

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll talk about data lake, a relatively new concept that harnesses the strength of big data technology and combines it with the nimbleness of self-service. Mainly, we’ll discuss its essential parts and architecture, its benefits, and its shortcomings. We will present also the main differences between a data lake and a data warehouse.
2. Overview of Data Lake
A data lake is a principal storage depository that allows you to store all your unstructured, semi-structured, and structured data at any scale.
In a data lake, we store data without having to structure it. A data lake runs different types of analyses, from dashboards and visualizations to big data processing, real-time analysis, and machine learning to guide better decisions.
Data lake reduces long-term operating costs and enables economical file storage.
3. Why Data Lake?
A data lake is a repository that holds large volumes of raw data in its native format until needed by analytical applications. Data lakes employ a flat design to store data, typically in file or object storage, as opposed to traditional data warehouses, which store data in hierarchical dimensions and tables. Users have more options to manage, store, and use their data.
Here are some other considerations for building a data lake:
- The diverse data structures in a data lake provide data analysts with a stronger and richer quality of analysis.
- There is no need to use a data lake to model data in an enterprise-wide schema.
- Data lakes provide the flexibility of data analysis and the ability to transform structured data into unstructured data not found in data warehouses.
- Machine learning and deep learning are used today to create earnings forecasts.
- Leveraging data lakes can give companies a competitive advantage.
4. Architecture and Essential Parts of Data Lake Solution
4.1. Essential Parts of Data Lake
A data lake contains a lot of data. Therefore, it’s crucial to tag items with metadata to make them reachable in the future. Data lake structures vary, but the goal is to make data easily discoverable and usable.
A data lake architecture incorporates the following characteristic to guarantee the functionality and keep it from becoming a data swamp:
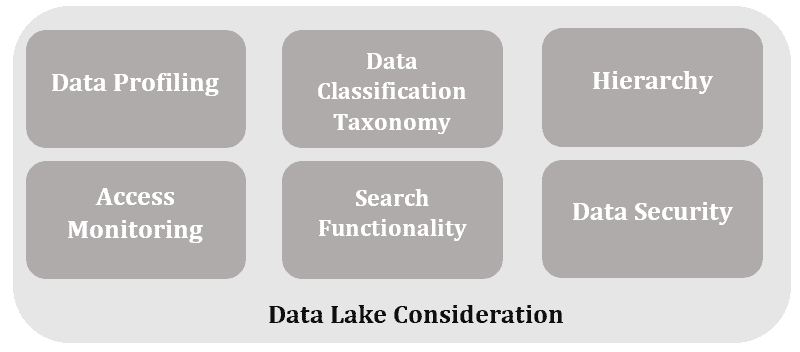
- Data Profiling: Reveals information on item quality and classification.
- Data Taxonomy: Describe the data types, user groups, and use cases.
- Hierarchy: Organize files and apply naming conventions.
- Access Monitoring: Monitor user access to the data lake and produce time- and location-specific notifications.
- Search Functionality: Enables people to locate data.
- Data Security: Includes security measures like encryption, access control, and authentication to prevent unauthorized access.
4.2. Data Lake Architecture
All data lakes consist of two components: compute and storage. Both can be in the cloud or on-premises. A data lake architecture can accommodate unstructured data and various data structures from several sources across the enterprise. Below is a conceptual diagram of the data lake structure.
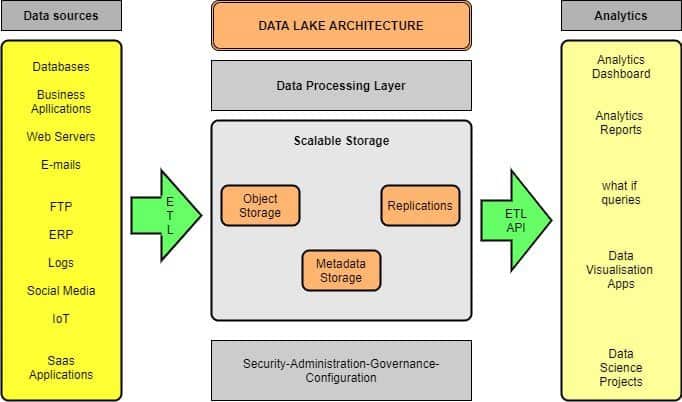
5. Data Lake Versus Data Warehouse
Because of their similar fundamental goals and functions, a data lake and a data warehouse are frequently confused:
- The purpose of both is to develop a centralized data repository that will supply information to different applications.
- They both serve as storage repositories for the different data stores in an enterprise.
The two are suitable for various settings because of the basic differences between them.
| Data Lake | Data Warehouse | |
|---|---|---|
| Accessibility and modification | Simple and Flexible; Very accessible and fast to update; Easily adaptable to change. | Complex and rigid; More complicated and expensive modifications; Requires a lot of resources to modify it later as requirements change. |
| Schema | Schema-on-read; A data lake doesn’t have a predefined structure. Therefore, it can store data in its original format. | Schema-on-write — schema is structured and organized. |
| Data Structure | Raw | Processed |
| Users | Data scientists and Engineers | Business professionals |
| Analysis | Machine learning, deep learning, data visualization, Predictive analytics, big data analytics, BI. | BI, Data visualization, data analytics. |
6. Benefits and Shortcomings of a Data Lake
6.1. Benefits of the Data Lake
A data lake operates on a principle named schema-on-read. It indicates that data don’t need to be fitted into a specified schema before storage. This characteristic saves a lot of time. However, it also allows storing data in any format. Data lakes are complex because they do not organize data in a clear structure.
Data scientists and analysts use data lakes to access, analyze and prepare data faster and more accurately (flexible analytics). For data professionals, this availability of data in a variety of non-traditional formats provides the ability to access data for various use cases, such as fraud detection, sentiment analysis, speech recognition, or targeted advertising.
6.2. Shortcomings of a Data Lake
The risks to data lakes are security and access control. Sometimes data can be put into the lake without supervision, as some data may have privacy and governance needs.
There is no history of past analytics performed on the data. As a result, storage and processing expenses can increase. Hardware, space limitations, data center configuration, cost, storage scalability, and resource budgeting are problems that on-premises data lakes must deal with.
7. Conclusion
In this article, we discussed data lakes. A data lake is a repository that can store large volumes of structured, semi-structured, and unstructured data. The main goal of building a data lake is to provide data scientists and analysts with a vintage view of the data.