

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explain the maximum-minimum path capacity problem in graph theory. We’ll define what it is, how to solve it, and how the solution differs from Dijkstra’s.
The maximum-minimum path capacity problem deals with weighted graphs.
We consider the weight of each edge to represent that edge’s capacity. Our task is to find the path that starts from a source node  and ends at a goal node
and ends at a goal node  inside the graph. The edge with the lowest capacity in a path forms that path’s capacity.
inside the graph. The edge with the lowest capacity in a path forms that path’s capacity.
Among all the paths from to , what we want to do is find the path of maximum capacity.
As a practical example, suppose the graph represents the capacity of water that each pipe can deliver per second. Obviously, we’d be looking for a path that can deliver the largest amount of water per second, and we can’t deliver it any faster than the smallest pipe in the path.
Have a look at the following example. We consider the source node to be  and the goal node to be
and the goal node to be  .
.
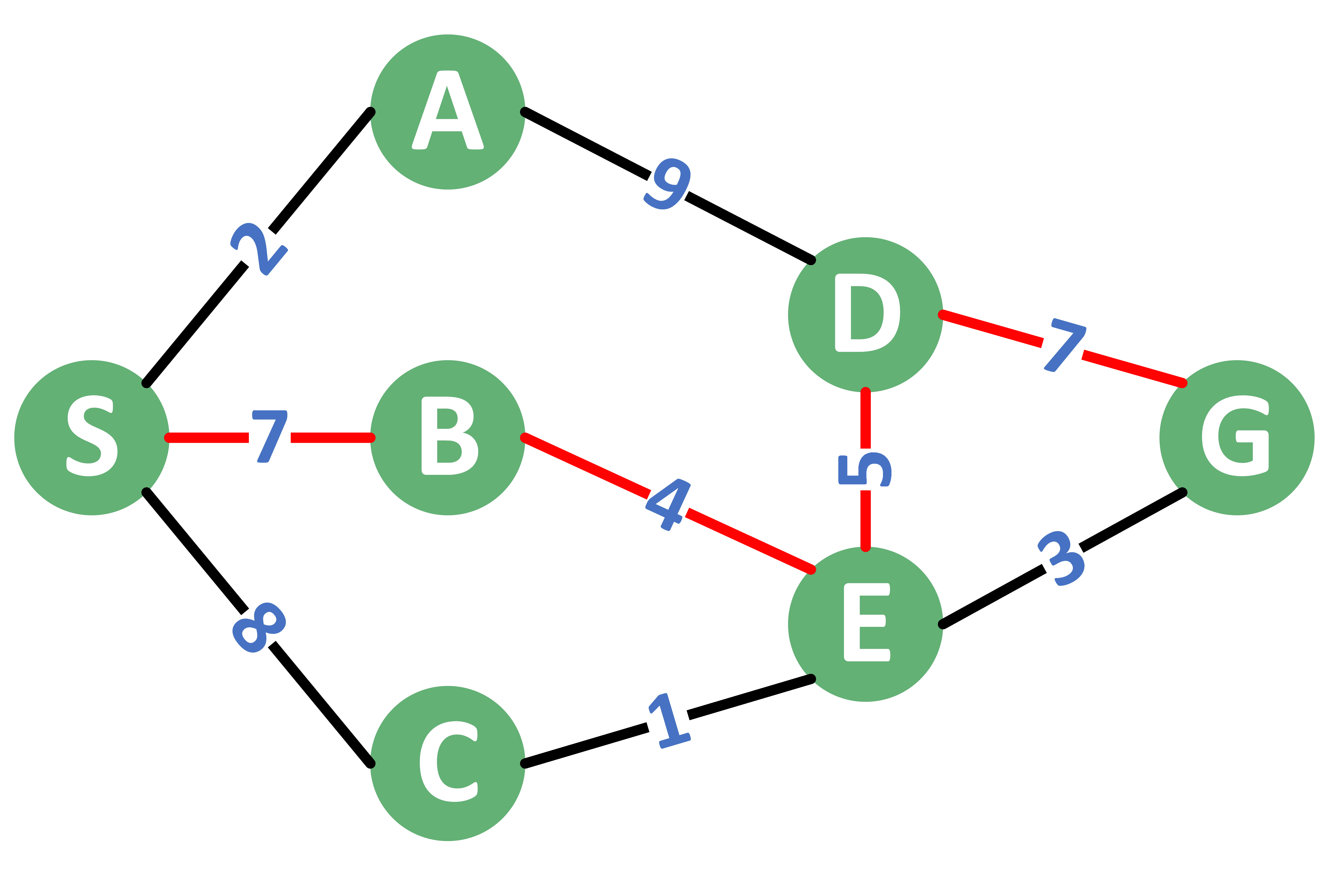
From the graph example, we see that there are multiple paths connecting node with . The following table lists the different paths along with their capacity.
| # | Path | Capacities | Min. Capacity |
|---|---|---|---|
| 1 | SADG | 2,9,7 | 2 |
| 2 | SADEG | 2,9,5,3 | 2 |
| 3 | SBEDG | 7,4,5,7 | 4 |
| 3 | SBEG | 7,4,3 | 3 |
| 3 | SCEG | 8,1,3 | 1 |
Out of all the paths, path number 3 has the largest capacity, which is 4. Therefore, the maximum-minimum capacity for the given graph equals 4.
