

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss Large Language Models (LLMs), the force behind several innovations in artificial intelligence recently. This will cover the fundamental concepts behind LLMs, the general architecture of LLMs, and some of the popular LLMs available today.
Historically, computers were only expected to understand a definite set of instructions, often written in a programming language like Java. However, as the usage of computers became widespread, it was expected to understand commands in natural languages, like English.
Natural Language Processing (NLP), is an interdisciplinary subfield of linguistics, computer science, and artificial intelligence. Its goal is for a computer to be able to understand texts and other media in their natural languages, including their contextual nuances.
The fundamental beginnings of NLP can be traced back to the 1950s when Alan Turing published his paper proposing the Turing test as a criterion of intelligence. However, for many decades, NLP was limited to emulating natural language understanding based on a collection of rules.
Starting in the 1980s, with the growth of computational power and the introduction of machine learning algorithms for language processing, statistical NLP started to take shape. It started with machine translation using supervised learning algorithms.
But the focus soon diverged towards semi-supervised and unsupervised learning algorithms to process increasing amounts of raw language data generated on the Internet. One of the key instruments of NLP applications is language modeling.
Language modeling (LM) uses statistical and probabilistic techniques to determine the probability of a given sequence of words occurring in a sentence. Hence, a language model is basically a probability distribution over sequences of words:

Here, the expression computes the conditional probability distribution where  can be any word in the vocabulary.
can be any word in the vocabulary.
Language models generate probabilities by learning from one or more text corpus. A text corpus is a language resource consisting of a large and structured set of texts in one or more languages. Text corpus can contain text in one or multiple languages and is often annotated.
One of the earliest approaches for building a language model is based on the n-gram. An n-gram is a contiguous sequence of n items from a given text sample. Here, the model assumes that the probability of the next word in a sequence depends only on a fixed-size window of previous words:
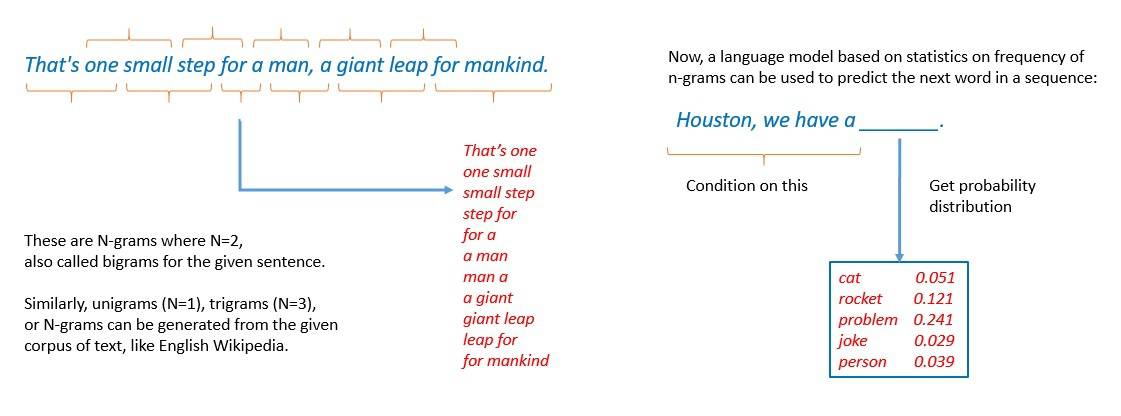
However, n-gram language models have been largely superseded by neural language models. It’s based on neural networks, a computing system inspired by biological neural networks. These models make use of continuous representations or embeddings of words to make their predictions:
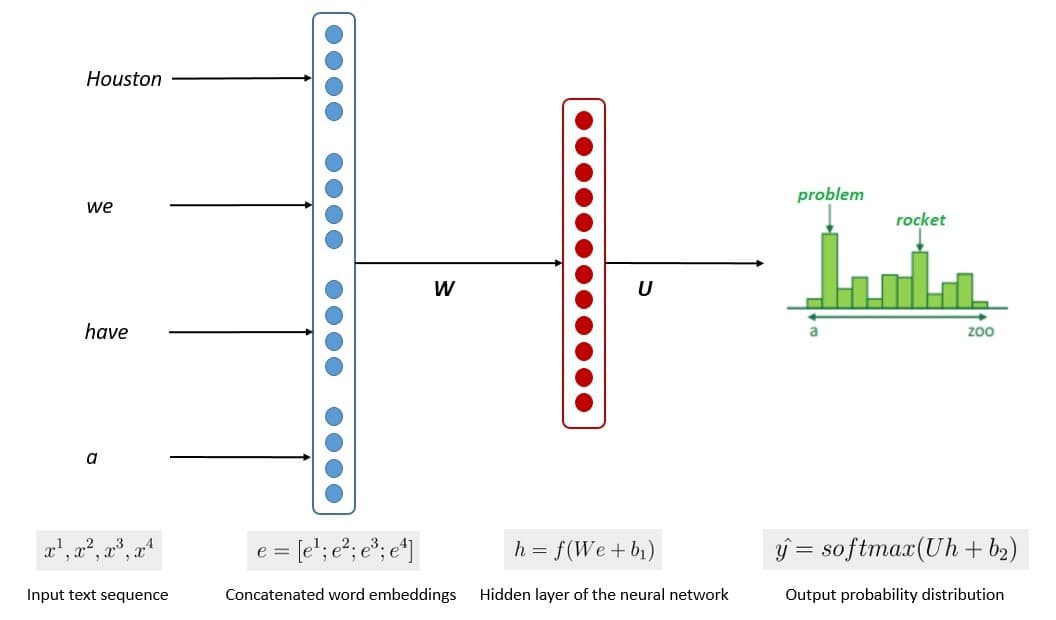
Basically, neural networks represent words distributedly as a non-linear combination of weights. Hence, it can avoid the curse of dimensionality in language modeling. There have been several neural network architectures proposed for language modeling.
Large Language Models (LLMs) are basically neural language models working at a larger scale. A large language model consists of a neural network with possibly billions of parameters. Moreover, it’s typically trained on vast quantities of unlabeled text, possibly running into hundreds of billions of words.
Large language models also called deep learning models, are usually general-purpose models that excel at a wide range of tasks. They are generally trained on relatively simple tasks, like predicting the next word in a sentence.
However, due to sufficient training on a large set of data and an enormous parameter count, these models can capture much of the syntax and semantics of the human language. Hence, they become capable of finer skills over a wide range of tasks in computational linguistics.
This is quite a departure from the earlier approach in NLP applications, where specialized language models were trained to perform specific tasks. On the contrary, researchers have observed many emergent abilities in the LLMs, abilities that they were never trained for.
For instance, LLMs have been shown to perform multi-step arithmetic, unscramble a word’s letters, and identify offensive content in spoken languages. Recently, ChatGPT, a popular chatbot built on top of OpenAPI’s GPT family of LLMs, has cleared professional exams like the US Medical Licensing Exam!
A foundation model generally refers to any model trained on broad data that can be adapted to a wide range of downstream tasks. These models are typically created using deep neural networks and trained using self-supervised learning on many unlabeled data.
The term was coined not long back by the Stanford Institute for Human-Centered Artificial Intelligence (HAI). However, there is no clear distinction between what we call a foundation model and what qualifies as a large language model (LLM).
Nevertheless, LLMs are typically trained on language-related data like text. But a foundation model is usually trained on multimodal data, a mix of text, images, audio, etc. More importantly, a foundation model is intended to serve as the basis or foundation for more specific tasks:
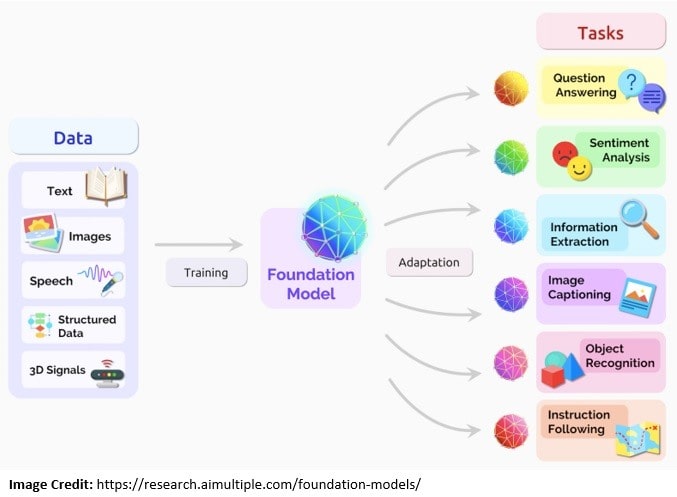
Foundation models are typically fine-tuned with further training for various downstream cognitive tasks. Fine-tuning refers to the process of taking a pre-trained language model and training it for a different but related task using specific data. The process is also known as transfer learning.
