

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Automatic Keyword and Keyphrase Extraction
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll explore the techniques and algorithms for keyword and keyphrase extraction in a given text. Normally these fall under the larger umbrella of Information Retrieval (IR), and are often accomplished with Natural Language Processing (NLP) techniques.
Keywords are basically words that describe the essence of a text. Keyphrase has a similar meaning, but instead of single words, these consist of multiple words. Keyphrase extraction is the process of automatically identifying key phrases in a given text.
2. What Are IR and NLP?
Information Retrieval (IR) is the process of obtaining resources relevant to the information need. For instance, a search query on a web search engine can be an information need. The search engine can return web pages that represent relevant resources.
We often perform IR using one of the techniques in Natural Language Processing (NLP). NLP is a sub-field of artificial intelligence which concerns the machine interpretation of human languages. In fact, it sits at the interaction of linguistics, computer science, and artificial intelligence.
Machines are more capable of understanding programming languages because they follow their grammar strictly. Conversely, human languages tend to carry a lot of ambiguity and imprecise characteristics. This makes processing human languages difficult for machines.
NLP offers many techniques and algorithms to perform syntactic and semantic analysis of texts in natural languages. We can use the available algorithms to collect essential data and perform sophisticated tasks like spelling and grammatical correction, language translations, text summarization, and keyphrase extraction.
3. Basics Concepts
Before discussing the techniques and algorithms in NLP for keyphrase extraction, let’s go through some of the basic concepts.
3.1. Jargons in Lingustics
Since NLP overlaps with linguistics to a large extent, they share a fair amount of jargon. Let’s understand a few terms that will interest us in this tutorial.
A text in a natural language like English comprises sentences. A sentence further comprises words and punctuation. We refer to these words and punctuation as tokens. Please note that token has a more general meaning in linguistics. Furthermore, each distinct token is known as a type.
A set of words in a language is known as the vocabulary. A sequence of tokens is often of interest in computational linguistics. A sequence of 1-token is known as a unigram, a sequence of two tokens is known as a bigram. Similarly, a sequence of n tokens is known as an n-gram.
A collection of structured and principled text from a language is known as the corpus. The plural of the corpus is corpora. Corpora have immense value in corpus linguistics. There are several corpora in English and other languages that are available online for us to use.
3.2. Language Models
Language modeling is the development of probabilistic models that can predict the next word in the sequence given the words that precede it. A language model learns the probability of word occurrence based on examples of text, like corpora.
A language model puts the probability measure to strings drawn from a vocabulary. These strings can be single words, short sequences of words, complete sentences, or even paragraphs.
The traditional way of creating a language model is statistical language modeling. For instance, we can calculate the probability of a sequence of words with the help of the chain rule of probability:

Since calculating the probability with a long sequence of preceding words may prove impractical, we often use approximations. An n-gram language model predicts the probability of a given word by approximating the number of preceding words to n-1:

In the recent past, we often accomplished creating a language model using neural networks and thus refer to them as neural language modeling.
3.3. Relevance Functions
In many of the NLP algorithms, we have to determine the relevance of a sequence of tokens to a text. There are several statistical and probabilistic measures that we can use to determine it.
Term Frequency-Inverse Document Frequency, TF-IDF in short, is a statistical measure that indicates how relevant a word is to a text in a corpus. Term frequency refers to the count of instances a word appears in a text. Inverse document frequency refers to how common this word is in all the texts in a corpus.
The TF-IDF score of a word (t) in a text (d) as part of a corpus (D) is a multiplication of these two statistics, term frequency, and inverse document frequency:

There are several ways to define the term frequency and the inverse document frequency mathematically with various weighing and normalization schemes.
Okapi Best Match 25, or simply BM25, is a ranking function based on the probabilistic retrieval framework and it improves the classical TF-IDF measure. It basically ranks a set of texts based on the query terms appearing in each text regardless of proximity.
3.4. Word Similarity
For several NLP tasks, we must be able to determine how similar two words or phrases are to each other. In this context, similarity can mean multiple things. We can be interested in lexical similarity or semantic similarity.
Some popular algorithms to determine the lexical similarity of words include Jaccard Similarity, Levenshtein distance, and cosine similarity. For instance, cosine similarity works by measuring the cosine of the angle between two vectors projected in multi-dimensional space.
The vectors here are the numerical representations of the text. There are several ways to represent texts as numerical vectors. One of the simplest approaches is one-hot encoding. However, these ways fail to capture the semantic value of the text.
Word embeddings prove to be more efficient in representing words as numerical vectors by capturing their meaning. A highly cited example is:

Word2Vec is a popular algorithm developed by Tomas Mikolov that uses neural networks to generate word embeddings from a large text corpus. Language models are also quite effective in generating word embeddings.
4. Data Cleanup and Preparation
Before we can apply one of the algorithms, it’s often necessary to clean up and prepare the input data. This is because text with natural languages can be pretty disorganized, making it difficult for an algorithm to parse and process it efficiently and give us the results we expect.
We will go through some of the common techniques in NLP that we can use for the task of keyphrase extraction.
4.1. Tokenization
Tokenization refers to the process of breaking down a text into smaller tokens. This may involve breaking paragraphs into sentences, and sentences into words, parts of words, or even characters. This is a fundamental step towards creating a vocabulary that is necessary for performing any task in NLP:

One of the most important considerations in tokenization is identifying boundaries. For instance, in English, words are separated by white spaces, but that may not be true in other languages. Depending upon the level we want to break a text into, we may choose word tokenization, character tokenization, or sub-word tokenization.
4.2. Stemming & Lemmatization
In natural languages, words can take different forms that alter their grammatical usage, but not their semantic value. For instance, travel, traveling, travels, and traveled have different usages, but similar meanings. In the field of NLP, these forms of a word are known as inflectional forms. For IR, it’s often desirable to reduce all of these words to their base form:
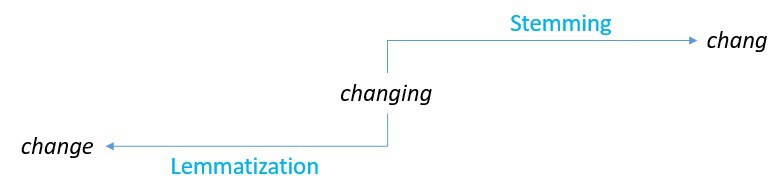
The purpose of both stemming and lemmatization is to generate the base form of inflected words in a text. Stemming is cruder in adopting a heuristic approach by chopping off the word ending to get their base form. Lemmatization is more sophisticated and uses a vocabulary and morphological analysis of words to achieve the same.
4.3. Part-of-Speech Tagging (POST)
Part-of-Speech, or simply PoS, is a category of words with similar grammatical properties. In English, we usually identify nine parts of speech, such as noun, verb, article, adjective, and others. We can use the same word in a sentence as a noun or as a verb. For instance, see the usage of the word park in this sentence:

Part-of-speech tagging is basically the process of marking up a word in a text as corresponding to a particular part-of-speech depending upon its usage. Normally we use a rule-based or stochastic tagger algorithm to achieve this automatically. PoS tagging has several applications in NLP.
4.4. Named Entity Recognition (NER)
A named entity refers to a real-world object like cities, persons, or organizations. For instance, Baeldung, London, Jack Daniel, all of these can be called named entities in any text. In some cases, named entities may also include temporal and numerical expressions, like 400 nautical miles, or the year 2020. For example, let’s analyze the following sentence:

Named entity recognition is the process of identifying named entities in unstructured texts. There are several rule-based and statistical algorithms for automatic named entity recognition. Statistical named entity recognition typically includes supervised and semi-supervised machine learning models. This has a lot of applications in IR like content classification, indexing, and recommendations.
4.5. Collocation Extraction
Collocation basically refers to a sequence of tokens that happens to appear together in a corpus more often than what we can dismiss as coincidence. This has more of a cultural bearing than grammatical orientation. For instance, we use phrases like “strong tea” and “powerful computer” quite often in general practice. There are six main types of collocations:

Collocation extraction is the task of automatically identifying all collocations in a text using an algorithm. One of the simplest algorithms to identify collocations uses their frequency in a corpus. More sophisticated algorithms can employ mean and variance-based methods, and pointwise mutual information measures. This can have useful applications in IR tasks.
5. Algorithms for Keyphrase Extraction
Broadly speaking, we can split the process of automatic keyphrase extraction into candidate identification and keyphrase selection. First, we identify a set of words and phrases that can potentially convey the topical content of a text. Next, we rank them based on a scoring mechanism to select the most suitable candidates.
5.1. Keyphrase Identification
The first step toward extracting keyphrases from a text is to identify potential candidates. Obviously, we begin by performing tokenization of the text we are interested in. A brute force approach can be to select all n-grams possible for a particular limit of n. For example, we may be interested in finding all unigram, bigram, and trigrams.
Even for a reasonable size of text, this will give us a huge volume of candidates to go through. Of course, it’s not difficult to understand that most of these candidates will be of no interest to us. Fortunately, we can apply one or more NLP techniques discussed earlier to restrict the size of probable candidates.
For instance, we can begin by restricting words with inflection forms to their base forms using stemming and lemmatization techniques. We can also remove stop words and punctuation as they may not be necessary for our task. However, we should be careful that some of these techniques can lead to a sematic loss for certain phrases.
Furthermore, we can use PoS tagging to filter out words with certain parts of speech. We can also use the PoS patterns to restrict candidate phrases to certain patterns. For instance, we may be interested in a pattern like any number of adjectives followed by at least one noun.
Another important trick we learned earlier is named entity recognition. This can be a handy tool to identify potential candidate phrases. Additionally, we can use collocation extraction to identify phrases that tend to appear more commonly. As a result, such phrases have a better chance to describe a text.
5.2. Keyphrase Selection
The preliminary stage of identifying the candidate keyphrases can result in several key phrases. Of course, not all of them will be suitable and convey the meaning of a text similarly. What we have to do is select the best out of the rest of the keyphrases.
One of the simplest ways to determine which keyphrase has more relevance to a text than others is to use one of the statistical measures. We learned earlier how we can use measures like TF-IDF and BM25 for this purpose. Unfortunately, frequency-based statistics are not necessarily the best measure of relevance for keyphrase selection.
The more sophisticated methods of selecting relevant keyphrases use supervised and unsupervised machine learning models. Supervised methods rely on properly labeled training data to work. While these methods result in better performance, generating training data is no trivial task. On the contrary, unsupervised methods try to discover the underlying structure without labeled training data.
5.3. Unsupervised Methods
Some of the popular approaches towards unsupervised keyphrase extraction include graph-based ranking methods. Graph-based ranking algorithms work by assigning importance to vertices within a graph. The importance of a vertex is drawn from the structure of the graph. Some of the popular graph-based ranking algorithms include TextRank, HITS, Positional Power Function, and PageRank.
In the context of keyphrase extraction, we transform the text into a graph, where the nodes represent candidate keyphrases, and the vertices represent their relations. Here the relationship between candidate keyphrases can be determined by how frequently they appear together or how semantically close they are.
Let’s assume we create a directed graph  , where
, where  is the set of vertices, and
is the set of vertices, and  is the set of edges. The score or importance of a vertex
is the set of edges. The score or importance of a vertex  is defined as:
is defined as:

Here  is the set of vertices that point to , and
is the set of vertices that point to , and  is the set of vertices that points to. Moreover,
is the set of vertices that points to. Moreover,  is the damping factor that is set between 0 and 1.
is the damping factor that is set between 0 and 1.
Once we transform the text into a graph, we can use one of the graph-based ranking algorithms to run through this graph and give us the highest scoring terms. Please note that graph-based ranking algorithms are not the only algorithms in this space, and we have alternatives like topic-based clustering methods.
5.4. Supervised Methods
Supervised keyphrase extraction methods typically work by reformulating the problem of keyphrase extraction to either classification or ranking problems. With the classification approach, we are interested to know if a candidate keyphrase is suitable to represent a text or not. However, since this is not a simple task, the ranking approach tries to rank the candidates pairwise based on their relevance.
Once we’ve reformulated the problem, the next important task is to select the features that will be most relevant for our decision. The statistical measures related to frequency play an important part here, but there are several other features like the length of the phrase and the phrase’s position that can be of significance.
There are several traditional machine learning algorithms for supervised learning that we can use here. For instance, Naive Bayes, Decision Trees, Support Vector Machines, and more. However, some specific implementations fit the bill more than others. For instance, KEA is a binary classification method that uses  and the
and the  of the first appearance to select keyphrases.
of the first appearance to select keyphrases.
KEA uses the Naive Bayes technique to generate the model for predicting the class using the feature values. This works by learning two sets of numeric weights from the feature values:
![P[yes] = \frac{Y}{Y + N} P_{TF-IDF}[t|yes] P_{distance}[d|yes]](/wp-content/ql-cache/quicklatex.com-25cda5d99288cfa583ec25342d45c100_l3.svg "Rendered by QuickLaTeX.com")
![P[no] = \frac{Y}{Y + N} P_{TF-IDF}[t|no] P_{distance}[d|no]](/wp-content/ql-cache/quicklatex.com-eb0caa659742fe93c2d068126a2e373b_l3.svg "Rendered by QuickLaTeX.com")
The first set applies to the positive examples (“is a key phrase”), and the second set applies to the negative examples (“is not a key phrase”). Finally, based on these weights, an overall probability is calculated for a candidate keyphrase. Then the candidate keyphrases are ranked based on this probability.
6. Conclusion
In this article, we discussed the fundamental concepts of IR and NLP. We primarily focused on the techniques and algorithms that are most often used in automatic keyphrase extraction. Finally, we went through the process and algorithms that we can use for keyphrase identification and selection.