

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we describe how to use the silhouette plot in cluster analysis.
Clustering is one of the unsupervised learning methods. First, we explain what silhouette values measure and how to calculate and interpret them. Then, we show how to determine the number of clusters using the mean silhouette value.
2. Silhouette Plots in Cluster Analysis
A silhouette plot is a graphical tool depicting how well our data points fit into the clusters they’ve been assigned to. We call it the quality of fit cohesion.
At the same time, a silhouette plot shows the quality of separation: this metric conveys the degree to which the points that don’t belong to the same cluster have been assigned to different ones.
To analyze clusters, we need to consider both criteria, which silhouette plots allow us to do.
3. Silhouette Values
A silhouette value is a combination of two scores: cohesion and separation.
3.1. Cohesion
Cohesion measures the similarity of the points in the same cluster. So, we can call it an intra-cluster metric.
Let  be a cluster and
be a cluster and  two points in it. Then, we can interpret the distance between them as a measure of their similarity. From there, we define the cohesion of point
two points in it. Then, we can interpret the distance between them as a measure of their similarity. From there, we define the cohesion of point  in its cluster as the mean distance between and the other points
in its cluster as the mean distance between and the other points  in :
in :
![\[a_i = \mathrm{mean}_{x_j \in C}(distance(x_i, x_j))\]](/wp-content/ql-cache/quicklatex.com-e2320c64aebaa5bd8335fed551c9b90c_l3.svg "Rendered by QuickLaTeX.com")
3.2. Separation
On the other hand, separation refers to the degree to which the clusters don’t overlap. So, it’s an inter-cluster metric.
Intuitively, the distance between the clusters speaks about the “goodness of their separation”. So, we define the separation of  as the minimum mean distance between and other clusters:
as the minimum mean distance between and other clusters:
![\[b_i = \min_{C_2 \neq C_1}(mean_{x_j \in C_2}(distance(x_i, x_j)))\]](/wp-content/ql-cache/quicklatex.com-efa5bdd9f62493d67945a68ab54fa08f_l3.svg "Rendered by QuickLaTeX.com")
3.3. Combining Cohesion and Separation into a Silhouette Value
Then, the silhouette value of a point  is:
is:
![\[s_i = \frac{b_i - a_i}{\max(a_i, b_i)}\]](/wp-content/ql-cache/quicklatex.com-2f87912b6238c74b6f62bc29d868b987_l3.svg "Rendered by QuickLaTeX.com")
Its range is ![[-1, 1]](/wp-content/ql-cache/quicklatex.com-61888feeeeb8e122a17b229740cd3b65_l3.svg "Rendered by QuickLaTeX.com") . The higher the silhouette value, the more certain we can be that its label is correct. So, a high mean silhouette value of all the points indicates a good clustering.
. The higher the silhouette value, the more certain we can be that its label is correct. So, a high mean silhouette value of all the points indicates a good clustering.
3.4. How to Calculate the Silhouette Value?
Let’s take a look at clusters  , and in the following image:
, and in the following image:
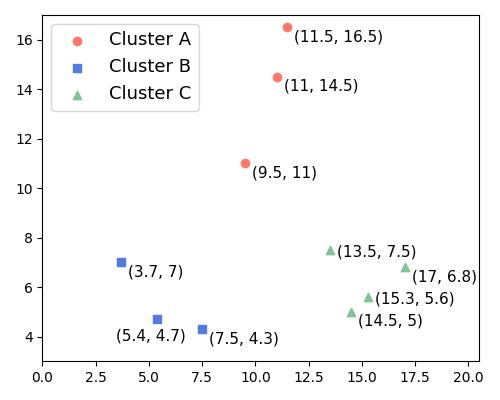
Let’s compute the silhouette value of the point  . To do so, we need to calculate its cohesion and separation scores.
. To do so, we need to calculate its cohesion and separation scores.