Most of the early LLMs were created using RNN models with LSTMs and GRUs, which we discussed earlier. However, they faced challenges, mainly in performing NLP tasks at massive scales. But, this is precisely where LLMs were expected to perform. This led to the creation of Transformers!
When it started, LLMs were largely created using self-supervised learning algorithms. Self-supervised learning refers to the processing of unlabeled data to obtain useful representations that can help with downstream learning tasks.
Quite often, self-supervised learning algorithms use a model based on an artificial neural network (ANN). We can create ANN using several architectures, but the most widely used architecture for LLMs were the recurrent neural network (RNN):
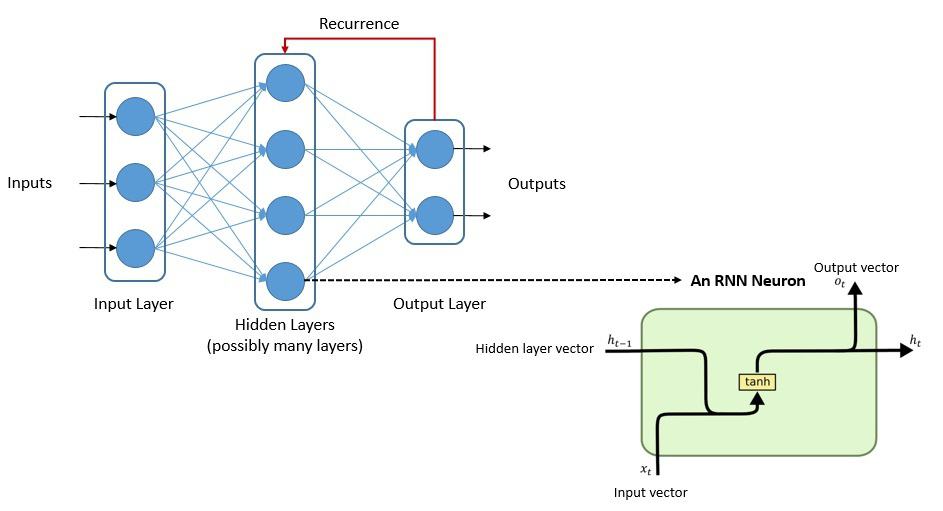
Now, RNNs can use their internal state to process variable-length sequences of inputs. An RNN has both long-term memory and short-term memory. There are variants of RNN like Long-short Term Memory (LSTM) and Gated Recurrent Units (GRU).
The LSTM architecture helps an RNN when to remember and when to forget important information. The GRU architecture is less complex, requires less memory to train, and executes faster than LSTM. But GRU is generally more suitable for smaller datasets.
As we’ve seen earlier, LSTMs were introduced to bring memory into RNN. But an RNN that uses LSTM units is very slow to train. Moreover, we need to feed the data sequentially or serially for such architectures. This does not allow us to parallelize and use available processor cores.
