

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about cache-friendly code and explain its importance in computer programming.
The term ‘cache’ is very generic and means different things in different contexts. It can denote a CPU cache, a disk cache, a DB cache, or a browser cache.
In general, a cache is temporary storage that offers faster retrieval than the original data source holding our data. So, we can say that a local disk acts as a cache for remote files when an application is requesting and downloading them from a remote server. Similarly, for an application doing many read operations on the local filesystem, we cache the most accessed files in CPU caches and RAM.
Sometimes, the performance of our application is so critical that we need to write the code in such a way that it uses the cache to the full extent. If that’s the case, we say we want to write cache-friendly code.
In many cases, the code or data don’t fit into our caches. So, data transfer happens to and from the system memory which makes execution slower. For example, a dictionary having millions of records is probably too large for completely any CPU cache.
Concerning the cache, there are two types of code:
A piece of code is cache-friendly if it uses caching optimally. Cache-friendly code optimally uses the cache by increasing the hit rate as shown in the following figure below:
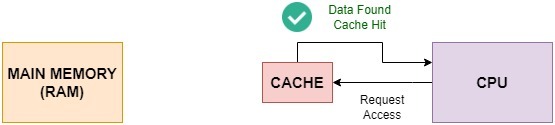
There are several ways to make our code cache-friendly.
To make the code cache friendly, we should keep most of our data in contiguous memory locations. That way, when our code sends the first access request, a major part of the data that will be used ahead will get cached. For example, while reading the first array element, we can cache the entire array.
This is closely related to the choice of data structures.
For instance, instead of using a linked list to model a computer network graph, we can use a matrix (two-dimensional array). Linked items in a list can be all over the memory, whereas matrix elements are kept close together.
To make the code cache friendly, we need to avoid using large loops. Instead, we should break a large loop into smaller loops.
The reason is that if the loop’s body accesses a lot of data, the items cached at the beginning of an iteration can drop out from the cache by the iteration’s end. Afterward, when the persecution flow gets back to the beginning (of the next iteration), there will be a cache miss.
We can add cache-friendliness to our code by keeping the function stack as small as possible. We do that by avoiding unnecessary recursion.
For example, if the arguments to the recursive calls take up a lot of space, it will be harder for the system to fit them into the cache memory. That results in more data transfer operations.
We should adopt a cache-friendly design for all our applications. We can do this by choosing data structures that fit into a cache block. Furthermore, we should tweak our algorithms to read and process data in contagious blocks whose size corresponds to that of a cache block. Cache-friendly data structures fit within a cache line and are aligned to memory such that they make optimal use of cache lines.
A common example of a cache-friendly data structure is a two-dimensional matrix. We can set its row dimension to fit in a cache size block for optimal performance.
So, let’s say an  matrix
matrix  stores an image’s bit map. Here, we know that the elements that are adjacent in a row are also stored as adjacent in memory. Therefore, we access them in sequence so that the cache can take an entire row as a contiguous memory block:
stores an image’s bit map. Here, we know that the elements that are adjacent in a row are also stored as adjacent in memory. Therefore, we access them in sequence so that the cache can take an entire row as a contiguous memory block:
algorithm AlignDataWithCache(image, m, n):
// INPUT
// image = the bitmap of the image to process
// m = the number of rows (= the size of a cache line)
// n = the number of columns
// OUTPUT
// Processed image with optimized cache alignment
for j <- 1 to n:
for i <- 1 to m:
pixel <- image[j, i]
Process pixelWhat if we read the elements column-wise? That will be cache-unfriendly because the elements in the same column aren’t adjacent in memory. Accessing them one by one will result in cache misses and subsequent data transfer operations. As a result, our code would run slowly.
We can make the code cache-friendly by using the language’s native cache-friendly constructs instead of the cache-unfriendly ones.
For instance, arrays perform better than hash tables and linked lists. The reason is that arrays take up contiguous memory, so are more cache-friendly. That isn’t the case with the other two structures.
We should avoid having many if-then-else branches, i.e., conditional jumps in the code that make its execution non-linear. It not only makes the code difficult to understand but also makes it hard for any compiler to optimize it for performance. Conditional jumps can cause slowdowns because of branching.
