

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
How to Train ChatGPT on Custom Data: A RAG Application
Last updated: September 5, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
Modern customer support chatbots are evolving beyond static FAQ bots into intelligent assistants powered by Large Language Models (LLMs). However, out-of-the-box LLMs have certain constraints. They’re only aware of the information in their training dataset.
In this tutorial, we’ll build a ChatGPT-powered support chatbot that uses Retrieval-Augmented Generation (RAG) to deliver accurate, up-to-date answers from a custom textual database. Throughout this guide, we’ll cover how to:
- ingest and index PDFs and CSVs into a FAISS (Facebook AI Similarity Search) vector store
- perform semantic retrieval of the most relevant text chunks when a user submits a query
- assemble the retrieved chunks into a context prompt tailored for ChatGPT
- run a conversational loop that grounds each response in our own data
By the end of this tutorial, we’ll have a complete end-to-end RAG pipeline that enables ChatGPT to reference and cite domain-specific materials at query time.
2. Motivation and Project Statement
Despite their impressive versatility, general-purpose language models are bound by a static training corpus and a firm knowledge cutoff. Consequently, they may deliver outdated information and, in some cases, even generate ungrounded or fabricated responses.
Simple “file upload” solutions can seem appealing at first glance. These solutions typically allow users to upload documents directly to a chatbot to be processed as a single unit without sophisticated indexing or chunking. However, this approach doesn’t provide genuine semantic search or relevance-based ranking across extensive document collections. Moreover, it can’t partition content into fine-grained, metadata-tagged segments, which makes source tracing opaque. Finally, any update to the underlying documents forces a complete re-upload.
To overcome these challenges, we adopt a Retrieval-Augmented Generation framework with vector search:
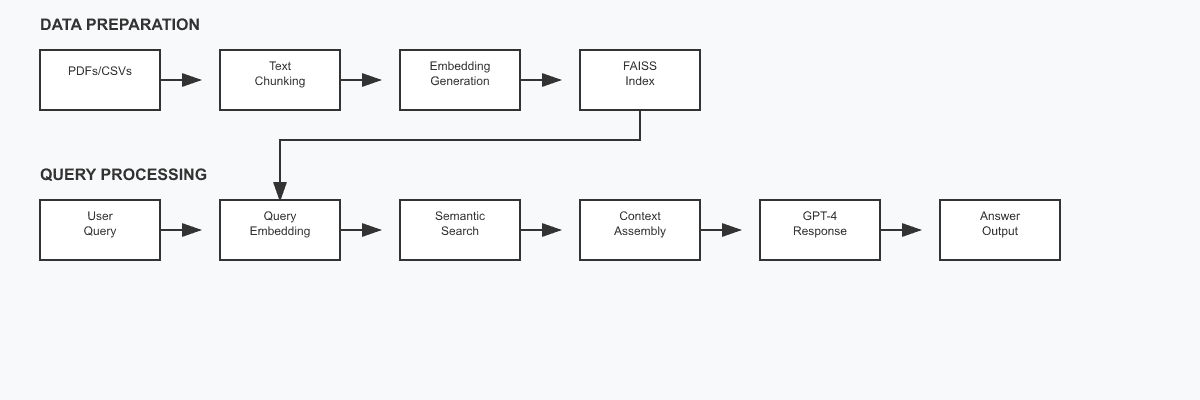
Our approach follows a systematic process: we split documents into manageable chunks and convert each chunk into vector embeddings that capture semantic meaning. When a user submits a query, we transform it into a vector representation and search for the most similar vectors in our FAISS index. We then retrieve the corresponding text chunks and inject them as context into ChatGPT’s prompt, enabling the model to generate responses grounded in our knowledge base rather than relying solely on its training data.
3. Project Setup
Now, let’s establish a Python environment, define dependencies, obtain OpenAI credentials, and centralize reusable configuration values.
3.1. Dependencies
First, we create a virtual environment and install the required libraries:
mkdir gpt4-support-bot && cd gpt4-support-bot
mkdir src docs vector_store
python -m venv venv
source venv/bin/activate # on Windows: venv\Scripts\activate
pip install openai langchain faiss-cpu PyPDF2 pandas numpy
We use the following libraries:
- openai – official client for ChatGPT and OpenAI embedding models
- langchain – high-level abstractions for LLM orchestration, conversational memory, and vector stores
- faiss-cpu – FAISS (CPU build) enabling efficient similarity search over dense vectors
- PyPDF2 – lightweight PDF parser for ingesting documentation
- pandas – tabular data processing, particularly useful when reading CSV articles
3.2. Directory Structure
We’ll use the following project structure, where each component serves a clear purpose in the RAG pipeline:
gpt4-baeldung-support-bot/
- venv/
- vector_store/ # FAISS index after ingestion
- docs/
- articles.csv # metadata: title, author, pdf_name, etc.