In order to solve this problem, we’ll use a modified version of Dijkstra’s algorithm.
The pseudocode of this problem is mostly derived from Dijkstra’s algorithm with the following changes:
 . This array will store the maximum capacity of each
. This array will store the maximum capacity of each  . By the maximum capacity of a node, we mean the maximum-minimum capacity for all the paths from to this node.
. By the maximum capacity of a node, we mean the maximum-minimum capacity for all the paths from to this node. .
, we still do this, indicating that the source node has an unlimited capacity to itself. array with
.
, we still do this, indicating that the source node has an unlimited capacity to itself. array with  , corresponding to the worst case.
, corresponding to the worst case.The proof of this algorithm’s optimality is that we always process the node with the largest capacity. Hence, when we reach the goal node, all the remaining nodes inside the data structure must have a smaller capacity. Therefore, the found path would be the one with the maximum-minimum capacity.
Now, let’s review the algorithm in pseudocode:
algorithm findMaxMin(G, source, prev):
// INPUT
// G = the stored graph
// source = the source node to start from
// prev = the array to store the predecessor of each node
// OUTPUT
// Returns the maximum minimum capacity starting from node source
capacity <- -infinity
prev <- undefined
capacity[source] <- infinity
Q <- all nodes in the graph
while Q is not empty:
u <- Q.getNodeWithMaxCapacity()
if capacity[u] = -infinity:
break
for v in neighbors(u):
newCapacity <- min(capacity[u], capacityBetween(u, v))
if newCapacity > capacity[v]:
capacity[v] <- newCapacity
prev[v] <- u
Q.update(v)
return capacityFirst, we initialize the array with . We’ll also initialize an array  which will store, for each node
which will store, for each node  , the node that gets us to reach node with the maximum path capacity.
, the node that gets us to reach node with the maximum path capacity.
Next, we initialize the capacity of the source node with and add all the nodes to  . The purpose of is to find the node with the maximum capacity so far quickly. Also, needs to support updating the capacity of some node through the function
. The purpose of is to find the node with the maximum capacity so far quickly. Also, needs to support updating the capacity of some node through the function  . For this, we can use a set that stores the node with its capacity sorted in descending order based on the capacity.
. For this, we can use a set that stores the node with its capacity sorted in descending order based on the capacity.
In each step, we extract the node with the maximum path capacity from using the function  . If the extracted node has a capacity equal to , then all the remaining nodes inside can’t be reached from node. Therefore, we can just stop processing further nodes.
. If the extracted node has a capacity equal to , then all the remaining nodes inside can’t be reached from node. Therefore, we can just stop processing further nodes.
Otherwise, we iterate over all the neighbors of node . for each neighbor, we calculate the new capacity. The new capacity is the minimum between the capacity of node and the capacity of the edge between and  . Therefore, we’ve taken the minimum capacity along the path.
. Therefore, we’ve taken the minimum capacity along the path.
After that, we compare the new capacity to the old one for node . If the new capacity is better, then we update the information of node with the new capacity. Updating the information of node includes updating its capacity, updating the value for it to become , and using the function that removes this node’s object from and adds it again with the new path capacity.
Finally, we return , which is the calculated capacity.
The algorithm can be implemented to have a complexity of  , similar to Dijkstra’s algorithm, where
, similar to Dijkstra’s algorithm, where  is the number of edges inside the graph and
is the number of edges inside the graph and  is the number of vertices.
is the number of vertices.
We’ll use the array to restore the path we need. Let’s take a look at the algorithm:
algorithm FindMaxMinPath(G, source, goal):
// INPUT
// G = the stored graph
// source = the source node to start from
// goal = the goal node to reach
// OUTPUT
// Returns the path with the maximum minimum capacity starting from node source
findMaxMin(G, source, prev)
u <- goal
path <- empty list
while u != undefined:
path.add(u)
u <- prev[u]
reverse(path)
return pathThe algorithm is simple. We start from the node. In each step, we add the current node to the path. Also, we move one step back to the previous node using the array calculated in  function.
function.
Since the node will have its previous node equal to  , we can stop going back once we reach the value.
, we can stop going back once we reach the value.
The complexity of this algorithm (without the findMaxMin function) is  , where is the total number of vertices inside the graph.
, where is the total number of vertices inside the graph.
In this tutorial, we presented the maximum-minimum capacity in a graph problem. First, we defined the problem. Next, we provided an example that better explains the concept.
After that, we highlighted the main differences between our algorithm and Dijkstra’s algorithm.
Finally, we showed the algorithm.