

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Part-of-Speech Tagging With Hidden Markov Model
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
Part-of-speech (POS) tagging is a core task in natural language processing (NLP), and notably, Hidden Markov Models (HMMs) play a crucial role in it.
In this tutorial, we’ll show how to use HMMs for POS tagging. Starting with the basics of POS, we’ll transition to the mechanics of HMMs and explore their advantages, challenges, and practical applications in tagging.
2. Basics of POS Tagging
In this section, we’ll present the definition of POS and provide an illustrative example.
2.1. Definition of POS Tagging
POS tagging refers to marking each word in a text with its corresponding POS.
Doing this, we identify a word as a noun, verb, adjective, adverb, or another category.
We use this information to analyze the grammatical structure of sentences, which aids in understanding the meaning and context of words in various scenarios.
So, efficient and accurate POS tagging can improve the solutions to various other NLP tasks, such as text analysis, machine translation, and information retrieval.
2.2. Example of POS Tagging
For the input sentence “I like to read books,” a potential output of POS tagging would be as follows:
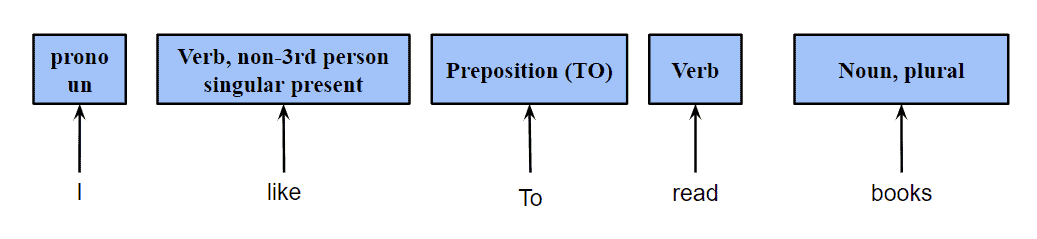
We assigned each word a category it belongs to. However, POS models usually have more nuanced tags. For example, IBM’s model uses  for the base form of a verb,
for the base form of a verb,  for the present tense, third person singular, and
for the present tense, third person singular, and  for all the other forms of the present tense.
for all the other forms of the present tense.
So, the exact POS tags differ depending on the specific POS tagging system or model.
3. Introduction to HMM
Historically, HMMs have paved the way for significant advancements in various fields, showcasing their vast relevance. The components of HMMs are states, observations, transition probabilities, and emission probabilities.
To apply an HMM to a sequence of observations, we need to determine the likelihood of the input sequence and find the most probable sequence of (hidden) states that can generate it.
4. How Do HMMs Work for POS?
Firstly, we treat POS tags as the hidden states and individual words as the observations. By doing so, we aim to predict the grammatical role of each word based on its context within a sentence. Transition probabilities represent the likelihood of one POS tag following another, while emission probabilities gauge the likelihood of a word emitted from a given POS tag.
Now, here’s where it gets interesting. We estimate both the transition and emission probabilities directly from a provided corpus.
This means we analyze large volumes of text to find how likely a particular word follows another and estimate the likelihood of a word being tagged with a specific POS.
The Viterbi algorithm aids us in pinpointing the most probable sequence of tags for any sequence of words.
4.1. Example
We’ll use the sentence “Although it rained, we went to the park.” as an example.
Beginning with  , our HMM might first predict that this word is a subordinating conjunction (
, our HMM might first predict that this word is a subordinating conjunction ( ) based on its emission probability. Subsequently, for
) based on its emission probability. Subsequently, for  , the model evaluates the transition probability from a subordinating conjunction to a pronoun (
, the model evaluates the transition probability from a subordinating conjunction to a pronoun ( ) and couples it with the emission probability of being a . This calculation yields a specific probability value for this sequence. Moving to the word
) and couples it with the emission probability of being a . This calculation yields a specific probability value for this sequence. Moving to the word  , the transition from to a verb (
, the transition from to a verb ( ) is considered along with the emission probability of being a VBD:
) is considered along with the emission probability of being a VBD:
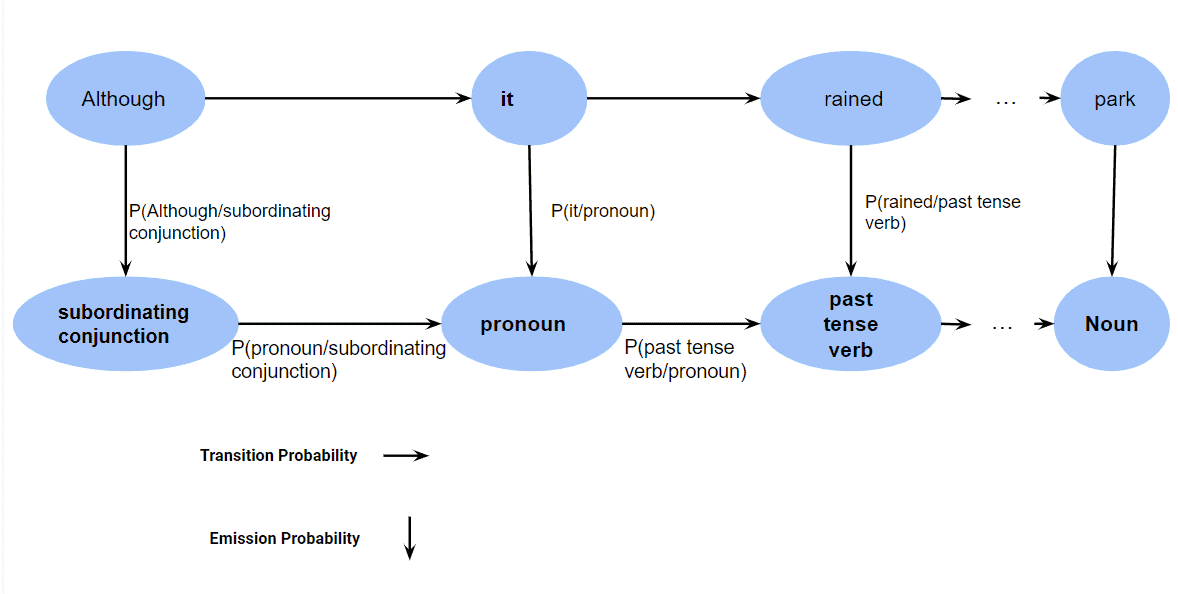
The model obtains a cumulative likelihood for the sequence ![[SC, PRP, VBD, \ldots, Noun]](/wp-content/ql-cache/quicklatex.com-4c95d0acef7eeff31de94d3f7189043e_l3.svg "Rendered by QuickLaTeX.com") by multiplying these probabilities.
by multiplying these probabilities.
5. Benefits of Using HMMs for POS Tagging
To begin with, one prominent challenge in language is ambiguity. For instance, the word “lead” can be a verb (“to guide”) or a noun (“a type of metal”). Here’s where HMMs come into play: they effectively handle the words that can have multiple POS tags by examining the likelihood of each tag based on historical data and the surrounding words.
Moving on, let’s talk about scalability. Let’s say we have vast amounts of text data, from novels to newspapers. The beauty of HMMs is that they can be trained with these large corpora. Moreover, if we stumble upon previously unseen words in new texts, an HMM can guess their tags based on similar contexts encountered during training.
6. Limitations and Challenges
The first problem is data sparsity.
What if we come across the word “flibbertigibbet” in a text? Given its rarity, it’s unlikely that this word appears in most training corpora. So, HMMs might not see some word-tag pairs during training. We use techniques like smoothing, which allocates a small probability to the unseen pairs, ensuring that our model doesn’t falter on rare words.
Next, HMMs use the Markov assumption. It suggests that each word influences only its immediate successor in a sentence, but we know that, in reality, context spans across sentences or even chapters. Despite its success in many applications, the Markov assumption implies that only the previous state is relevant, potentially missing broader contextual clues.
7. Alternatives
While HMMs offer a robust approach to POS tagging, newer methods like neural networks or decision trees have emerged in the NLP realm.
With their deep learning capabilities, the networks can capture intricate patterns and nuances, often outperforming HMMs. Conversely, decision trees provide a transparent and interpretable structure, making them favorable for applications where transparency is paramount.
However, these advanced methods come with trade-offs. Neural networks, for instance, demand vast amounts of data and computational power, while decision trees can become overly complex and less accurate with too many branches.
8. Real-World Applications
Let’s delve into the practical applications of HMM-based POS tagging:
- Speech Recognition: When we use voice assistants like Siri or Google Assistant to dictate “I’m reading a lead story,” it’s crucial for the system to correctly identify “lead” as a noun (a primary news article) rather than its verb form (to guide). Here, HMM-based POS tagging plays a pivotal role in ensuring such distinctions
- Machine Translation: Let’s say we’re translating the English phrase “I read books” into French. It becomes essential for tools like Google Translate to figure out if “read” is present or past tense. By employing HMM-based POS tagging, we aid the system in making this crucial determination
- Text-to-Speech Systems: Let’s picture an app that vocalizes written content. In a sentence like “The wind is too intense to wind the clock,” the role of HMMs in POS tagging becomes evident as they help the system pronounce the two instances of “wind” appropriately
9. Conclusion
In this article, we talked about the integral relationship between HMMs and POS tagging. We delved into practical applications, highlighting their use in speech recognition and machine translation.
HMMs excel in POS tagging due to their adept handling of sequential data. However, rare data points can sometimes hinder their performance. Also, the Markov assumption that each word influences only the next doesn’t account for context relationships between distant words.