

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll discuss a classic problem in reinforcement learning: the credit assignment problem. We’ll present an example that demonstrates the problem.
Finally, we’ll highlight some solutions to solve the credit assignment problem.
Reinforcement learning (RL) is a subfield of machine learning that focuses on how an agent can learn to make independent decisions in an environment in order to maximize the reward. It’s inspired by the way animals learn via the trial and error method. Furthermore, RL aims to create intelligent agents that can learn to achieve a goal by maximizing the cumulative reward.
In RL, an agent applies some actions to an environment. Based on the action applied, the environment rewards the agent. After getting the reward, the agents move to a different state and repeat this process. Additionally, the reward can be positive as well as negative based on the action taken by an agent:
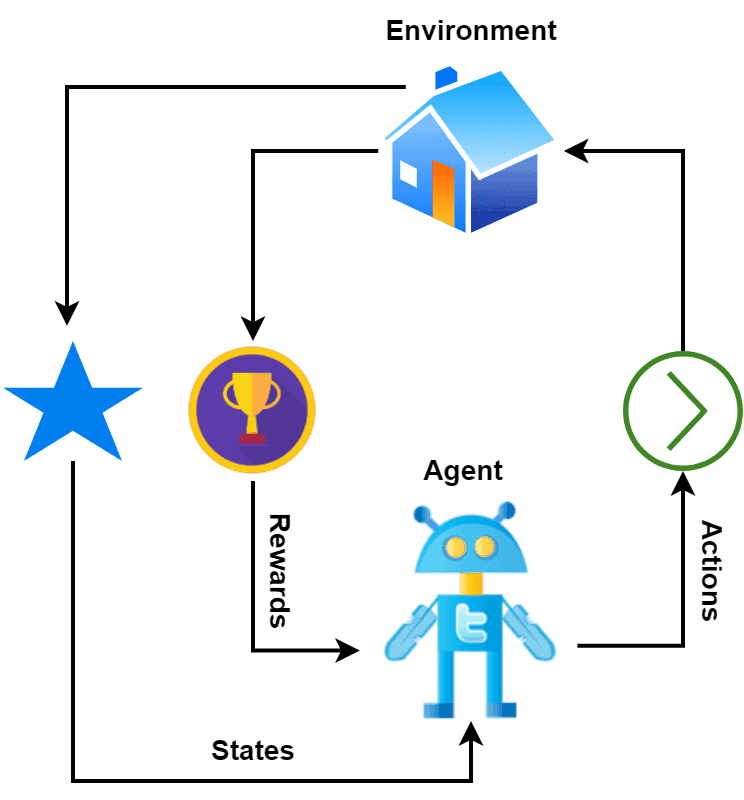
The goal of the agent in reinforcement learning is to build an optimal policy that maximizes the overall reward over time. This is typically done using an iterative process. The agent interacts with the environment to learn from experience and updates its policy to improve its decision-making capability.
The credit assignment problem (CAP) is a fundamental challenge in reinforcement learning. It arises when an agent receives a reward for a particular action, but the agent must determine which of its previous actions led to the reward.
In reinforcement learning, an agent applies a set of actions in an environment to maximize the overall reward. The agent updates its policy based on feedback received from the environment. It typically includes a scalar reward indicating the quality of the agent’s actions.
The credit assignment problem refers to the problem of measuring the influence and impact of an action taken by an agent on future rewards. The core aim is to guide the agents to take corrective actions which can maximize the reward.
However, in many cases, the reward signal from the environment doesn’t provide direct information about which specific actions the agent should continue or avoid. This can make it difficult for the agent to build an effective policy.
Additionally, there’re situations where the agent takes a sequence of actions, and the reward signal is only received at the end of the sequence. In these cases, the agent must determine which of its previous actions positively contributed to the final reward.
It can be difficult because the final reward may be the result of a long sequence of actions. Hence, the impact of any particular action on the overall reward is difficult to discern.
Let’s take a practical example to demonstrate the credit assignment problem.