Alternatively, an RNN model with GRU trains faster but performs poorly on larger datasets. Nevertheless, for a long time, LSTMs and GRUs remained the preferred choice for building complex NLP systems. However, such models also suffer from the vanishing gradient problem:
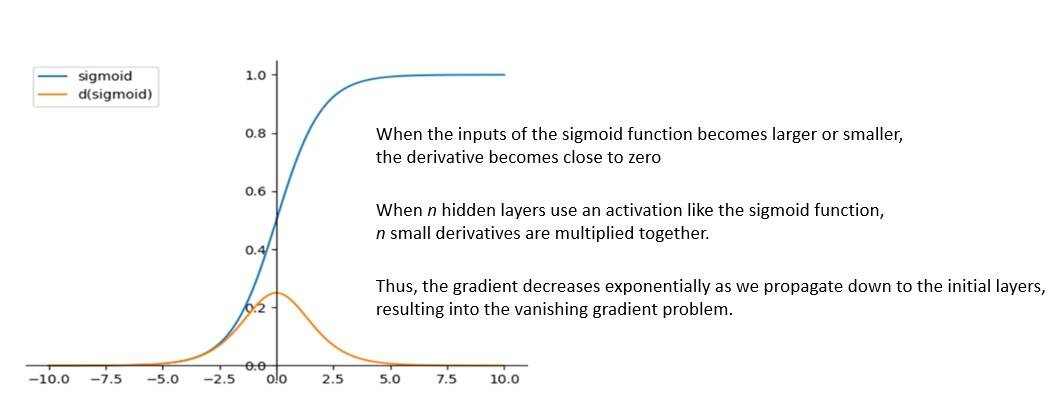
The vanishing gradient problem is encountered in ANN using gradient-based learning methods with backpropagation. In such methods, during each iteration of training, the weights receive an update proportional to the partial derivative of the error function concerning the current weight.
In some cases, like recurrent networks, the gradient becomes vanishingly small. This effectively prevents the weights from changing their value. This may even prevent the neural network from training further. These issues make the training of RNNs for NLP tasks practically inefficient.
Some of the problems with RNNs were partly addressed by adding the attention mechanism to their architecture. In recurrent architectures like LSTM, the amount of information that can be propagated is limited, and the window of retained information is shorter.
However, with the attention mechanism, this information window can be significantly increased. Attention is a technique to enhance some parts of the input data while diminishing other parts. The motivation behind this is that the network should devote more focus to the important parts of the data:
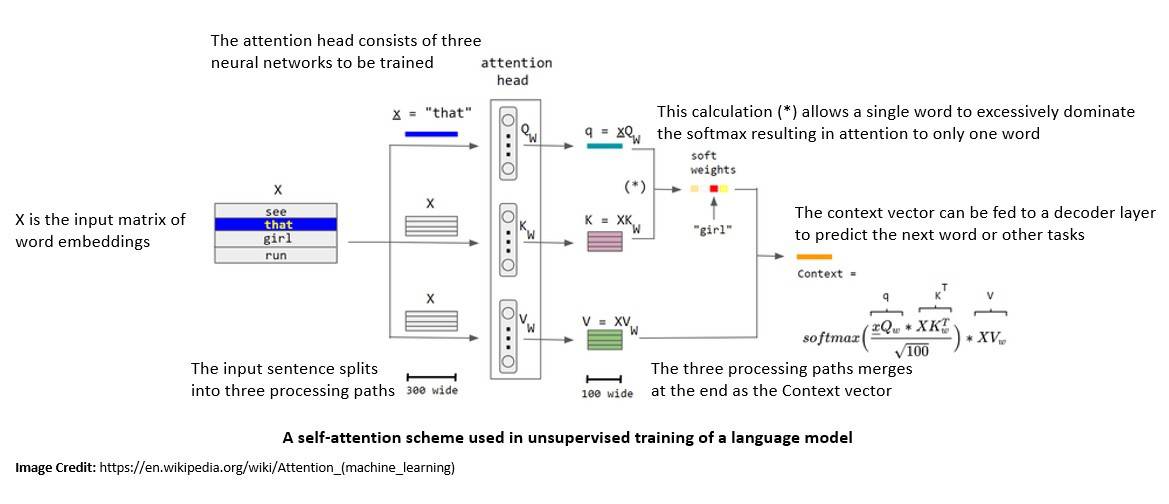
There is a subtle difference between attention and self-attention, but their motivation remains the same. While the attention mechanism refers to the ability to attend to different parts of another sequence, self-attention refers to the ability to attend to different parts of the current sequence.
Self-attention allows the model to access information from any input sequence element. In NLP applications, this provides relevant information about far-away tokens. Hence, the model can capture dependencies across the entire sequence without requiring fixed or sliding windows.
In NLP applications, how we represent the words or tokens appearing in a natural language is important. In LLM models, the input text is parsed into tokens, and each token is converted using a word embedding into a real-valued vector.
