Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 26, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about how to calculate the F-1 score in a multi-class classification problem. Unlike binary classification, multi-class classification generates an F-1 score for each class separately.
We’ll also explain how to compute an averaged F-1 score per classifier in Python, in case a single score is desired.
F-1 score is one of the common measures to rate how successful a classifier is. It’s the harmonic mean of two other metrics, namely: precision and recall. In a binary classification problem, the formula is:
![\[\textrm{F-1 Score} = \frac{2 \times \textrm{Precision} \times \textrm{Recall}}{\textrm{Precision} + \textrm{Recall}}\]](/wp-content/ql-cache/quicklatex.com-427c003face698912b8b5493c4b1cfa2_l3.svg "Rendered by QuickLaTeX.com")
The F-1 Score metric is preferable when:
As the F-1 score is more sensitive to data distribution, it’s a suitable measure for classification problems on imbalanced datasets.
For a multi-class classification problem, we don’t calculate an overall F-1 score. Instead, we calculate the F-1 score per class in a one-vs-rest manner. In this approach, we rate each class’s success separately, as if there are distinct classifiers for each class.
As an illustration, let’s consider the confusion matrix below with a total of 127 samples:
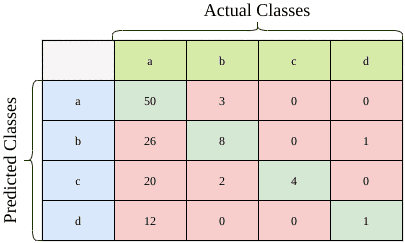
Now let’s calculate the F-1 score for the first class, which is class a. We first need to calculate the precision and recall values:
![\[\textrm{Precision}(class=a)} = \frac{TP(class=a)}{TP(class=a) + FP(class=a)} = \frac{50}{53} = 0.943\]](/wp-content/ql-cache/quicklatex.com-92c0d186980be7ededde7ebf192b310a_l3.svg "Rendered by QuickLaTeX.com")
![\[\textrm{Recall}(class=a) = \frac{TP(class=a)}{TP(class=a) + FN(class=a)} = \frac{50}{108} = 0.463\]](/wp-content/ql-cache/quicklatex.com-d8db7e5855e9558151d7237564defe6f_l3.svg "Rendered by QuickLaTeX.com")
Then, we apply the formula for class a:
![\[\textrm{F-1 Score}(class=a)} = \frac{2 \times \textrm{Precision}(class=a) \times \textrm{Recall}(class=a)}{\textrm{Precision}(class=a) + \textrm{Recall}(class=a)} = \frac{2 \times 0.943 \times 0.463}{0.943 + 0.463} = 0.621\]](/wp-content/ql-cache/quicklatex.com-26f7383b2babe37929f1461e1a8bf370_l3.svg "Rendered by QuickLaTeX.com")
Similarly, we first calculate the precision and recall values for the other classes:
![\[\textrm{Precision}(class=b)} = \frac{8}{35} = 0.228 \ \ \textrm{Recall}(class=b) = \frac{8}{13} = 0.615\]](/wp-content/ql-cache/quicklatex.com-54e689fe24956c439bd83fffdb78f186_l3.svg "Rendered by QuickLaTeX.com")
![\[\textrm{Precision}(class=c)} = \frac{4}{26} = 0.154 \ \ \textrm{Recall}(class=c) = \frac{4}{4} = 1.000\]](/wp-content/ql-cache/quicklatex.com-c644508a6032036d053b5a81a2cba0ed_l3.svg "Rendered by QuickLaTeX.com")
![\[\textrm{Precision}(class=d)} = \frac{1}{13} = 0.077 \ \ \textrm{Recall}(class=d) = \frac{1}{2} = 0.500\]](/wp-content/ql-cache/quicklatex.com-949fd2cf4b1ec0fec1ac914d85af501f_l3.svg "Rendered by QuickLaTeX.com")
The calculations then lead to per-class F-1 scores for each class:
![\[\textrm{F-1 Score}(class=b)} = \frac{2 \times 0.228 \times 0.615}{0.228 + 0.615} = 0.333\]](/wp-content/ql-cache/quicklatex.com-9ed6979cf1461578136b8b891225983e_l3.svg "Rendered by QuickLaTeX.com")
![\[\textrm{F-1 Score}(class=c)} = \frac{2 \times 0.154 \times 1.000}{0.154 + 1.000} = 0.267\]](/wp-content/ql-cache/quicklatex.com-c5d105b54d7e869a2fc831e4b3d53c38_l3.svg "Rendered by QuickLaTeX.com")
![\[\textrm{F-1 Score}(class=d)} = \frac{2 \times 0.077 \times 0.500}{0.077 + 0.500} = 0.133\]](/wp-content/ql-cache/quicklatex.com-d3b72c7ea7819b01a132a39e6cb64b1c_l3.svg "Rendered by QuickLaTeX.com")
In the Python sci-kit learn library, we can use the F-1 score function to calculate the per class scores of a multi-class classification problem.
We need to set the average parameter to None to output the per class scores.
For instance, let’s assume we have a series of real y values (y_true) and predicted y values (y_pred). Then, let’s output the per class F-1 score:
from sklearn.metrics import f1_score
f1_score(y_true, y_pred, average=None)In our case, the computed output is:
array([0.62111801, 0.33333333, 0.26666667, 0.13333333])On the other hand, if we want to assess a single F-1 score for easier comparison, we can use the other averaging methods. To do so, we set the average parameter.
Here we’ll examine three common averaging methods.
The first method, micro calculates positive and negative values globally:
f1_score(y_true, y_pred, average='micro')In our example, we get the output:
0.49606299212598426Another averaging method, macro, take the average of each class’s F-1 score:
f1_score(y_true, y_pred, average='macro')gives the output:
0.33861283643892337Note that the macro method treats all classes as equal, independent of the sample sizes.
As expected, the micro average is higher than the macro average since the F-1 score of the majority class (class a) is the highest.
The third parameter we’ll consider in this tutorial is weighted. The class F-1 scores are averaged by using the number of instances in a class as weights:
f1_score(y_true, y_pred, average='weighted')generates the output:
0.5728142677817446In our case, the weighted average gives the highest F-1 score.
We need to select whether to use averaging or not based on the problem at hand.
In this tutorial, we’ve covered how to calculate the F-1 score in a multi-class classification problem.
Firstly, we described the one-vs-rest approach to calculate per class F-1 scores.
Also, we’ve covered three ways of calculating a single average score in Python.