

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: February 13, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’re going to learn about the cost function in logistic regression, and how we can utilize gradient descent to compute the minimum cost.
We use logistic regression to solve classification problems where the outcome is a discrete variable. Usually, we use it to solve binary classification problems. As the name suggests, binary classification problems have two possible outputs.
We utilize the sigmoid function (or logistic function) to map input values from a wide range into a limited interval. Mathematically, the sigmoid function is:
![\[y = g(z) = \frac{1}{1 + e^{-z}} = \frac{e^z}{1 + e^z}\]](/wp-content/ql-cache/quicklatex.com-20d938c0f1f641910eac7fd33549dbb3_l3.svg "Rendered by QuickLaTeX.com")
This formula represents the probability of observing the output  of a Bernoulli random variable. This variable is either
of a Bernoulli random variable. This variable is either  or
or  (
( ).
).
It squeezes any real number to the  open interval. Thus, it’s better suited for classification. Moreover, it’s less sensitive to outliers, unlike linear regression:
open interval. Thus, it’s better suited for classification. Moreover, it’s less sensitive to outliers, unlike linear regression:
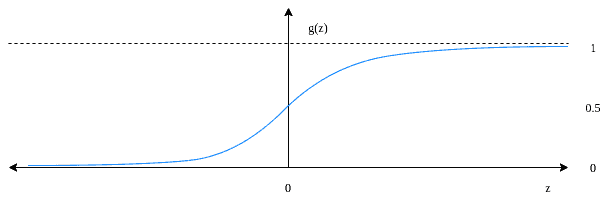
Applying the sigmoid function on gives  . The output becomes as the input approaches
. The output becomes as the input approaches  . Conversely, sigmoid becomes as the input approaches
. Conversely, sigmoid becomes as the input approaches  .
.
More formally, we define the logistic regression model for binary classification problems. We choose the hypothesis function to be the sigmoid function:
![\[h_{\theta}(x) = \frac{1}{1+e^{-\theta^T x}}\]](/wp-content/ql-cache/quicklatex.com-10205eab345b6935d1135afc5b02f041_l3.svg "Rendered by QuickLaTeX.com")
Here,  denotes the parameter vector. For a model containing
denotes the parameter vector. For a model containing  features, we have
features, we have ![\theta = [\theta_0, \theta_1, ..., \theta_n]](/wp-content/ql-cache/quicklatex.com-b97ee429b332e4283c92bc49337d52b4_l3.svg "Rendered by QuickLaTeX.com") containing
containing  parameters. The hypothesis function approximates the estimated probability of the actual output being equal to . In other words:
parameters. The hypothesis function approximates the estimated probability of the actual output being equal to . In other words:
![\[P(y=1| \theta, x) = g(z) = \frac{1}{1+e^{-\theta^T x}}\]](/wp-content/ql-cache/quicklatex.com-6272b97506eb16899f4a4d898c2042f0_l3.svg "Rendered by QuickLaTeX.com")
and
![\[P(y=0| \theta, x) = 1 - g(z) = 1 - \frac{1}{1+e^{-\theta^T x}} = \frac{1}{1 + e^{\theta^T x}}\]](/wp-content/ql-cache/quicklatex.com-51563c11c80a76141d77b8dc3a95fba1_l3.svg "Rendered by QuickLaTeX.com")
More compactly, this is equivalent to:
![\[P(y | \theta, x) = \left(\frac{1}{1 + e^{-\theta^T x}} \right)^y \times \left(1- \left(\frac{1}{1 + e^{\theta^T x}} \right) \right)^{1-y}\]](/wp-content/ql-cache/quicklatex.com-db44248363a206aa545122043dd57fad_l3.svg "Rendered by QuickLaTeX.com")
The cost function summarizes how well the model is behaving. In other words, we use the cost function to measure how close the model’s predictions are to the actual outputs.
In linear regression, we use mean squared error (MSE) as the cost function. But in logistic regression, using the mean of the squared differences between actual and predicted outcomes as the cost function might give a wavy, non-convex solution; containing many local optima:
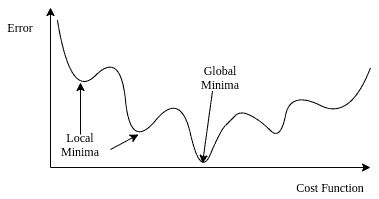
In this case, finding an optimal solution with the gradient descent method is not possible. Instead, we use a logarithmic function to represent the cost of logistic regression. It is guaranteed to be convex for all input values, containing only one minimum, allowing us to run the gradient descent algorithm.