Word embedding is capable of capturing the meaning of the word in such a way that words that are closer in the vector space are expected to be similar in meaning. Further advances in word embedding also allow them to capture multiple meanings per word in different vectors:

Word embeddings come in different styles, one of which is where the words are expressed as vectors of linguistic contexts in which the word occurs. Further, there are several approaches for generating word embeddings, of which the most popular one relies on neural network architecture.
In 2013, a team at Google published word2vec, a word embedding toolkit that uses a neural network model to learn word associations from a large corpus of text. Word and phrase embeddings have been shown to boost the performance of NLP tasks like syntactic parsing and sentiment analysis
The RNN models with attention mechanisms saw significant improvement in their performance. However, recurrent models are, by their nature, difficult to scale. But, the self-attention mechanism soon proved to be quite powerful, so much so that it did not even require recurrent sequential processing!
The introduction of transformers by the Google Brain team in 2017 is perhaps one of the most important inflection points in the history of LLMs. A transformer is a deep learning model that adopts the self-attention mechanism and processes the entire input all at once:
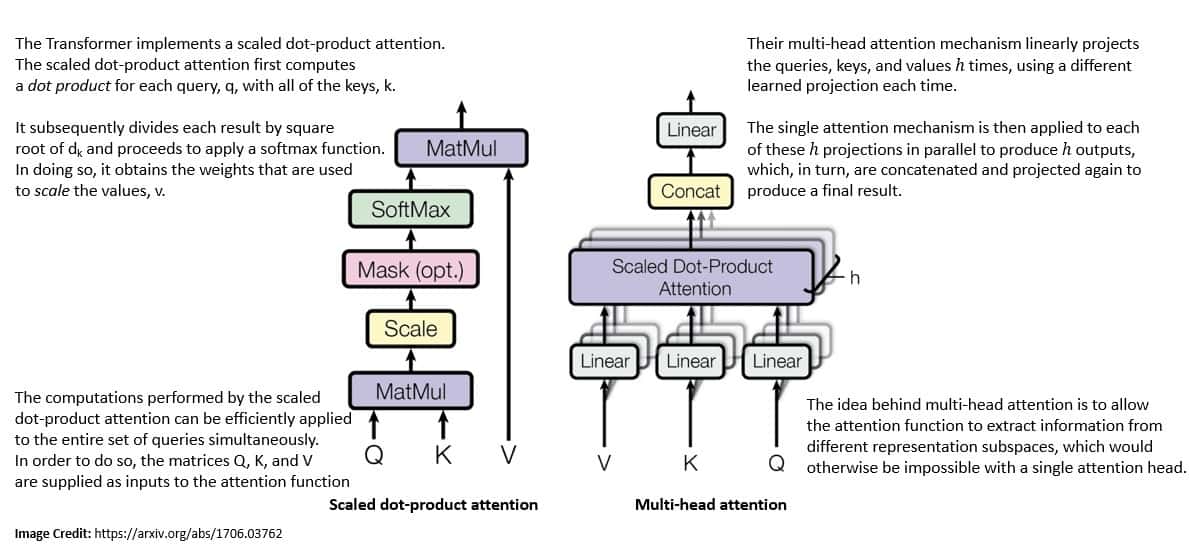
As a significant change to the earlier RNN-based models, transformers do not have a recurrent structure. With sufficient training data, the attention mechanism in the transformer architecture alone can match the performance of an RNN model with attention.
Another significant advantage of using the transformer model is that they are more parallelizable and require significantly less training time. This is exactly the sweet spot we require to build LLMs on a large corpus of text-based data with available resources.
Many ANN-based models for natural language processing are built using encoder-decoder architecture. For instance, seq2seq is a family of algorithms originally developed by Google. It turns one sequence into another sequence by using RNN with LSTM or GRU.
