Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: June 13, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
There are several metrics for evaluating machine-learning (ML) models. One that we often calculate when analyzing classifiers is the  score, which combines precision and recall into a single value.
score, which combines precision and recall into a single value.
In this tutorial, we’ll talk about its generalization, the  score, which can give more weight to either recall or precision.
score, which can give more weight to either recall or precision.
The F1 score of a classifier is the harmonic mean of its precision  and recall
and recall  :
:
(1) 
It’s useful because it’s high when both scores are large, as we see in its contour plot:
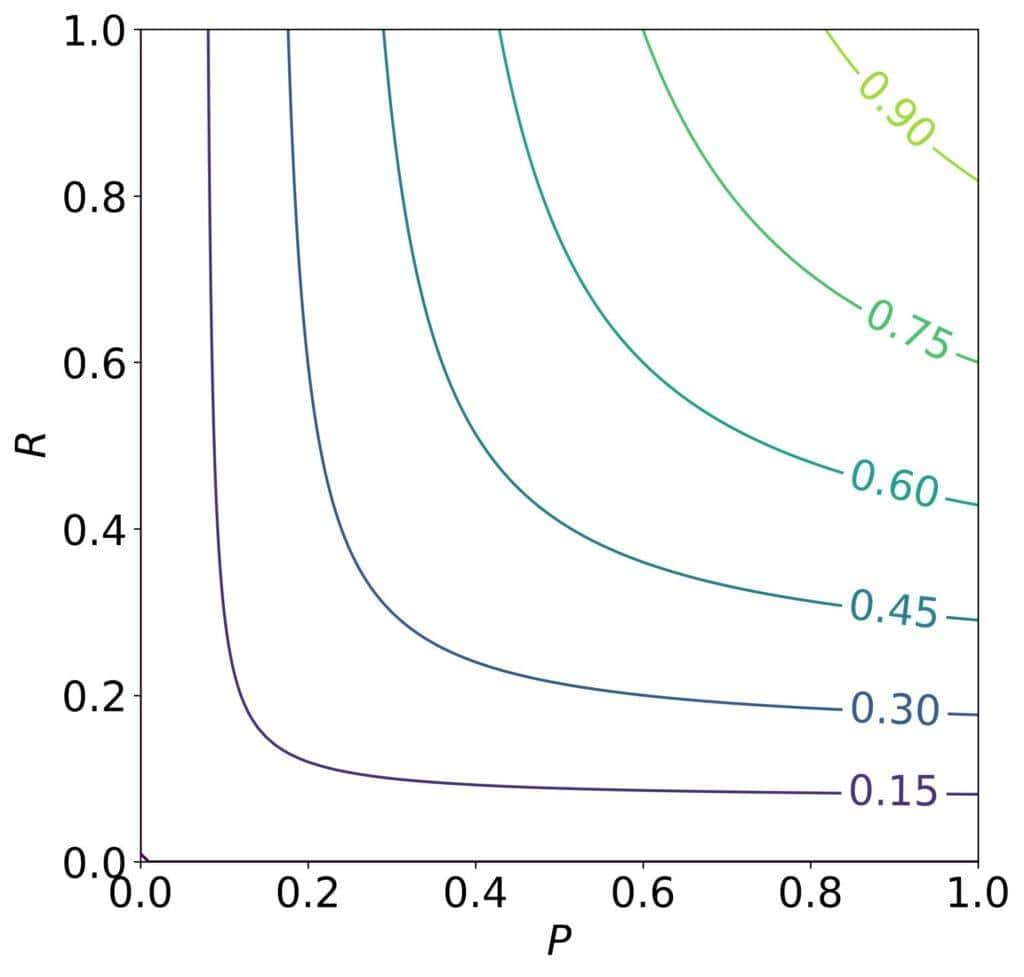
It gives equal weights to recall and precision, so the contours are symmetric around the 45-degree line,
However, there are cases where one of the scores is more important than the other.
We care more about recall if a false negative is more severe an error than a false positive. Automated diagnostic ML tools in medicine illustrate that. There, a false negative is a missed condition, which could be fatal for our patient’s health. In contrast, a false-positive diagnosis induces stress, but additional testing can relieve the patient.
Conversely, precision is more important when a false positive has a higher cost. That’s the case in spam detection. Letting a spam e-mail appear in the inbox may annoy the user, but marking a non-spam e-mail as spam and sending it to thrash could result in the loss of a job opportunity.
In such applications, we’d like to have a metric that considers the relative importance of  and
and  . The score does precisely that.
. The score does precisely that.