- baeldung.pdf
- threading.pdf # Threading article
... # additional PDFs
- src/
- ingest.py # builds the index
- chat.py # main chatbot loop
- cli.py # command-line interface
- config.py
- pdf_utils.pyDuring ingestion, the loader reads each row in articles.csv, fetches the corresponding PDF from docs/, splits it into overlapping chunks, embeds every chunk, and stores the result in vector_store/. Afterward, chat.py retrieves the TOP_K most relevant chunks for any incoming question and supplies them to the chosen GPT model.
3.3. OpenAI API Key
Next, we need an API key from the OpenAI dashboard. This key is used to make requests to the OpenAI API:
OPENAI_API_KEY="sk-..."
Instead of hardcoding the key, it is better to store it in files like an .env file or an operating-system environment variable, keeping credentials out of the source. For simplicity, we’ll store it in a constant OPENAI_API_KEY in a configuration file, config.py.
3.4. Configuration
Centralized constants in config.py clarify model names, storage directories, and text-splitting parameters:
OPENAI_API_KEY = "sk-..."
openai.api_key = OPENAI_API_KEY
GPT_MODEL = "gpt-4-0613"
EMBEDDING_MODEL = "text-embedding-ada-002"
VECTOR_DIR = "../vector_store"
CHUNK_SIZE = 1000
CHUNK_OVERLAP = 100
ARTICLES_CSV = "../docs/articles.csv"
PDF_DIR = "../docs/"
Here:
- GPT_MODEL selects the chat completion model. We opted for GPT-4-0613 in this tutorial;
- EMBEDDING_MODEL sets the vector-embedding model, which translates text into high-dimensional vectors;
- VECTOR_DIR names the folder where FAISS stores the vector index for fast retrieval;
- CHUNK_SIZE and CHUNK_OVERLAP drive the sliding-window tokenizer, ensuring that text near a boundary stays intelligible in adjacent chunks;
- PDF_DIR holds the full-text PDFs that supply rich contextual information;
- ARTICLES_CSV contains structured metadata: title, author, publication, and file name referencing those PDFs;
- TOP_K fixes the number of most-similar chunks that feed into each ChatGPT prompt, balancing context width against token limits.
4. Loading and Preparing Domain Data
Now, we’re ready for data ingestion, vector indexing, and prompt-answering logic.
We use both CSV and PDF files to demonstrate multi-source RAG capabilities: the CSV provides structured metadata (titles, categories, reading times) for quick filtering and categorization, while PDFs contain the full article content for detailed technical explanations.
4.1. Loading Structured Data
First, we transform CSV entries (articles.csv) into text chunks:
raw_chunks: list[str] = []
metas: list[dict] = []
art_df = pd.read_csv(cfg.ARTICLES_CSV)
for _, row in art_df.iterrows():
payload = (
f"Article ID: {row['article_id']}\n"
f"Title: {row['title']}\n"
f"Category: {row['category']}\n"
f"Reading time: {row['reading_time_minutes']} min\n"
f"Summary: {row['summary']}"
)
raw_chunks.append(payload)
metas.append({"source": "articles.csv", "article_id": row['article_id']})Rather than embedding raw CSV rows, we reformat structured data into narrative mini-paragraphs. This transformation enhances semantic matching by providing natural language context that embedding models can better understand. Each record maintains metadata references to enable source attribution in the chatbot’s responses.
4.2. Incorporating Unstructured Content
Next, we process PDF documents:
for pdf_path in Path(cfg.PDF_DIR).glob("*.pdf"):
text = pdf_to_text(pdf_path)
raw_chunks.append(text)
metas.append({"source": pdf_path.name})
The pdf_to_text utility extracts raw text from every page of a PDF, ensuring we capture all relevant content. This function leverages PyPDF2 to handle the extraction.
By joining the extracted text with newlines, we maintain logical separation between pages while creating a consolidated document that can be further processed.
4.3. Semantic Chunking Strategy
To facilitate effective retrieval, we need to break large documents into smaller, semantically cohesive parts:
splitter = RecursiveCharacterTextSplitter(
chunk_size = cfg.CHUNK_SIZE,
chunk_overlap = cfg.CHUNK_OVERLAP
)
chunks, chunk_meta = [], []
for txt, meta in zip(raw_chunks, metas, strict=True):
pieces = splitter.split_text(txt)
chunks.extend(pieces)
chunk_meta.extend([meta] * len(pieces))Here, we employ LangChain’s RecursiveCharacterTextSplitter with the following configuration:
- CHUNK_SIZE = 1000 (characters) is a target guideline rather than a hard limit. The RecursiveCharacterTextSplitter attempts to break text at natural boundaries (paragraphs, sentences, then words) while staying close to this target. If a single sentence exceeds 1000 characters, it will be kept intact to preserve semantic meaning, potentially creating a chunk larger than the target size.