The cohesion of point is its mean distance to the other points in  . The distance between the point
. The distance between the point  and point
and point  is:
is:
![\[\sqrt{(9.5-11)^2 + (15.5-14.5)^2} = \sqrt{2.25 + 1} = \sqrt{3.25} \approx 1.8\]](/wp-content/ql-cache/quicklatex.com-4aca84629fef338906a58eccb6be1882_l3.svg "Rendered by QuickLaTeX.com")
and the distance to  is:
is:
![\[\sqrt{(9.5-11.5)^2 + (15.5-16.5)^2} = \sqrt{4.0 + 1.0} = \sqrt{5.0} \approx 2.2\]](/wp-content/ql-cache/quicklatex.com-35894aea151ac635090177ba7e8d74fb_l3.svg "Rendered by QuickLaTeX.com")
So, the cohesion of point is:
![\[cohesion_{(9.5, 11)} = \frac{1.8 + 2.2}{2} = 2\]](/wp-content/ql-cache/quicklatex.com-8e889a8540b029a20d2b20fd39a1bb65_l3.svg "Rendered by QuickLaTeX.com")
We can compute the mean distance of the point to cluster  in the same way:
in the same way:
![\[\begin{aligned} dist_{( (9.5, 15.5), (7.5, 4.3) )} &= \sqrt{(9.5-7.5)^2 + (15.5-4.3)^2} = \sqrt{4.0 + 125.0} = \sqrt{129.4} \approx 11.4 \\ dist_{( (9.5, 15.5), (3.7, 7) )} &= \sqrt{(9.5-3.7)^2 + (15.5-7)^2} = \sqrt{33.64 + 72.25} = \sqrt{105.89} \approx 10.3 \\ dist_{( (9.5, 15.5), (5.4, 4.7) )} &= \sqrt{(9.5-5.4)^2 + (15.5-4.7)^2} = \sqrt{16.8 + 116.6} = \sqrt{133.1} \approx 11.5 \\ mean\_distance &= \frac{11.4 + 10.3 + 11.5}{3} \approx 11 \end{aligned}\]](/wp-content/ql-cache/quicklatex.com-8b358038b61f69291a8d85f3d7851052_l3.svg "Rendered by QuickLaTeX.com")
Following the same steps, we compute its mean distance to cluster :
![\[separation_{(9.5, 11), C} = \frac{8.9 + 11.5 + 11.6 + 11.5}{4} \approx 10.9\]](/wp-content/ql-cache/quicklatex.com-18d7012b34d76069d6770bad8ed2297a_l3.svg "Rendered by QuickLaTeX.com")
Therefore, the separation score of is  , since that’s the lower of the two values.
, since that’s the lower of the two values.
From there, we get the silhouette value of :
![\[s_i = \frac{b_i - a_i}{\max(a_i, b_i)} = \frac{10.9 - 2}{max(10.9, 2)} = \frac{8.9}{10.9} \approx 0.8\]](/wp-content/ql-cache/quicklatex.com-7ffc8b0ca47f6a486312a02ebabafcb1_l3.svg "Rendered by QuickLaTeX.com")
Since  is close to the theoretically maximal silhouette value, we can be confident that we assigned to the cluster it actually belongs to.
is close to the theoretically maximal silhouette value, we can be confident that we assigned to the cluster it actually belongs to.
3.5. Analyzing the Silhouette Values
Let’s say that we have two clusters: and , such that is the cluster closest to . We’re calculating the silhouette values of the points in . The silhouette value  of any point in will be closer to 1 when
of any point in will be closer to 1 when  . In that case, the distance between and the other points in is much smaller than the distance to points in . This indicates that belongs to cluster :
. In that case, the distance between and the other points in is much smaller than the distance to points in . This indicates that belongs to cluster :
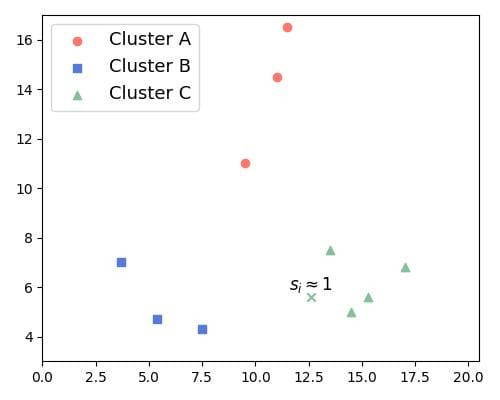
Therefore, as the average of the silhouette values of the points in a cluster gets closer to 1, the cohesion and separation of the cluster as a whole increase.
