{aligned} n + \sum_{k=2}^{\infty}p^{k-1}(1-p)n &= n \left(1 +\sum_{k=2}^{\infty}p^{k-1}(1-p) \right) \\ &= n \left( 1 + (1-p)\sum_{k-1}^{\infty}p^k \right) \\ &= n \left( 1 + (1-p)\frac{p}{1-p} \right) \\ &= n \left( 1 + p ) \end{aligned}\]](/wp-content/ql-cache/quicklatex.com-85ce960799e1319c03fd0bcee87ca111_l3.svg "Rendered by QuickLaTeX.com")
![\[\begin{aligned} L(k) &= 1 + p L(k-1) + (1-p)L(k) \\ p L(k) &= 1 + p L(k-1) \\ L(k) &= \frac{1}{p} + L(k-1) \end{aligned}\]](/wp-content/ql-cache/quicklatex.com-817eb5614533f969d00642236e80c533_l3.svg "Rendered by QuickLaTeX.com")
![\[L(\ell) = \frac{\ell}{p}\]](/wp-content/ql-cache/quicklatex.com-3dbde5b894966f5028e35767cd8d96d1_l3.svg "Rendered by QuickLaTeX.com")

![\[\begin{aligned} p^{\ell}n &= c \\ p^{\ell} &= c n^{-1} \\ \ell &= \log_{p}\left(c n^{-1}\right) \\ \ell &= \log_{p}c + \log_{p}n^{-1} \\ \ell &= \log_{p}c + \log_{1/p}n \in O(\log n) \end{aligned}\]](/wp-content/ql-cache/quicklatex.com-8b3e5c3b2b2b1c5f15e0104f09a82fd5_l3.svg "Rendered by QuickLaTeX.com")