The original transformer model also used the encoder-decoder architecture. The encoder consists of encoding layers that process the input iteratively, one layer after another. The decoder consists of decoding layers that do the same thing to the encoder’s output:
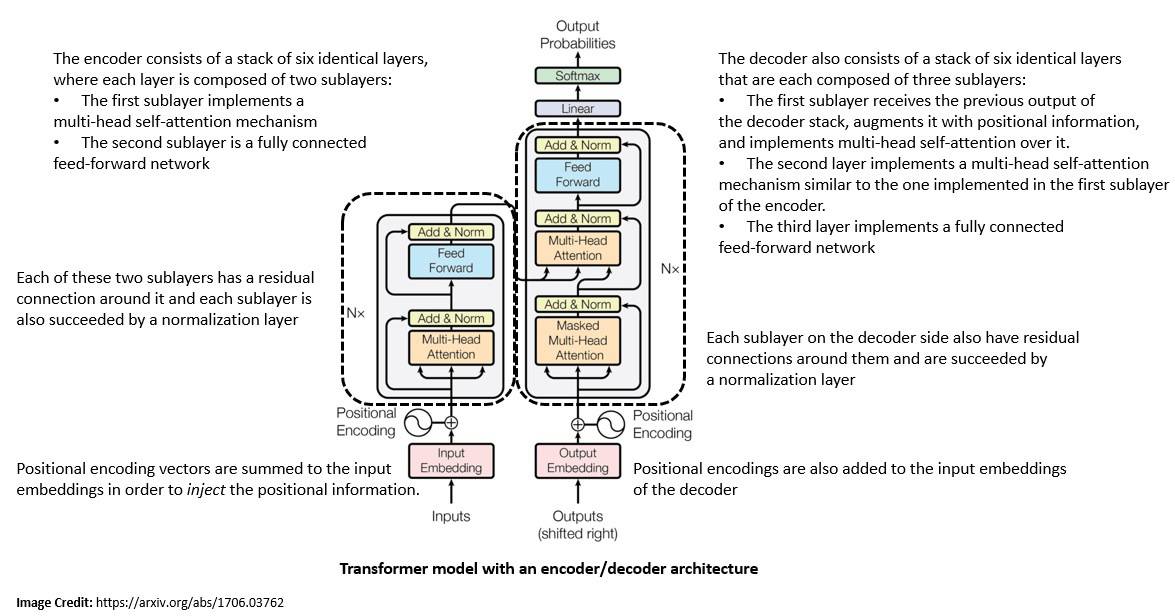
The function of each encoder layer is to generate encodings that contain information about which parts of the input are relevant to each other. The output encodings are then passed to the next encoder as its input. Each encoder consists of a self-attention mechanism and a feed-forward neural network.
Further, each decoder layer takes all the encodings and uses their incorporated contextual information to generate an output sequence. Like encoders, each decoder consists of a self-attention mechanism, an attention mechanism over the encodings, and a feed-forward neural network.
As we’ve seen earlier, foundation models or LLMs are generally trained on a large corpus of data with simple and generic tasks. Now, to apply an LLM for a specific NLP task, we’ve to use one of the application techniques like fine-tuning, prompting, or instructor tuning.
Fine-tuning is an approach to transfer learning in which weights of a pre-trained model are further trained on new data. Transfer learning refers to the practice of applying knowledge gained while solving one task to a related task.
Fine-tuning can be done on the entire neural network or only a subset of its layers. Generally, it involves introducing a new set of weights connecting the language model’s final layer to the downstream task’s output. The original weights of the language model are kept frozen:
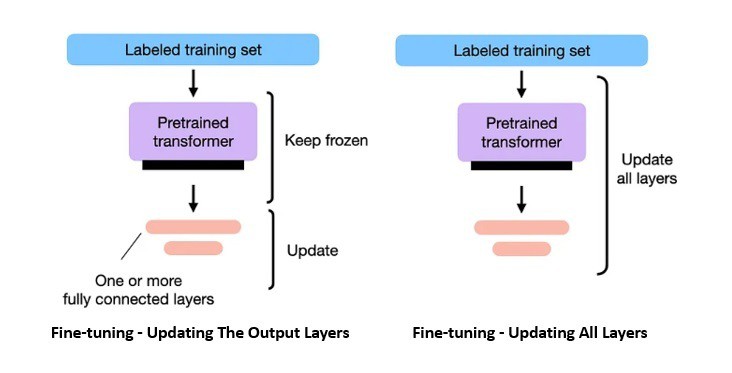
Fine-tuning is generally accomplished using supervised learning with a much smaller set of labeled data pertinent to the task. Other approaches are often used for fine-tuning, like learning under weak supervision and reinforcement learning.