The converse is also true. When the silhouette value is closer to zero, both  and
and  are similar. Then, the distances between and the elements on and are similar. Thus, it is not clear if should belong to or :
are similar. Then, the distances between and the elements on and are similar. Thus, it is not clear if should belong to or :
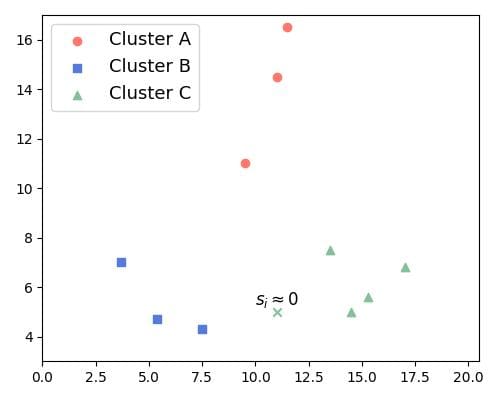
The worst case occurs when the silhouette value is negative, which happens when is greater than . Then, the point in question lies closer to than to . So, it looks misclassified:
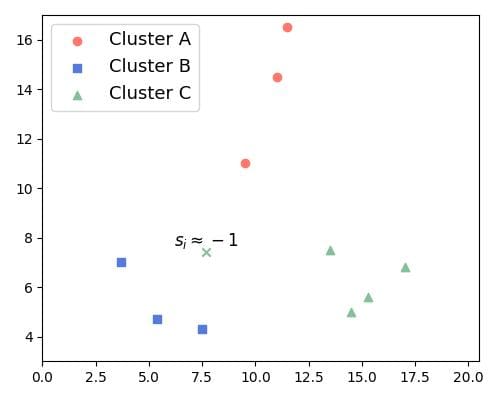
Hence, as the  values decrease, the quality of separation deteriorates, and the quality of the clustering gets worse.
values decrease, the quality of separation deteriorates, and the quality of the clustering gets worse.
4. Silhouette Plots
The silhouette of a cluster visualizes the silhouette values of all the points in it in the decreasing order. A silhouette plot shows the silhouettes of all the clusters in random order. Additionally, it inserts blank spaces between consecutive clusters and can color them differently.
For example, here’s a plot for four clusters we got with the K-Means clustering algorithm on an ad-hoc two-dimensional dataset:
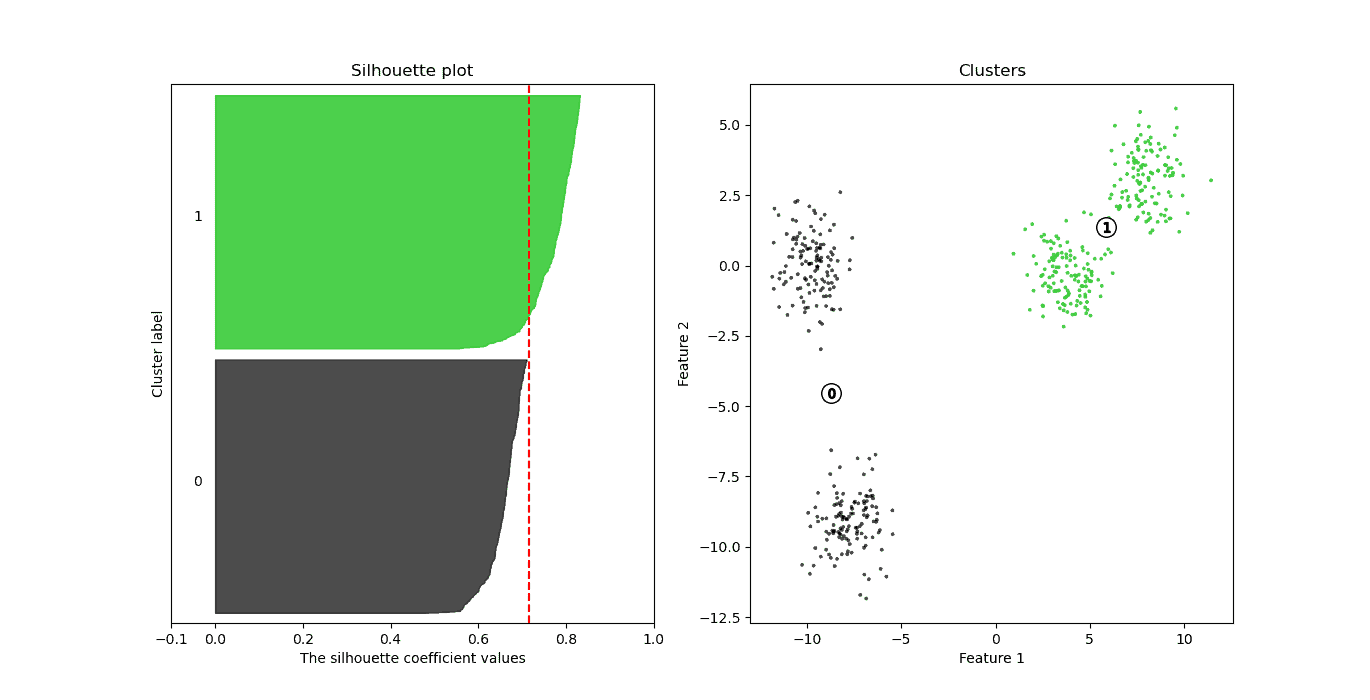