When dealing with a binary classification problem, the logarithmic cost of error depends on the value of  . We can define the cost for two cases separately:
. We can define the cost for two cases separately:
![\[cost(h_{\theta}(x),y) = \left\{ \begin{array}{lr} - log(h_{\theta}(x)) & \text{, if } y = 1\\ - log(1-h_{\theta}(x)) & \text{, if } y = 0 \end{array}\]](/wp-content/ql-cache/quicklatex.com-62f987389ecd41ee0fb70c4ad6398d86_l3.svg "Rendered by QuickLaTeX.com")
Which then results in:
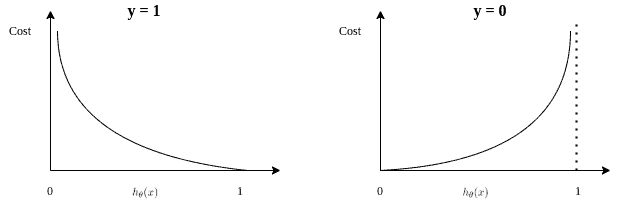
Because when the actual outcome , the cost is for  and takes the maximum value for
and takes the maximum value for  . Similarly, if
. Similarly, if  , the cost is for .
, the cost is for .
As the output can either be  or
or  , we can simplify the equation to be:
, we can simplify the equation to be:
![\[cost(h_{\theta}(x),y) = - y^{(i)} \times log(h_{\theta}(x^{(i)})) - (1-y^{(i)}) \times log(h_{\theta}(x^{(i)}))\]](/wp-content/ql-cache/quicklatex.com-152552411cbfda42a7710d3e19e1cdaa_l3.svg "Rendered by QuickLaTeX.com")
For  observations, we can calculate the cost as:
observations, we can calculate the cost as:
![\[ J(\theta) = - \frac{1}{m} \sum_{i=1}^{m} \left[ y^{(i)} \times log(h_{\theta}(x^{(i)})) + (1-y^{(i)}) \times log(h_{\theta}(x^{(i)})) \right] \]](/wp-content/ql-cache/quicklatex.com-adbb9424df89cc78eb9a9c3896e164c3_l3.svg "Rendered by QuickLaTeX.com")
Gradient descent is an iterative optimization algorithm, which finds the minimum of a differentiable function. In this process, we try different values and update them to reach the optimal ones, minimizing the output.
In this article, we can apply this method to the cost function of logistic regression. This way, we can find an optimal solution minimizing the cost over model parameters:
![\[\min_\theta J(\theta)\]](/wp-content/ql-cache/quicklatex.com-8da72848a283c99988c0fba3a4eec423_l3.svg "Rendered by QuickLaTeX.com")
As already explained, we’re using the sigmoid function as the hypothesis function in logistic regression.
Assume we have a total of features. In this case, we have parameters for the vector. To minimize our cost function, we need to run the gradient descent on each parameter  :
:
![\[\theta_j \gets \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta)\]](/wp-content/ql-cache/quicklatex.com-72a1a618c575b5f593a0e629d171a5d6_l3.svg "Rendered by QuickLaTeX.com")
Furthermore, we need to update each parameter simultaneously for each iteration. In other words, we need to loop through the parameters  ,
,  , …,
, …,  in vector .
in vector .
To complete the algorithm, we need the value of  , which is:
, which is:
![\[\frac{\partial}{\partial \theta_j} J(\theta) = \frac{1}{m} \sum_{i=1}^{m} \left( h_{\theta}(x^{(i)}) - y^{(i)} \right) x_j^{(i)}\]](/wp-content/ql-cache/quicklatex.com-35e8bb42947bd888580c2a8a9fe8fe0e_l3.svg "Rendered by QuickLaTeX.com")
Plugging this into the gradient descent function leads to the update rule:
![\[\theta_j \gets \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} \left( h_{\theta}(x^{(i)}) - y^{(i)} \right) x_j^{(i)}\]](/wp-content/ql-cache/quicklatex.com-58d95f0ac49c3a19a5f25e6cf768fab3_l3.svg "Rendered by QuickLaTeX.com")
Surprisingly, the update rule is the same as the one derived by using the sum of the squared errors in linear regression. As a result, we can use the same gradient descent formula for logistic regression as well.
By iterating over the training samples until convergence, we reach the optimal parameters leading to minimum cost.
In this article, we’ve learned about logistic regression, a fundamental method for classification. Moreover, we’ve investigated how we can utilize the gradient descent algorithm to calculate the optimal parameters.