- CHUNK_OVERLAP = 100 means adjacent chunks will have overlapping content, where the last 100 characters of one chunk are the first 100 characters of the next one. This overlap ensures that sentences or concepts spanning chunk boundaries aren’t lost, maintaining semantic continuity across the dataset.
The splitter’s recursive nature means it tries multiple splitting strategies in order of preference: first by paragraphs, then by sentences, then by words, and finally by characters if necessary. This approach prioritizes semantic coherence over strict size limits, ensuring chunks remain meaningful and contextually complete.
For every chunk, we maintain its corresponding metadata, establishing the links between vector embeddings and their sources.
5. Embeddings and Vector Indexing with FAISS
Effective RAG relies on accurate and fast information retrieval. We achieve this by converting textual information into numerical vector representations called embeddings. Then, we search the vector database to find the best-matching vectors for our query.
In this tutorial, we’ll use FAISS to perform semantic searches rapidly.
5.1. Generating Embeddings
Embeddings translate textual content into dense vectors that capture the semantic meaning of the text.
In the ideal case, semantically related pieces of text produce embeddings close to each other in vector space.
We use OpenAI’s text-embedding-ada-002 model because it is efficient and suitable for generating precise embeddings that aid in accurate semantic search.
Here’s how we generate embeddings from textual chunks:
embeds = []
for piece in chunks:
embedding_response = client.embeddings.create(
model=cfg.EMBEDDING_MODEL,
input=piece
)
embeds.append(embedding_response.data[0].embedding)
embeds_np = np.array(embeds, dtype="float32")
Each embedding vector has 1,536 dimensions, which is a balance between capturing a rich variety of semantic nuances and remaining computationally efficient. Each of those 1,536 slots represents a learned feature of the text (e.g., topic, tone, entities), so semantically similar chunks end up as nearby points in this high-dimensional space.
5.2. Building and Persisting the FAISS Index
Once we have embeddings for our document chunks, the next step is constructing a FAISS vector index. FAISS allows rapid searching of these high-dimensional embedding vectors, efficiently finding semantically similar content.
Here’s how we create and save the FAISS index:
index = faiss.IndexFlatL2(len(embeds_np[0]))
index.add(embeds_np)
Path(cfg.VECTOR_DIR).mkdir(parents=True, exist_ok=True)
faiss.write_index(index, os.path.join(cfg.VECTOR_DIR, "baeldung.idx"))
with open(os.path.join(cfg.VECTOR_DIR, "chunks.pkl"), "wb") as f:
pickle.dump({"texts": chunks, "meta": chunk_meta}, f)The above ingestion process must be completed before running the chatbot. So, we first execute python src/ingest.py to build the FAISS index and process all documents in our knowledge base. This creates the baeldung.idx file and chunks.pkl metadata that the chat_round() function depends on.
6. Retrieving Context with Semantic Search
Upon receiving a user query, the chatbot retrieves relevant context from the indexed embeddings. We do this by transforming the query into an embedding vector and searching for semantically similar document chunks using FAISS.
Here’s our implementation:
def retrieve_context(question, k=3):
q_emb = client.embeddings.create(
model=cfg.EMBEDDING_MODEL,
input=question
).data[0].embedding
D, I = index.search(np.array([q_emb], dtype="float32"), k)
relevant_chunks = []
for i in I[0]:
if i == -1:
continue
relevant_chunks.append({"text": all_texts[i], "meta": all_meta[i]})
return relevant_chunksThis function embeds the query, performs a similarity search against the FAISS index, and returns the most relevant chunks along with their metadata:
- k=3: The number of most similar chunks to retrieve. This parameter controls how much context we provide to ChatGPT – too few chunks might miss relevant information, while too many could exceed token limits or introduce noise
- D, I = index.search(): FAISS returns two arrays: D contains the distances (similarity scores) between the query and each retrieved chunk, while I contains the indices of the most similar chunks in our original dataset. Lower distances indicate higher similarity
- np.array([q_emb], dtype=”float32″): The query embedding must be converted to a NumPy array with float32 precision to match the data type used when building the FAISS index. The embedding is wrapped in brackets [q_emb] because FAISS expects a 2D array where each row represents a query vector, even when searching with a single query
- if i == -1: FAISS returns -1 when fewer than k similar items are found, which we skip to avoid indexing errors
The results provide the context for the chosen GPT model, enabling the chatbot to answer user queries accurately, even if the topic wasn’t explicitly covered in ChatGPT’s training data.