Here, we set  . On the left, we have the silhouette plot. The -axis shows the silhouette values, and the height of each silhouette indicates the number of points in the corresponding cluster. The right subplot visualizes the data points with the same colors as the clusters. The red line shows the average silhouette value for all the clusters. In this example, the average value is 0.71.
. On the left, we have the silhouette plot. The -axis shows the silhouette values, and the height of each silhouette indicates the number of points in the corresponding cluster. The right subplot visualizes the data points with the same colors as the clusters. The red line shows the average silhouette value for all the clusters. In this example, the average value is 0.71.
From the right subplot, we conclude that the cohesion of the green points is higher than that of the black ones. This should explain the worse silhouette of the black cluster on the left. However, the two clusters look well separated.
5. Choosing the Number of Clusters
By plotting the silhouettes for different values of  , we can see which best fits the data.
, we can see which best fits the data.
For instance, the following graphic shows the K-Means results for the above data and  . The average silhouette value increases to 0.78:
. The average silhouette value increases to 0.78:
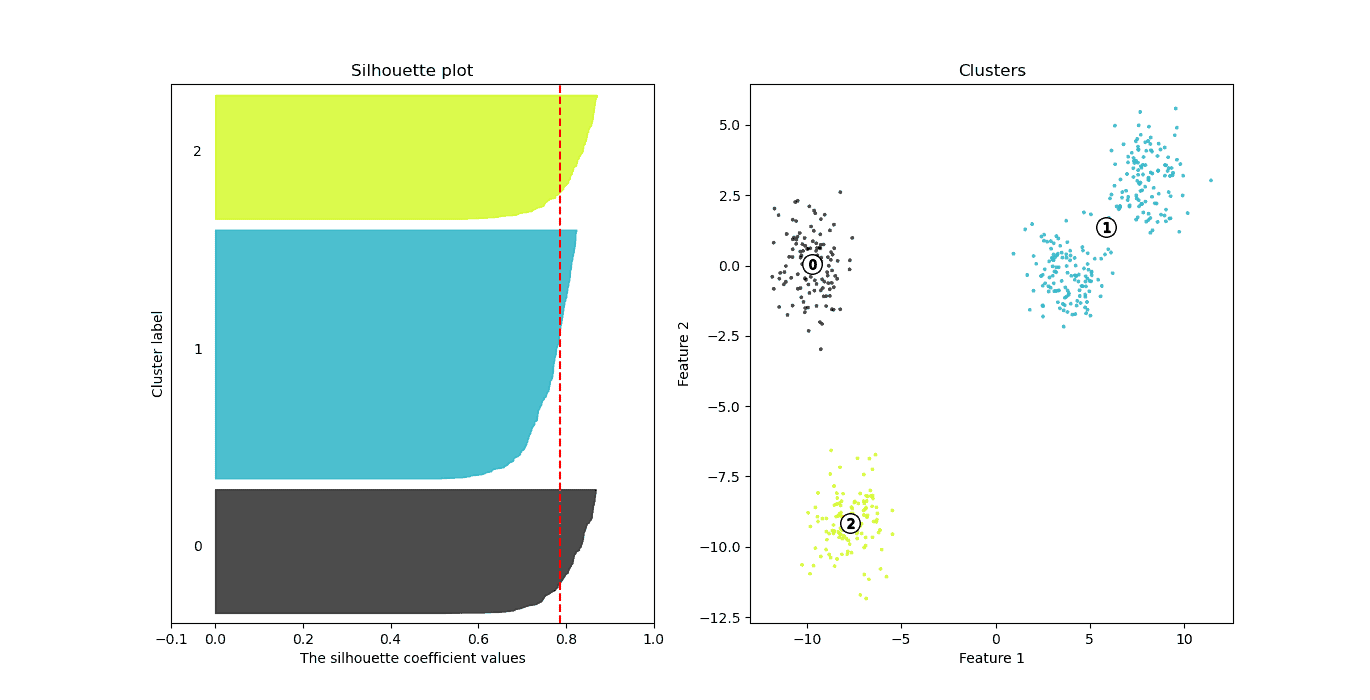
Here, we see that the right cluster remains intact, while the left one splits into two smaller ones. These two clusters have better silhouette values than the ones obtained by the blue cluster, but all three appear to be well defined.
