

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll introduce the concept of weakly supervised learning. We’ll first see the general definition of supervised learning. Then we’ll see the weakly supervised learning, its types, and main applications.
In artificial intelligence and machine learning, supervised learning refers to using a labeled data set to train a machine (or deep) learning algorithm to infer predictions for new instances.
The performance of the trained algorithm depends on many factors. The first of them is that the data set is large and fully annotated with high-quality labeling. Using such a data set during the supervision is called strong supervision learning.
In most cases, having such a large and well-annotated data set is very costly or impractical. Because it needs many domain experts for each problem to lead the annotation process, much time to annotate and revise the annotation, and the original data itself may be noisy or very limited. In such cases, weakly supervised learning is the first choice for annotation and modeling.
Weak Supervision is a branch of machine learning to acquire more labeled data for supervised training and modeling when:
Using the combination of the given labeled data and the weak supervision for obtaining new labeled data while training a machine learning model is called weakly supervised learning.
Weak supervision is intended to decrease the cost of human experts annotation and increase the available labeled data for training. It can have three types; incomplete, inexact, and inaccurate supervision.
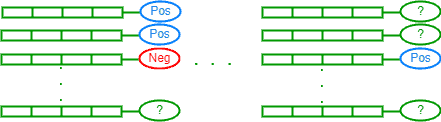
In this type, only a subset of the training data is labeled. In most cases, this subset is correctly and accurately labeled but not sufficient for training a supervised model.
There are two techniques to deal with incomplete supervision; active learning and semi-supervised learning.
Let’s talk first about active learning. This technique converts the weak learning to the strong type. It requires human experts to annotate the unlabeled data manually. Because of the high cost of acquiring all labels from human experts, they are asked to annotate only a subset of the unlabeled data.
In this case, the problem is to find the subset that minimizes the cost of manual annotation and significantly enhances the model performance.
There are two methods to select this subset:
The next one is semi-supervised learning. This technique follows the transductive semi-supervised learning, in which the unlabeled data is the test data. This means that the labeled data is used to train a predictive model, and the unlabeled data is used to test it to get labels. No human experts are involved in this technique.
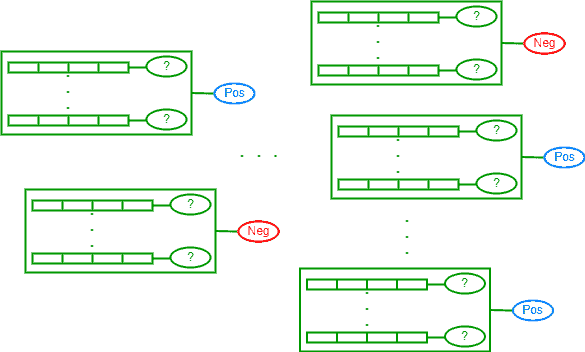
The given labels in this type are imprecise. In some cases, this type also contains some misleading records. These can accept more than a label because there are no discriminating features. Developers use the available labels to create rules and constraints on the training data.
In this type of supervision, we use multi-instance learning. In multi-instance learning, a bag (subset) of instances is labeled according to one of the instances (the key instance), or the majority, inside the bag. For each algorithm, the bag generator specifies how many instances should be in each bag. A bag can be an image, a text document, a set of records for stocks, and so on.
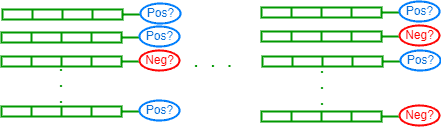
In this type, there are wrong or low-quality labels. Inaccurate labels usually come from collecting public or crowdsourcing data sets.
The idea is to identify the potential mislabeled instances and to correct or remove them. One of the practical techniques to achieve this idea is the data-editing approach.
The data-editing approach constructs a graph of relative neighborhoods, where each node is an instance, and an edge connects two nodes of different labels. An instance (node) is considered suspicious if it is connected to many edges. This suspicious instance is then removed or re-labeled according to the majority.
For crowdsourcing data sets, we obtain the labels according to the majority agreement for all annotators.
Weak supervision is not associated with a specific supervision task or problem. Weak supervision is used whenever the annotation of the training data set is incomplete or insufficient to get a predictive model with good performance.
Weak supervision can be used with image classification, object recognition, text classification, spam detection, medical diagnosis, and financial problems (like estimating houses’ prices).
In this tutorial, we showed the general definitions of strong and weak supervision learning. Then we went into details of weak supervision and its types; incomplete, inexact, and inaccurate.