Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
How to Calculate the Regularization Parameter in Linear Regression
Last updated: February 28, 2025

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll introduce the classic machine algorithm known as linear regression. First, we’ll discuss the term regression and all the different types of regression. Then we’ll dive into a detailed examination of linear regression, and why we need regularization. Everything will be followed by appropriate mathematical formulas and notations, with a clear explanation of them.
After all, linear regression is one of the most popular and most used statistical and machine learning algorithms, and it’s covered in every related course.
2. Regression
Generally, regression is a family of statistical algorithms that we use to measure relationships between two or more variables. The main logic is that we want to find a connection between input variables (features), which we call independent variables, and outcome or dependent variables. By leveraging this relationship between input and output variables, regression is broadly used as a machine learning model for predicting or forecasting.
For example, we can use R-squared to measure the relationship between two variables, which tells us how close our variables are to the fitted regression line. We can also use polynomial regression to forecast future prices based on historical data, or logistic regression to model the probability for binary classification.
2.1. Types of Regression
There are many types of regression, but here we’ll only mention some of them. Based on the number of input variables, we can classify regression into two groups:
- Simple regression – uses only one variable as an input
- Multiple regression – uses two or more variables as an input
Similarly, based on the number of dependent or output variables, we can classify regression as:
- Univariate regression – there’s only one dependent variable
- Multivariate regression – there are two or more dependent variables
The three most commonly used regression models are:
- Linear regression – it assumes that we have a linear relationship between input and output variables, and a linear function is used to explain that relationship
- Polynomial regression – similar to linear regression, but uses polynomials to approximate the relationship between variables
- Logistic regression – uses a logistic function or sigmoid to model a probability for binary classification problems
Finally, it’s worth mentioning that the term regression is also widely used in a different context, as a class of machine learning algorithms. Usually, we can see that most machine learning problems are divided into two classes:
- Classification problems – the goal is to predict a predefined label or class. For example, to predict if the sentiment of the particular sentence is positive, or predict the handwritten digit on the image
- Regression problems – the goal is to quantify. For example, to predict tomorrow’s price of Tesla stock, or predict the exact temperature using some weather data
3. Linear Regression
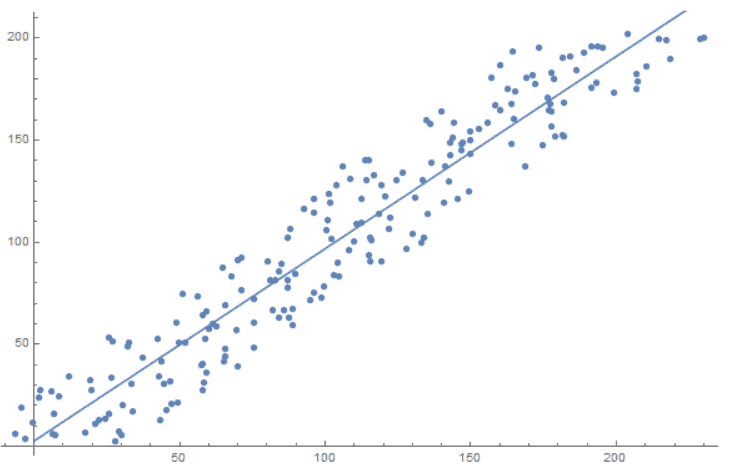
We previously mentioned some of the most used regression techniques, and in this section, we’ll introduce what may be the most popular one. Linear regression is an approach to modelling the relationship between one dependent variable and one or more explanatory variables, either continuous or discrete. This technique helps in predicting the future values of one variable through the use of another variable. It enables us to predict how much weight one variable has on another variable by using the past data of both variables.
The image below shows how linear regression approximates the relationship between features on the  and
and  axis:
axis:
We define linear regression with the formula:
(1) 
Here,  is the predicted value,
is the predicted value,  is the number of features,
is the number of features,  is the
is the  -th feature value, and
-th feature value, and  is the
is the  -th model parameter or weight. Also,
-th model parameter or weight. Also,  is known as a bias term.
is known as a bias term.
Similarly, we can write the equation above using a vectorized form:
(2) 
Here,  is the transpose model’s weight vector,
is the transpose model’s weight vector,  , and
, and  is the feature vector, where
is the feature vector, where  .
.
Next, to train the model, we first need to measure how well the model fits the training data. For this purpose, we commonly use the mean squared error (MSE) cost function. We define it using the formula:
(3) 
Here,  indicates the number of samples, and
indicates the number of samples, and  is the real value of -th sample. We use MSE to measure the average squared difference between the estimated values and the real values.
is the real value of -th sample. We use MSE to measure the average squared difference between the estimated values and the real values.
To find the value of  that minimizes the cost function, there are three methods:
that minimizes the cost function, there are three methods:
- Closed-form solution
- Gradient descent
- SVD and Moore-Penrose pseudo inverse
3.1. Closed-Form Solution
By closed-form solution, we mean using a normal equation in order to find the optimal value in only one step. Consequently, we can define the normal equation as:
(4) 
Here,  is an optimal solution of the MSE,
is an optimal solution of the MSE,  is a matrix that contains all
is a matrix that contains all  feature vectors, and
feature vectors, and  is a vector of target values containing all .
is a vector of target values containing all .