Fine-tuning was the most popular application technique for LLMs to harness them for downstream NLP tasks like sentiment analysis, named-entity recognition, and part-of-speech tagging. However, as LLMs started to grow bigger, simpler techniques like prompting started to become more popular.
Since the arrival of large-scale LLMs like GPT-3, prompting has become a simpler and more popular approach to leveraging LLMs for specific tasks. In this approach, the problem to be solved is presented to the model as a text prompt that the model must solve by providing a completion.
This paradigm of harnessing the capabilities of LLMs is also called prompt engineering. It generally works by converting one or more tasks to a prompt-based dataset and training a language model with prompt-based learning:
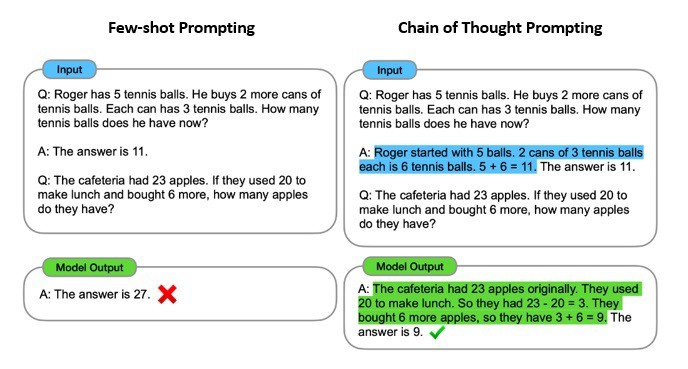
Few-shot prompting is a prompting technique that allows a model to process examples before attempting a task. It includes certain examples of problem and solution pairs, known as shots. This is also known as in-context learning and was originally proposed as an alternative to fine-tuning.
A common example of in-context learning is chain-of-thought prompting. Here, few-shot examples are given to the model to output a string of reasoning before attempting to answer a question. It helps to improve the performance of models in tasks that require logical thinking and reasoning.
Instructor tuning is a form of fine-tuning that facilitates more natural and accurate zero-shot prompting interactions. Here, the language model is trained on many examples of tasks formulated as natural language instructions and appropriate responses.
There are various techniques of instructor tuning, for instance, reinforcement learning from human feedback (RLHF) used by popular models like ChatGPT and Sparrow. It involves supervised fine-tuning on a dataset of human-generated prompt and response pairs:
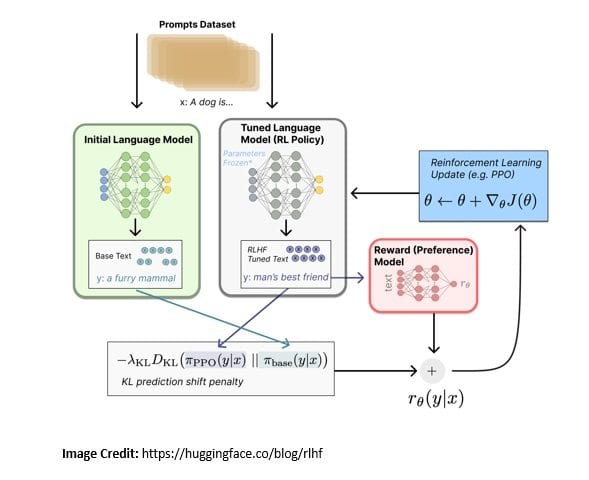
In RLHF, a reward function is learned based on a dataset of human preferences. Further, the reward function is used to optimize the agent’s policy using reinforcement learning through an optimization algorithm. The human feedback is collected by asking humans to rank instances of the agent’s behavior.
One of the key challenges of RLHF is the scalability and cost of human feedback. Hence, this approach can be slow and expensive compared to unsupervised learning. Moreover, human feedback can vary depending on the task and the individual preferences of humans.
Like many other AI-based technologies, LLMs have recently attracted quite a public imagination. However, today’s LLMs have been based on years of research on neural network models, advances in computing power, and an unprecedented scale of available data. While we’re finding interesting and practical applications of LLMs, they continue to face some limitations and challenges.
LLMs remain an active area of research and development. But owing to the massive amount of resources required in developing and training an LLM, it’s mostly pursued by large organizations. However, the launch of ChatGPT by OpenAI has flagged off a race!