What happens if we use  ? The average silhouette value drops slightly to 0.74:
? The average silhouette value drops slightly to 0.74:
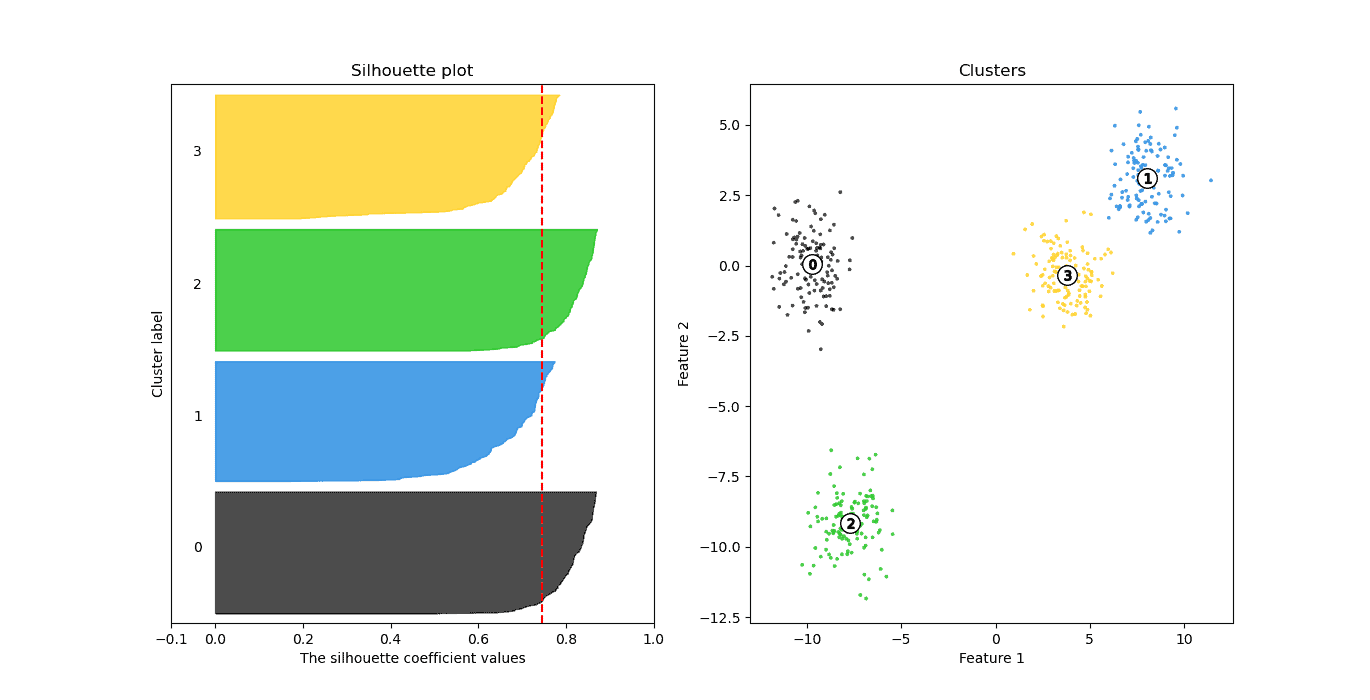
Here, we see that the green and black clusters have better silhouettes than the other two. It’s probably because their points are better separated than the points of the other two clusters.