While FAISS is efficient and effective for smaller datasets, larger or dynamically updated datasets might benefit from a persistent vector database such as Pinecone, Weaviate, or Chroma. They are suitable for production-level deployments.
In a Java-based context, Spring AI integrates with these vector databases, providing similar retrieval capabilities tailored to enterprise applications.
7. Processing User’s Query
Finally, we send the chunks and their metadata to ChatGPT for a textual answer.
Let’s define our main function chat_round, which will handle a query step by step:
def chat_round(user_question: str, history: Optional[list[dict]] = None) -> str:
history = history or []
relevant_chunks = retrieve_context(user_question)
context_text = ""
for chunk in relevant_chunks:
meta = chunk["meta"]
source = meta.get("source", "Unknown")
article_id = meta.get("article_id", "")
context_text += f"[Source: {source}"
if article_id:
context_text += f", Article ID: {article_id}]"
else:
context_text += "]"
context_text += f"\n{chunk['text']}\n\n"
system_content = (
"You are customer-support assistant. Answer questions about "
"Spring, Java, and web development. Use the following articles "
"as context for your answer.\n\n"
f"Knowledge Base Context:\n{context_text}\n\n"
"If the context doesn't contain relevant information, use your general knowledge "
"but prioritize the context's perspective."
)
system_msg = {"role": "system", "content": system_content}
history_msgs = history.copy()
history_msgs.insert(0, system_msg)
history_msgs.append({"role": "user", "content": user_question})
resp = client.chat.completions.create(
model=cfg.GPT_MODEL,
messages=history_msgs,
temperature=0
)
return resp.choices[0].message.contentWhen a user asks a question, our system retrieves relevant articles and documentation from our knowledge base. This information is injected into the prompt as context, allowing the model to ground its responses in accurate, domain-specific knowledge.
7.1. Using the Chat Function
Once the FAISS index is built and the chat function is defined, we can use our RAG-powered chatbot. Here’s an interactive loop:
def main():
print("Technical Support Chat (type 'quit' to exit)")
conversation_history = []
while True:
user_input = input("\nUser: ").strip()
if user_input.lower() == 'quit':
break
response = chat_round(user_input, conversation_history)
print(f"Support: {response}")
# Maintain conversation history
conversation_history.append({"role": "user", "content": user_input})
conversation_history.append({"role": "assistant", "content": response})
if __name__ == "__main__":
main()Let’s run the cli.py file to start our chatbot in an interactive mode. We can query it with some information about our domain to get a response:
User: What is a green thread ?
We’ll get the following or a similar response:
A green thread refers to a type of thread that is scheduled by a runtime library or virtual machine (VM) instead of natively by the underlying operating system. Green threads emulate multithreaded environments without relying on any native OS capabilities, and they are managed in user space instead of kernel space, allowing for more threads to be created as compared to native system threads. Java used green threads in its early days, but modern versions of Java use native OS threads instead.While the implementation above provides a solid foundation, several optimization strategies can significantly enhance accuracy and performance.
We can combine semantic vector search with traditional keyword-based retrieval methods using BM25 (Best Matching 25). This hybrid approach captures both semantic similarity and exact keyword matches, which is particularly valuable for technical queries with precise terminology. Libraries like Elasticsearch or Weaviate provide built-in hybrid search capabilities, while custom implementations can use rank-bm25 alongside our existing FAISS index.
Another option is a two-stage retrieval process with reranking. After retrieving initial candidates, we can apply cross-encoder models like sentence-transformers/ms-marco-MiniLM-L-6-v2 to rerank results based on query-document relevance scores.
Additionally, query expansion techniques can broaden retrieval coverage by leveraging ChatGPT to generate multiple query variations, then retrieving context for each variation and deduplicating results. Combined, these approaches often yield 10-20% improvement in retrieval accuracy and double the likelihood of finding relevant context for complex user questions.
8. Conclusion
In this article, we built a ChatGPT-powered chatbot that can answer questions using a custom knowledge base. We walked through ingesting documents, generating embeddings, and storing them in a FAISS vector index. Using Retrieval Augmented Generation (RAG), our chatbot finds relevant context for each query and uses ChatGPT to produce a grounded answer.
This approach provides a blueprint for building AI assistants specific to custom data. We can extend it by adding more document types, implementing memory for conversations, history summary, and other features to improve and tailor the assistant. As usual, all code is available over on GitHub.