

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Multi-task learning encompasses a wide array of transfer learning style methods. At its core, it is training a single model to solve more than one task. This is generally done in parallel though it can be done sequentially in some cases. In the case of sequential tasks, the tasks may repeat, so it is important not to forget what has already been learned. As a learning paradigm, it feels very natural and similar to how humans learn. It can, however, be difficult to use and take advantage of the potential of this paradigm in practice.
A common definition from Rich Caruana’s Dissertation describes multi-task learning as “an approach to inductive transfer that improves generalization by using the domain information contained in the training signals of related tasks as an inductive bias”.
In this tutorial, we make sense of the above definition and introduce the major considerations when deciding whether or not to employ multi-task learning for your problem. We move from considerations of task ordering and model architecture to problems of loss function design and understanding your own goals for such a model.
Machine learning, particularly deep learning, is very useful when it comes to solving complex problems from data. The issue is that it can often be time-consuming to train a machine learning model. Data can also be scarce, and good labeled data can be expensive. It is also not easy to train a model for complex tasks, and we may need additional direction to learn a good solution.
Multi-task learning offers a solution to the problem of efficiency and improved generalization. A shared backbone network can be shared among multiple tasks and can benefit from the training signal coming from each of the target tasks. A larger learning signal can lead to improved learning speed.
Difficult tasks may also benefit from training on easier related tasks. Transferring knowledge across tasks in order to improve model generalization is an important benefit of multi-task learning. How these benefits are achieved, either through training on multiple tasks in parallel or through sequential training, is a design decision that is context-dependent.
The simplest way to think about multi-task learning is to consider a standard machine learning task where you have a dataset  consisting of
consisting of  input vectors
input vectors  and prediction targets
and prediction targets  where
where  is an
is an  Dimensional vector representing prediction targets.
Dimensional vector representing prediction targets.
We consider the case of binary classification. However, extending it to multi-class classification is possible. The standard classification loss in this case then would be:
![\[ \frac{1}{N}\sum^{N}_{i=1} (y_i)log(p(y_i)) + (1-y_i)log(1 - p(y_i)) \]](/wp-content/ql-cache/quicklatex.com-204117f10e041a89ab411f5d49f8931c_l3.svg "Rendered by QuickLaTeX.com")
In multi-task learning, instead of being an  dimensional matrix, it is instead an
dimensional matrix, it is instead an  dimensional matrix, where
dimensional matrix, where  is the number of tasks our model is being trained to solve. We can then re-write our loss as:
is the number of tasks our model is being trained to solve. We can then re-write our loss as:
![\[ \frac{1}{N}\sum^{N}_{i=1} \sum^{T}_{j=1}(y_j^ilog(p(y_j)) + (1-y_j^i)log(1 - p(y{_j}^i)) \]](/wp-content/ql-cache/quicklatex.com-aafdad7d477e1d99981e8c1c41ec5c12_l3.svg "Rendered by QuickLaTeX.com")
We can see the multi-task loss simply adds the loss for each individual task. This loss allows us to train the full network for each task in parallel. The image below offers a comparison of training many individual task models and one multi-task model:
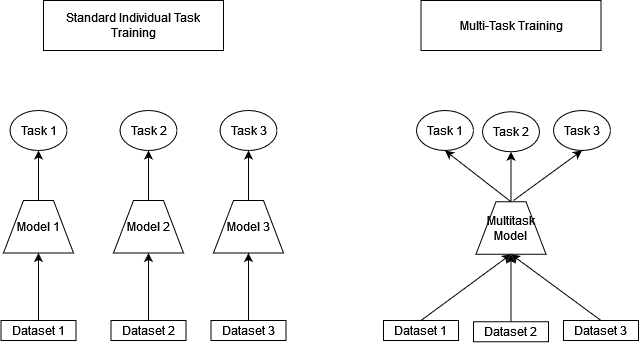
In order to benefit from multi-task learning, the set of tasks used needs to be considered. Not all tasks are mutually beneficial, and some tasks will lead to negative transfer, making it harder to solve other tasks.
Aside from the choice of tasks, we should also consider the order of tasks, how much we weigh the solution to each of the tasks and what parts of the architecture are shared across tasks.
If we have multiple tasks, that means we have multiple loss functions. Optimizing each of those is challenging as they may have different scales, and they may pull in different directions. Finally, they may be entirely unaligned. We need to choose which tasks to optimize together and how we balance each of those included losses.
If we have classification and regression tasks, the difference in loss metric is particularly obvious. We may need to shrink the value of one of the losses to ensure it doesn’t dominate the loss. Similarly, if the number of samples we have for one task is significantly larger than for another task, then we need to balance the losses if we expect similar performance on each task.
Data sampling approaches are also used to balance the network loss. Standard approaches, such as uniform sampling, can be unbalanced. Other approaches, such as weighted sampling and dynamic sampling, where samples are weighted towards data from underperforming tasks, can produce more balanced results.
Network architecture can be shared across multiple tasks. A large shared backbone network is common in many language modeling tasks. In this context, many downstream modeling tasks share this common backbone. This is particularly the case in language modeling, where a large transformer architecture is used as a shared backbone for multiple downstream tasks, such as sentiment classification.
How large the backbone should be in relation to task-specific heads is an open question. This structure is similar to transfer learning through direct weight transfer and pre-training. A major difference is that multi-task learning is trained in parallel.
In a soft sharing scheme, instead of having a fixed architecture, we freeze parts of our network during training. This approach acts to crystallize already learned task knowledge and allow other tasks to embed knowledge in other parts of the network.
This concept intuitively allows for the idea of network blocks specialized for specific sub-aspects of a task. If a certain block is important, it can be given more weight; if it is less important less weight in the overall classification. Recent work in this area consists of architectures such as cross-stitch networks and semi-freddo nets.
Reinforcement Learning offers an interesting domain for the application of multi-task learning, where tasks are not necessarily trained together in parallel but may appear sequentially in the world. Tasks may also repeat at some point in the future, so multi-task learning also needs to overcome the problem of catastrophic forgetting.
In particular, robotics applications are a domain where multi-task learning can be very useful. Reinforcement learning is notoriously data-hungry and slow to train, as datasets are generated on the fly. Sharing experience across robotics tasks can provide a large performance boost. Since robots are costly and time-consuming to set up and maintain, multi-task Learning can provide a large benefit.
We know what multi-task learning is and what we need to consider, but when should you use it?
We should expect a benefit when tasks are aligned and benefit from shared features. Outside of an intuitive understanding of what tasks would be beneficial and which would be detrimental, there is currently limited theoretical insight to help you make that decision.
We can expect a benefit when there is a similar amount of data per task. There may be benefits if one task has much more data than the other. It is also important to train a large enough network. A larger network with more capacity will be better able to capture both the general and task-specific knowledge necessary for accurate classification.
A further benefit is that multi-task learning can be applied in situations where not every input is labeled for every task. In cases where a label is missing, we simply eliminate the loss for that sample for that task and train only on what is available. This lets us include multiple data sets in our training which may be general or specific data-generation processes.
In this article, we introduced the concept of multi-task learning. We examined what it is and its potential applications in providing a better learning signal for a specific target task as well as improving performance across a range of tasks. We also discussed practical considerations and the problems they can help us to overcome.