Google has been at the forefront of this research with LLMs like the Bidirectional Encoder Representations from Transformers (BERT) released in 2018, and the Language Model for Dialogue Applications (LaMDA) released in 2021:
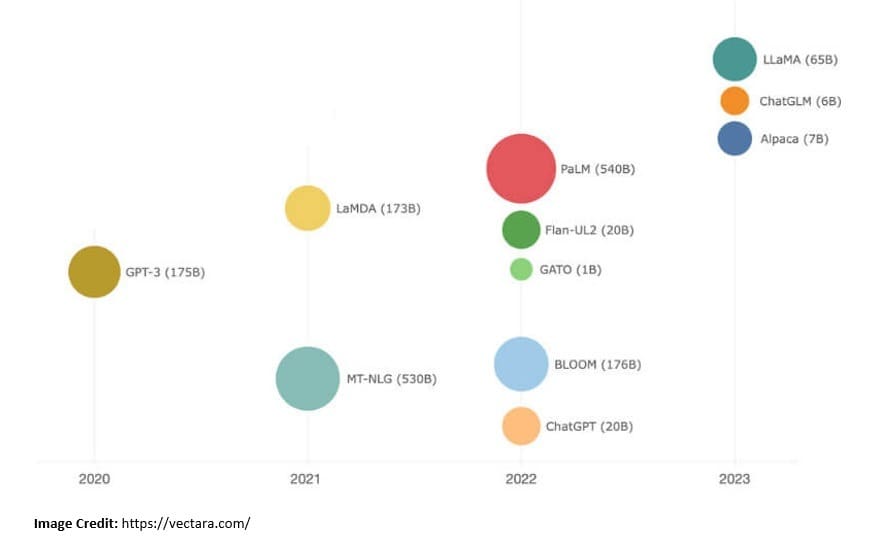
OpenAI is another organization leading in AI research with LLMs like the Generative Pre-trained Transformers (GPT) released in 2018. It further released GPT-2 in 2019, GPT-3 in 2020, and GPT-4 in 2023. In 2022, it released ChatGPT, an AI chatbot built on top of GPT-3.5 and GPT-4y.
Other prominent LLMs include the BigScience Large Open-science Open-access Multilingual (BLOOM) by HuggingFace released in 2023, the Chinchilla AI by DeepMind released in 2022, and the Large Language Model Meta AI (LLaMA) by Meta AI released in 2023.
There are quite diverse applications for LLMs that we can imagine today. One of the broad use cases for LLMs is generative. Here, the primary goal is to generate content based on one or more prompts from a user. There are several generative applications of LLMs that we can think of. For instance, conversational chatbots, code assistants, and even artistic inspiration!
Another key use case for LLMs is in the field of search. LLMs have the power to disrupt the traditional search offerings that are based on keyword-based algorithms. Search techniques based on LLMs can better understand language and find more relevant results. Further, search engines are extending to question answering by daisy-chaining multiple LLMs together.
Other possible use cases for LLMs include abstractive summarization, machine translation, clustering & classification of documents, speech recognition, and optical character recognition. Of course, this is far from a complete list of possible applications of LLMs. This list is potentially endless and is bound to refine in the days as LLMs become bigger and better!
Researchers have made significant progress in developing LLMs in the past decades, especially since the introduction of transformers. However, there are still several challenges. First and foremost, the cost of creating an LLM remains quite high. A typical LLM has billions and parameters and is trained on trillions of tokens today. It’s very expensive to train and operate these models.
LLMs are typically trained on a broad data set, possibly at the web scale. This is often too generic and possibly misses the domain-specific knowledge. Hence, users can find the output of LLMs impersonal for search or generative tasks. At the same time, it remains a challenge to eliminate bias and control offensive or nonsensical output from LLMs.
Also, it’s important to understand that LLMs can not potentially do everything, at least now! LLMs generally do not have a notion of time and are not grounded in the spatial sense. Hence, it’s difficult for LLMs to perform tasks that require temporal or spatial reasoning. Moreover, LLMs are also not very good in terms of mathematical reasoning. However, LLMs are becoming better every day!
In this tutorial, we discussed the language models and LLMs. We reviewed the basic concepts and building blocks behind creating an LLM. Further, we discussed the prevalent architecture for creating LLMs and some of the popular LLMs available today.