

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explain how to do early stopping to avoid overfitting machine-learning (ML) models to data.
In machine learning, overfitting means that our model is very accurate on the training dataset but can’t generalize to other data. So, its training error is small, but the test and validation errors are significant.
Overfitting happens when our model captures the noise in the training set, e.g.:
We use regularization techniques to avoid overfitting. One of the most popular and effective regularization methods, especially when it comes to neural networks, is early stopping.
After each iteration of the chosen training algorithm, we evaluate our model on the training and validation sets.
The results on the former show how well our model fits the training data, whereas the latter reveals how well it generalizes to data not seen during training. Plotting the scores against iterations, we get the training and validation learning curves. Typically, the training curve shows decreasing errors, and the validation curve shows larger values that gradually decrease up to a point after which they start increasing:
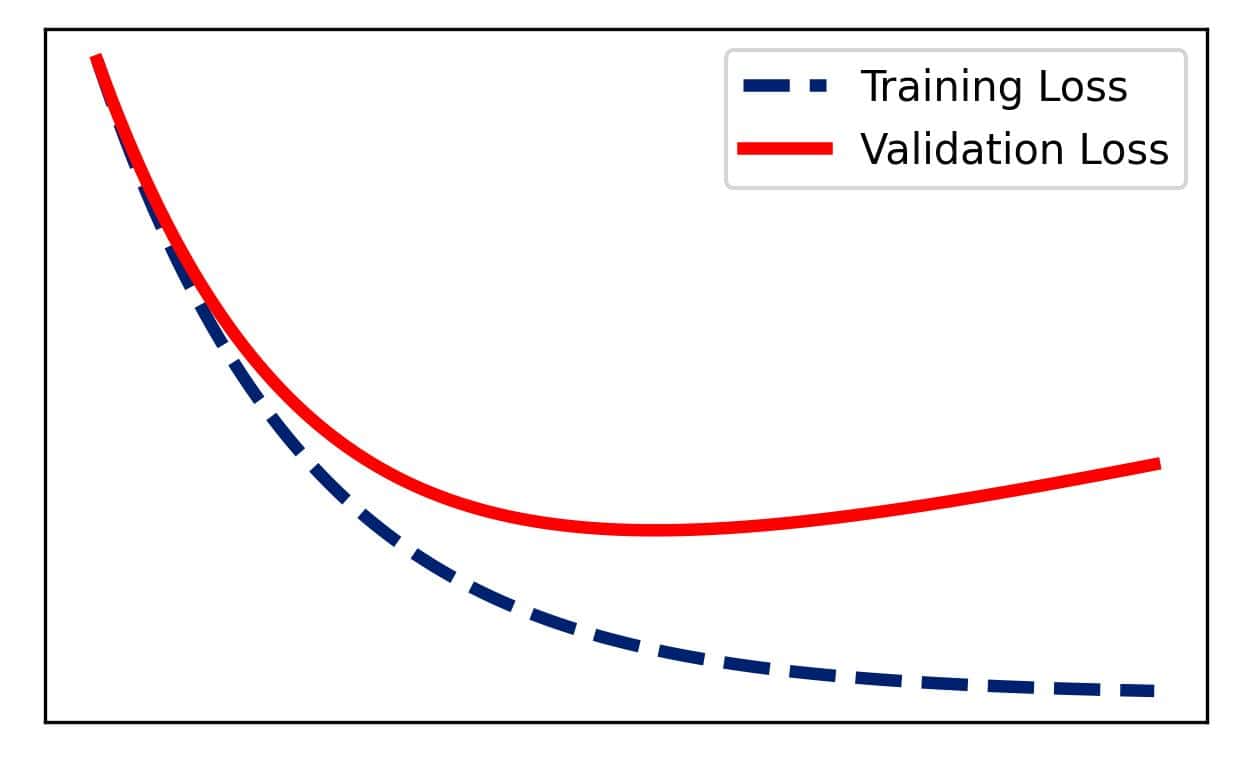
The inflection point in the validation curve is the iteration in which our model starts to incorporate the noise in the training set, which is why its performance on the validation set deteriorates afterward.
In early stopping, we want to stop training before reaching that point.
Overfitting is relatively easy to spot when we look at images, but plotting and checking them during training is impractical. So, we need to formalize the detection rules to use this technique programmatically.
To do so, we define the number of consecutive iterations in which the validation losses should increase to be sure that we’re overfitting ( ):
):
algorithm EarlyStopping(m):
// INPUT
// m = the number of successive iterations needed to prove overfitting
// OUTPUT
// Returns a trained model; overfitting is avoided.
k <- 0 // The counter for overfitting
previous_loss <- infinity
while k < m and other stopping criteria for training are not met:
Run one iteration of the training algorithm
current_loss <- evaluate the model on the validation set
if current_loss <= previous_loss:
// validation loss does not increase
Save the model
k <- 0
else:
// validation loss increases
k <- k + 1
previous_loss <- current_loss
return the last saved modelWe reset the counter in every iteration the validation doesn’t increase. At the same time, we save the current model because that’s the best one we found up to that point.
This algorithm does more than avoid the inflection point on the validation curve. The way we formulated it, it stops training if no validation-score improvement is made for consecutive iterations.

If we set to a large value, early stopping will require stronger proof of overfitting. As a result, we’ll train our model longer than necessary.
Conversely, a small corresponds to weaker proofs. Although we spend less time training with such an , this can lead to an unsatisfactory model. For example, the training algorithm might figure out it needs to reset some weights, which could improve performance in a couple of iterations. However, if we stop it too early, the algorithm won’t be able to do it.
Additionally, we can specify the minimum decrease in error our model has to show between two iterations for us to say it has improved.
For example, we can define the improvement as a drop in the misclassification rate by at least 0.2%. So, if the validation rates in iterations  and
and  differ by less than 0.2%, we stop training. The justification would be that further training is only wasting computational resources since it isn’t likely to lead to significantly better performance.
differ by less than 0.2%, we stop training. The justification would be that further training is only wasting computational resources since it isn’t likely to lead to significantly better performance.
In this article, we talked about early stopping. It’s a regularization technique that prevents overfitting by stopping the training process when the model’s performance on the validation set doesn’t improve.