The common formulation of is:
(2) 
It’s a weighted harmonic mean of and which uses  and
and  as the weights:
as the weights:
(3) 
If  , the recall is
, the recall is  times more important than precision, and if
times more important than precision, and if  , it’s the other way around. As the contours for
, it’s the other way around. As the contours for  show, we can get a high
show, we can get a high  score if the recall is high enough no matter if the precision is low, which aligns with our requirements:
score if the recall is high enough no matter if the precision is low, which aligns with our requirements:
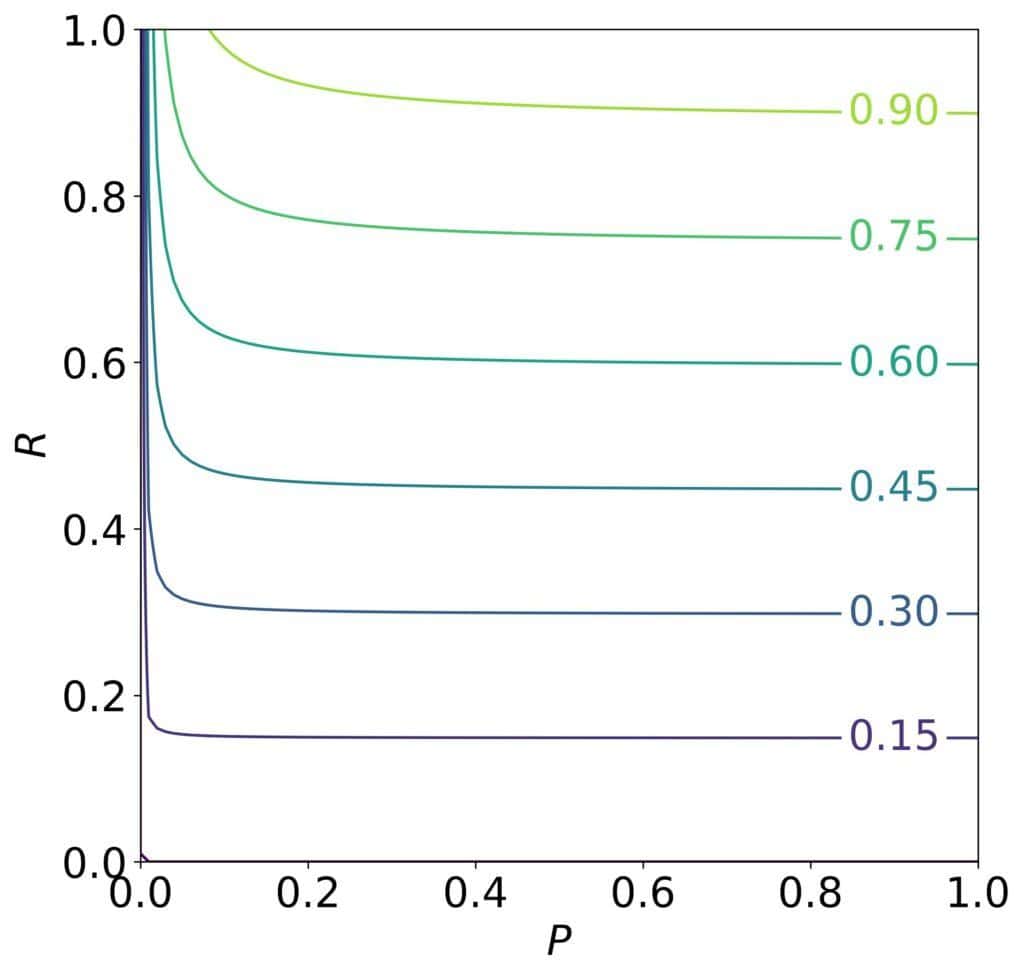
But why does  figure in the equations instead of
figure in the equations instead of  ? Isn’t the latter more intuitive?
? Isn’t the latter more intuitive?
The reason why we have instead of lies in how the relative importance was defined when was first formulated.
In general, the weighted harmonic mean of and using  and
and  as the weights is:
as the weights is:
(4) 
To get from  , we require the latter to satisfy the condition of relative importance. More precisely, we want to be such that at the points at which and equally contribute to , is times .
, we require the latter to satisfy the condition of relative importance. More precisely, we want to be such that at the points at which and equally contribute to , is times .
Mathematically, that means that the ratio  should be equal to when the partial derivatives
should be equal to when the partial derivatives  and
and  are the same.
are the same.
Let’s first find the derivatives:
(5) 
From  , we get:
, we get:
(6) 
Requiring the ratio  to be , we solve
to be , we solve  for :
for :
(7) 
Plugging in into the weighted harmonic mean, we get as defined by Equations (2) and (3).
Let’s analyze what happens to as we vary .
Setting to 1, we get the usual  . That covers the case with and having equal weights.
. That covers the case with and having equal weights.
If only recall is important, we let  . In that case, we expect to reduce to . Taking the limit, we get:
. In that case, we expect to reduce to . Taking the limit, we get:
(8) 
Similarly, if we care only about precision, we set to 0:
(9) 
The values of between 0 and  represent intermediate cases.
represent intermediate cases.
A different definition of relative importance would yield a different  score.
score.
For instance, we could say that if we consider the recall score to be times more important than precision, that means that when  , increasing improves times as much as an equal increase in .
, increasing improves times as much as an equal increase in .
Mathematically, this translates to the following condition:
(10) 
Solving for , we get:
(11) 
From there, we get a metric that is linear in :
(12) 
It too reduces to when  but uses a different definition of relative importance than the version with .
but uses a different definition of relative importance than the version with .
In this article, we talked about the score. We use it to evaluate classifiers when the recall and precision aren’t equally important. For instance, that’s the case in spam detection and medicine.
However, the two scores’ relative importance we quantify with has a formal mathematical definition: when their partial derivatives are equal, recall is times as large as precision.