Since we need to compute the inverse of  matrix, which is
matrix, which is  matrix, where is number of features, the complexity is around
matrix, where is number of features, the complexity is around  . As a result, this method can become very slow with the increase in the number of features. In contrast, the complexity is linear regarding the number of samples in the training test.
. As a result, this method can become very slow with the increase in the number of features. In contrast, the complexity is linear regarding the number of samples in the training test.
To conclude, this method isn’t the best approach when we have a lot of features, or too many training samples to fit in memory.
3.2. Gradient Descent
Gradient descent is a technique in machine learning that we usually use in the context of optimization. We use this algorithm to find the minimum of a function by iteratively finding the direction with the steepest slope relative to the current location. In this case, we calculate the steepest slope to the current location using gradient descent.
Specifically, if our MSE cost function  has a form:
has a form:
(5) 
Then the gradient is:
(6) ![\begin{equation*} \frac{\partial J(\theta)}{\partial \theta} = \frac{2}{m} \sum_{i=1}^{m}[ (\theta}^{T} \cdot x^{(i)} - y^{(i)})x^{(i)}]. \end{equation*}](/wp-content/ql-cache/quicklatex.com-6b4eb990fea576c3380b231bbefa1868_l3.svg "Rendered by QuickLaTeX.com")
After that, we update weights with gradient multiplied by learning rate  :
:
(7) 
In our case, this approach leads to a global minimum because our cost function is a convex function, and therefore it has only one local minimum that’s also a global minimum. Gradient descent is prevalent because it’s widely applicable in many machine learning techniques, including neural networks. Despite that, it has some drawbacks.
Because gradient descent is an iterative approach, it can take time to reach the optimum solution. Also, the convergence depends on the learning rate .
To conclude, gradient descent or modifications of this method are widely used in machine learning, but in our case, there’s an even faster method that we’ll describe below.
3.3. SVD and Moore-Penrose Pseudo Inverse
One step before the normal equation:
(8) 
We have this equation:
(9) 
Since this equation almost never has an exact solution, because there are more samples than features, we approximate the vector as close as possible using Euclidean distance:
(10) 
We call this problem Ordinary Least Square (OLS). There are many ways of solving it, and one of them is using the Moore-Penrose pseudo inverse theorem. In particular, it says that for a system of linear equations,  , the solution with minimal
, the solution with minimal  norm
norm  is
is  , where
, where  is a Moore-Penrose pseudoinverse.
is a Moore-Penrose pseudoinverse.
Following that, we calculate the value , or in our example  , through singular value decomposition (SVD):
, through singular value decomposition (SVD):
(11) 
Here,  has the format
has the format  , where is the number of features and is the number of samples,
, where is the number of features and is the number of samples,  is an orthogonal matrix,
is an orthogonal matrix,  is a diagonal matrix and
is a diagonal matrix and  orthogonal matrix. Therefore, we calculate the Moore-Penrose pseudoinverse as:
orthogonal matrix. Therefore, we calculate the Moore-Penrose pseudoinverse as:
(12) 
Here,  is constructed from
is constructed from  by taking the reciprocal values of nonzero elements, and transposing the resulting matrix. Finally, to calculate linear regression weights, we use the formula:
by taking the reciprocal values of nonzero elements, and transposing the resulting matrix. Finally, to calculate linear regression weights, we use the formula:
(13) 
This method is used in the Scikit-learn package as a default for linear regression optimization because it’s speedy and numerically stable.
4. Regularization in Linear Regression
Regularization is a technique in machine learning that tries to achieve the generalization of the model. It means that our model works well not only with training or test data, but also with the data it’ll receive in the future. In summary, to achieve this, regularization shrinks the weights toward zero to discourage complex models. Accordingly, this avoids overfitting and reduces the variance of the model.
There are three main techniques for regularization in linear regression:
- Lasso Regression
- Ridge Regression
- Elastic Net
4.1. Lasso Regression
Lasso regression, or L1 regularization, is a technique that increases the cost function by a penalty equal to the sum of the absolute values of the non-intercept weights from linear regression. Formally, we define L1 regularization as:
(14) 
Here,  is a regularization parameter. Basically, controls the degree of regularization. In particular, the higher the is, the smaller the weights become. In order to find the best , we can start with
is a regularization parameter. Basically, controls the degree of regularization. In particular, the higher the is, the smaller the weights become. In order to find the best , we can start with  and measure the cross-validation error at each iteration, increasing the with a fixed value.
and measure the cross-validation error at each iteration, increasing the with a fixed value.
4.2. Ridge Regression
Similar to Lasso Regression, Ridge Regression, or L2 regularization, adds a penalty to the cost function. The only difference is that the penalty is calculated using the squared values of non-intercept weights from linear regression. Thus, we define L2 regularization as:
(15) 
Like with L1 regularization, we can estimate the parameter in the same way. The only difference between Lasso and Ridge is that Ridge converges faster, while Lasso is more commonly used for feature selection.
4.3. Elastic Net Regression
In summary, this method is a combination of the previous two approaches; it combines penalties from both Ridge and Lasso Regression. Therefore, we define Elastic Net regularization with the formula:
(16) 
In contrast to the previous two methods, here we have two regularization parameters,  and
and  . As such, we’ll have to find both of them.
. As such, we’ll have to find both of them.
5. Conclusion
In this article, we explored the term regression, its types, and linear regression in detail. Then we explained the three most commonly used regularization techniques, and the way of finding the regularization parameter. In conclusion, we learned the mathematics behind linear regression and regularization methods.