

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explore different types of data classification, the process involved, and the benefits and challenges it brings. We’ll use real-world examples to illustrate how data classification strategies have successfully safeguarded sensitive information.
Data classification is the process of categorizing data based on its sensitivity, function, and regulatory requirements. By identifying and labeling data, we can determine the appropriate security measures and access controls for protecting it.
This categorization plays a crucial role in ensuring information security in today’s digital landscape. Furthermore, it enables us to allocate resources effectively and implement measures to protect valuable assets.
Data can be classified based on its sensitivity, function, and compliance with regulatory requirements.
Sensitivity-based classification focuses on identifying and protecting data that’s considered highly confidential or private. For instance, personally identifiable information (PII) such as social security numbers and financial data falls into this category.
Failure to classify and protect such sensitive data can result in severe consequences, including identity theft and regulatory penalties.
Functional-based classification categorizes data based on its purpose within an organization. Sales data, HR records, and customer information are examples of data that may be classified functionally.
This classification approach facilitates efficient data management and enables appropriate access controls, ensuring that only authorized personnel can access specific data sets.
Regulatory-based classification involves classifying data in accordance with applicable laws and regulations. Organizations must comply with various data protection regulations such as the General Data Protection Regulation (GDPR) or the Health Insurance Portability and Accountability Act (HIPAA).
Failure to classify and protect data in alignment with these regulations can lead to legal repercussions and damage to an organization’s reputation.
Data classification levels are used to categorize and label data based on its sensitivity, confidentiality, and the potential impact of its exposure. The specific classification levels can vary depending on the organization and its industry:
| Classification Level | Description | Examples |
|---|---|---|
| Public | Information intended for public consumption.No special protection or restrictions are required. | Public website content, press releases |
| Internal | Data for internal use within the organization.Limited access within the organization. | Internal reports, non-sensitive emails, internal memos |
| Confidential | Data requiring protection from unauthorized access.Access should be limited to authorized personnel on a need-to-know basis. | Financial records, customer data, employee records |
| Restricted | Highly sensitive data with a higher risk if exposed.Access should be strictly controlled and limited to a select few individuals. | Trade secrets, intellectual property, sensitive legal documents |
| Top Secret/Highly Confidential | The highest level of classification for extremely sensitive and critical information.Access is tightly controlled and limited to a very small number of authorized personnel. | National security information, Classified government data |
The levels differ in the security measures we take to protect them. Each organization should tailor its data classification frameworks to suit its specific needs, industry regulations, and legal requirements.
Personal Identifiable Information (PII) refers to any information that can be used to identify an individual, either on its own or in combination with other available data.
Examples of PII include a person’s full name, date of birth, social security number, driver’s license number, passport number, and financial account information. When an individual provides their personal information to open a bank account, apply for a credit card, or sign up for an online service, they are disclosing their PII, which must be handled with utmost care to protect against unauthorized access or misuse.
Protected Health Information (PHI) refers to any individually identifiable health information that’s created, received, maintained, or transmitted by a covered entity, such as a healthcare provider, and is protected under the Health Insurance Portability and Accountability Act (HIPAA).
Protected Health Information (PHI) includes a range of individually identifiable health information, such as a patient’s medical records, lab test results, diagnostic reports, and treatment plans. It also encompasses personal identifiers like names, addresses, social security numbers, and even email addresses.
For instance, when a healthcare provider sends a patient’s medical history to a specialist for consultation or when a pharmacist fills a prescription and keeps a record of the medication dispensed, they are handling PHI and must ensure its protection and confidentiality.
The data classification process involves several steps. First, we need to identify data elements within the organization. Techniques such as data discovery tools and manual assessments can assist in this identification. Once identified, we establish data classification criteria, defining the factors used to categorize data based on sensitivity, function, or regulatory compliance.