For example, let’s say that we are checking if some list of words exists in English or French. To do so, we need to load the dictionary of the target language. Even if the list is sorted, the data required won’t be in the cache, irrespective of the branch that gets executed. So, we have a cache miss in both cases:
algorithm BranchesAndCache(words, language):
// INPUT
// words = a list of words to check for existence
// language = the language (English or French)
// OUTPUT
// Checks if words exist in the specified language dictionary
for word in words:
if language = English:
dictionary <- load the English dictionary
else:
dictionary <- load the French dictionary
Check if word is in dictionaryOne way to cope with this issue is to pre-load the dictionary of the more frequently used language to minimize cache misses. However, that takes more memory than necessary.
We can also make the binary code cache-friendlier by setting appropriate compiler flags. Our compiler can produce smaller and faster binary code by using tricks such as unrolling loops, optimizing function calls, and padding data structures.
For example, the GNU C Compile (GCC) GCC offers a tune flag. This flag optimizes the memory management part of the code for the underlying CPU architecture. That way, it reduces the cache miss rate.
A piece of code is cache unfriendly if it doesn’t make the optimal use of caching.
Some of the features that can make code cache unfriendly are as follows:
The consecutive data access calls of a cache-unfriendly program are spread across the memory. That increases the cache miss rate, so the code takes longer to execute:
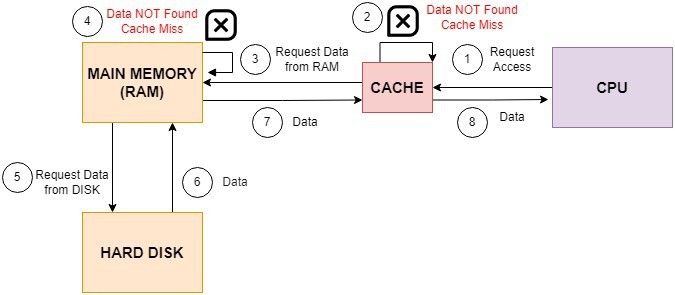
Let’s understand the flow here. The CPU probes the cache for a data item. The cache doesn’t have it which results in a cache miss. The cache then fetches the same from the system memory (RAM). If the item isn’t in RAM, we need to get it from the secondary storage. The RAM fetches it same from the system disk, stores it in its page table, and transfers it to the cache. The cache stores it and forwards it to the CPU.
An example is the above bitmap matrix. If we iterate over it column by column, we’ll get a lot of cache misses.
What are the key features of the cache-friendly code?
This is the most important criterion for making code cache-friendly. It’s fulfilled when a computer program accesses the same set of memory locations within a very short period.
The locality has two components:
Spatial locality means our program accesses instructions whose addresses are near one another.
We can achieve spatial reference by doing two things. Firstly, we pack our information densely so that memory is optimally utilized. Secondly, we assign contagious locations to data items that are likely to be processed together.
That’s the reason why linear search can be faster than binary search when the input array isn’t large because, in the case of the former, we can store the entire array in the cache on the first load.
Temporal reference locality means all operations on the loaded data are done instantaneously. The goal is not to flush the intermediate results out of the cache.
For example, let’s consider the case of arithmetic operations on large floating-point numbers. For the following code, we carry all vector calculations one after another. This way, there is no cache flush, and our code executes very fast:
algorithm TemporalLocality(a, b, c, d):
// INPUT
// a, b, c, d = vectors to process
// OUTPUT
// Result of adding vectors, demonstrating temporal locality
result1 <- a + b
result2 <- c + d
result <- pair(result1, result2)
return resultNow, what if we executed other instructions between those? The value of  and
and  could be flushed out of the cache before computing
could be flushed out of the cache before computing  :
:
algorithm NoTemporalLocality(a, b, c, d):
// INPUT
// a, b, c, d = vectors to process
// OUTPUT
// Result of adding vectors without maintaining temporal locality
result1 <- a + b
// Processing other data, potentially flushing result1, a, b, c, d out of the cache
result2 <- c + d
// Processing other data, potentially flushing result2, c, d out of the cache
result <- pair(result1, result2)
return resultThe same goes for  and
and  when we start computing .
when we start computing .
Another factor that affects cache-friendliness is the use of prefetch. Most modern processors have prefetch instructions that inform the hardware about data items that will be used soon. Prefetching the data before the application requests them speeds up its execution.
Modern processors have several hardware prefetchers that analyze the program’s access pattern and decide on prefetching. For example. Intel-based processors have L2 hardware prefetchers that automatically detect memory accesses and issue prefetch requests on their own.
In this article, we have gone through the importance of writing code that optimally uses caches. There are several good practices in our design to make our code cache-friendly to get the best performance.