Suppose an agent is playing a game where it must navigate a maze to reach the goal state. We place the agent in the top left corner of the maze. Additionally, we set the goal state in the bottom right corner. The agent can move up, down, left, right, or diagonally. However, it can’t move through the states containing stone:
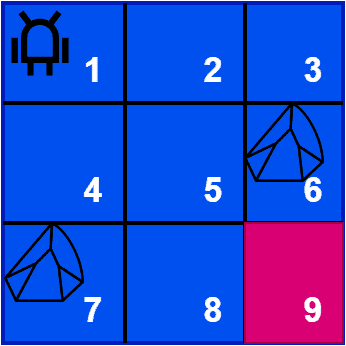
As the agent explores the maze, it receives a reward of +10 for reaching the goal state. Additionally, if it hits a stone, we penalize the action by providing a -10 reward. The goal of the agent is to learn from the rewards and build an optimal policy that maximizes the gross reward over time.
The credit assignment problem arises when the agent reaches the goal after several steps. The agent receives a reward of +10 as soon as it reaches the goal state. However, it’s not clear which actions are responsible for the reward. For example, suppose the agent took a long and winding path to reach the goal. Therefore, we need to determine which actions should receive credit for the reward.
Additionally, it’s challenging to decide whether to credit the last action that took it to the goal or credit all the actions that led up to the goal. Let’s look at some paths which lead the agent to the goal state:
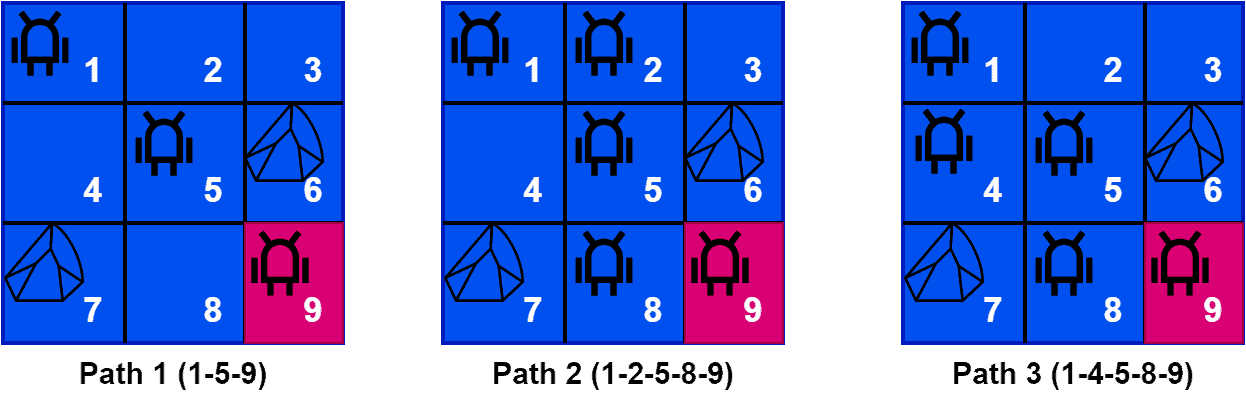
As we can see here, the agent can reach the goal state with three different paths. Hence, it’s challenging to measure the influence of each action. We can see the best path to reach the goal state is path 1.
Hence, the positive impact of the agent moving from state 1 to state 5 by applying the diagonal action is higher than any other action from state 1. This is what we want to measure so that we can make optimal policies like path 1 in this example.
The credit assignment problem is a vital challenge in reinforcement learning. Let’s talk about some popular approaches for solving the credit assignment problem. Here we’ll present three popular approaches: temporal difference (TD) learning, Monte Carlo methods, and eligibility traces method.
TD learning is a popular RL algorithm that uses a bootstrapping approach to assign credit to past actions. It updates the value function of the policy based on the difference between the predicted reward and the actual reward received at each time step. By bootstrapping the value function from the predicted rewards of future states, TD learning can assign credit to past actions even when the reward is delayed.
Monte Carlo methods are a class of RL algorithms that use full episodes of experience to assign credit to past actions. These methods estimate the expected value of a state by averaging the rewards obtained in the episodes that pass through that state. By averaging the rewards obtained over several episodes, Monte Carlo methods can assign credit to actions that led up to the reward, even if the reward is delayed.
Eligibility traces are a method for assigning credit to past actions based on their recent history. Eligibility traces keep track of the recent history of state-action pairs and use a decaying weight to assign credit to each pair based on how recently it occurred. By decaying the weight of older state-action pairs, eligibility traces can assign credit to actions that led up to the reward, even if they occurred several steps earlier.
In this tutorial, we discussed the credit assignment problem in reinforcement learning with an example. Finally, we presented three popular solutions that can solve the credit assignment problem.