Finally, the average silhouette values for  drops to 0.66 and 0.53:
drops to 0.66 and 0.53:
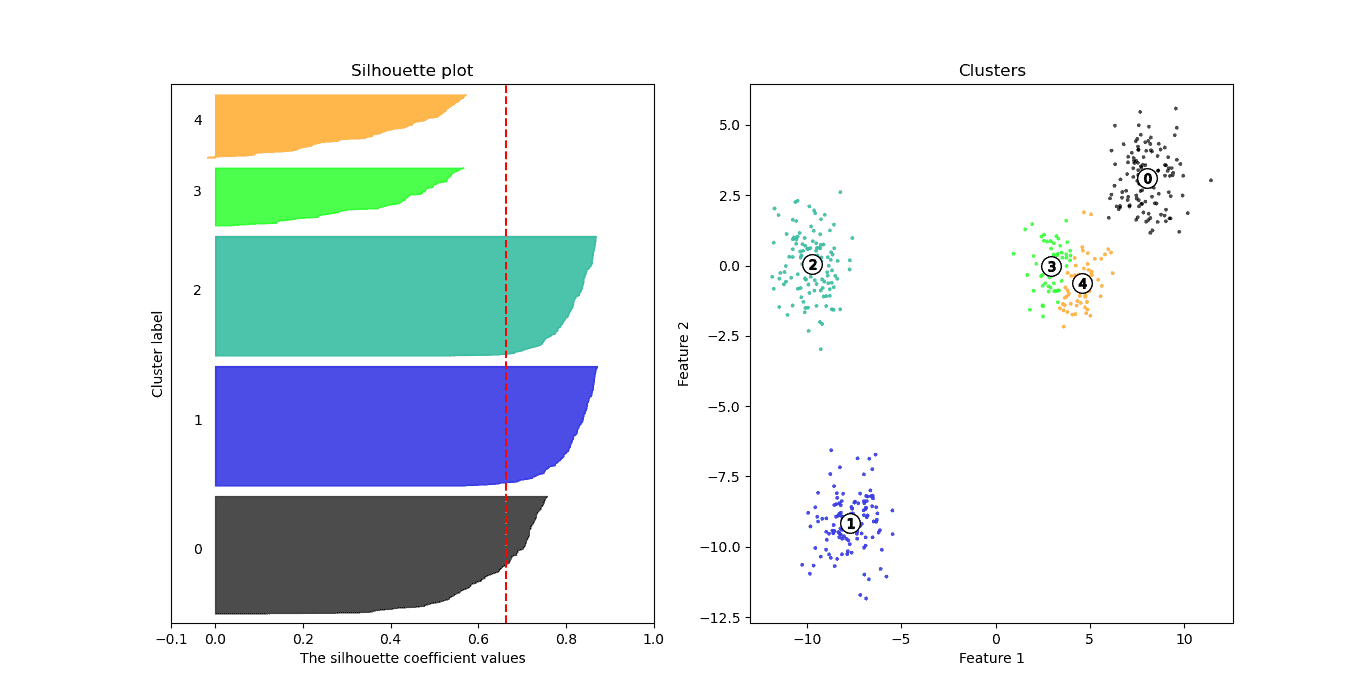
and for  to 0.53:
to 0.53:
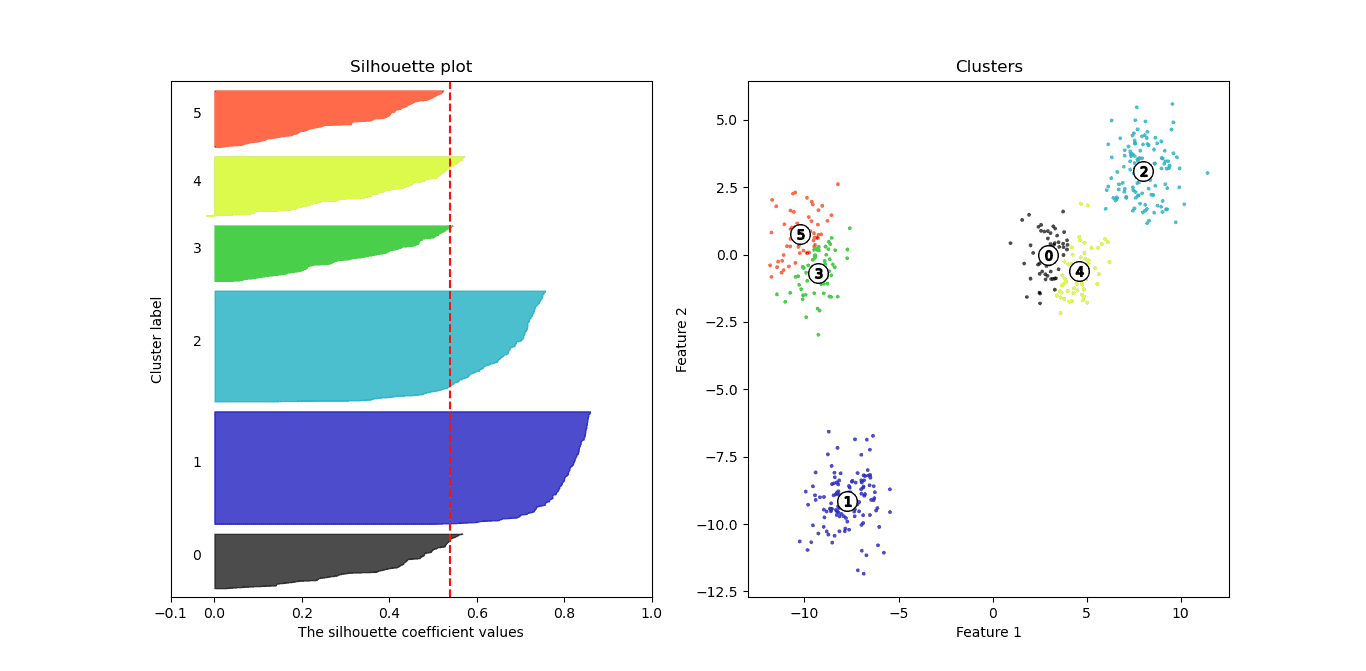
So,  appear to be good choices, whereas and give lower-quality clusters.
appear to be good choices, whereas and give lower-quality clusters.
5.1. Interpreting the Mean of Silhouette Values
Silhouette values measure the relation between cluster cohesion and cluster separation. Thus, the mean of the silhouette values represents the balance of the overall cohesion and separation in all the clusters.
As we concluded previously, the cohesion and separation of clusters are better when the silhouette values are close to 1. Therefore, we’re looking for the clustering with a higher mean silhouette value, ideally close to 1.
One way to select the number of clusters could be to choose the one with the higher overall mean. Kaufmann and Rousseeuw (1990) named the overall mean the silhouette coefficient (SC). By their classification, if  > 0.70, the structure of the clusters is strong. If is between 0.51 and 0.70 the structure is reasonable. Lower values indicate poor structure.
> 0.70, the structure of the clusters is strong. If is between 0.51 and 0.70 the structure is reasonable. Lower values indicate poor structure.
Here are the mean values for  we got in the above example:
we got in the above example:
| k | Silhouette score |
|---|---|
| 2 | 0.7143 |
| 3 | 0.7866 |
| 4 | 0.7456 |
| 5 | 0.6633 |
| 6 | 0.5392 |
Considering the  criterion, acceptable solutions are those with 2, 3, and 4 clusters. In this particular simulation, we used the data from four blobs, so the best solution should be the one with 4 clusters. But, we can see that the solution with 3 clusters looks even better.
criterion, acceptable solutions are those with 2, 3, and 4 clusters. In this particular simulation, we used the data from four blobs, so the best solution should be the one with 4 clusters. But, we can see that the solution with 3 clusters looks even better.
6. Conclusion
In this tutorial, we talked about silhouette plots and values. A silhouette plot is a graphical tool we use to evaluate the quality of clusters. The silhouette values show the degree of cohesion and separation of the clusters. The mean of the silhouette values allows identifying how many clusters appear in the dataset.