The third step is doing the actual labeling:
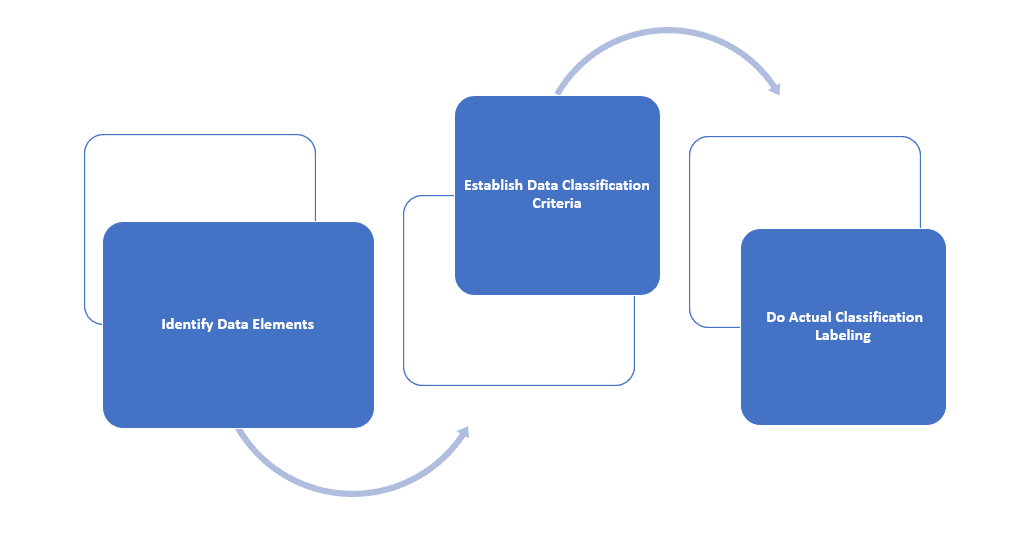
To do it efficiently, we can employ a combination of manual and automated methods. Manual methods involve user-driven classification or classification based on metadata. So, employees assess the data and assign appropriate classification labels. Automated methods utilize machine-learning algorithms and content analysis to classify data based on predefined rules and patterns.
Implementing data classification requires careful planning and integration with existing security controls and policies. We should develop strategies to ensure a seamless implementation process.
This includes defining roles and responsibilities, establishing clear guidelines, and providing adequate training to employees involved in data classification.
Data classification brings several benefits to organizations. First and foremost, it enhances data protection and security measures. By classifying data based on its sensitivity, we can allocate appropriate security controls and protocols to protect valuable information effectively. This reduces the risk of unauthorized access and data breaches.
Furthermore, data classification improves data governance and compliance. By aligning with regulatory requirements, we can demonstrate adherence to legal obligations, avoid penalties, and maintain customer trust. Additionally, data classification enables streamlined data management and access controls, allowing us to efficiently handle and retrieve data when needed.
However, it also poses certain challenges. Classifying diverse data types and formats can be complex, as each data element may have unique characteristics. Striking a balance between stringent security requirements and operational efficiency is another challenge. We need to ensure that data classification processes don’t hinder day-to-day operations or impede productivity. Moreover, maintaining consistent classification across different departments or business units can be a daunting task.
Establishing a robust data classification framework is essential. This involves defining clear categories and labels based on sensitivity, function, and regulatory compliance. It’s crucial to develop comprehensive guidelines and procedures that outline the classification process in detail.
Training and awareness programs play a vital role in ensuring successful implementation. We should educate employees about the importance of data classification, its impact on security, and their roles and responsibilities in the classification process. Training should also focus on imparting knowledge about classification criteria and the correct methods for classifying data.
Regular evaluation and review of data classification policies and procedures are crucial for maintaining an effective classification system. We should conduct periodic audits and assessments to identify any gaps or inconsistencies. This allows for continuous improvement and adjustment of classification practices to meet evolving security and regulatory requirements.
In this article, we discussed data classification in detail. It’s a critical aspect of modern security practices. By implementing an effective data classification framework, we protect sensitive information, enhance data governance, and comply with regulatory requirements.
While data classification brings its challenges, the benefits far outweigh them. By following best practices and learning from real-world examples, we can ensure that our data remains secure in the dynamic digital landscape.