

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about buffers in computer programming.
Buffer is a generic term that means different things in different contexts. In general, we can say that a buffer is a tool that mitigates the effects of fluctuations in supply and demand.
In computer science, a buffer is temporary storage we use when one component feeds data to the other, but their speeds aren’t the same. There can be multiple producers and consumers, but we’ll focus on the case with a single producer and only one consumer to better explain the concepts.
Most operating systems come with predefined buffers used for various purposes. For example, data transfers between a fast CPU and a slow external device are impossible without a buffer in between them.
We can also make our custom buffers when developing our applications.
Let’s assume we have a system consisting of a producer and a consumer. The producer program is generating data that the consumer program is using.
Now, the producer may generate data faster than the consumer can process them. In that case, the latter will some data and thus generate sub-optimal or even incorrect results. To avoid that, we use a sufficiently sized buffer between the two:
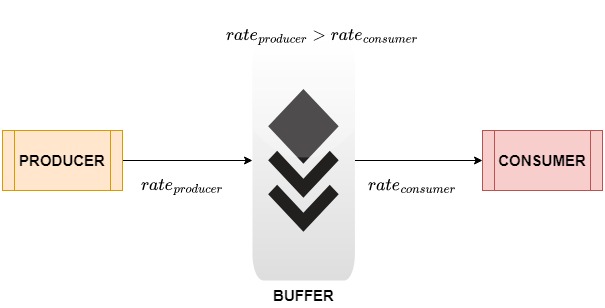
Thus, the buffer acts as intermediate storage. The producer places the generated data items into the buffer. The consumer takes the items one at a time at a speed it can process them. If its processing is slower than data generation, they’ll wait for the consumer to pick them. Meanwhile, the producer will keep putting the data into the buffer, so no items will be lost.
Buffers are useful when there’s a mismatch between the data generation and data processing rates. However, we need to set its size properly.
The buffer’s size affects the overall performance. If we reserve more space than necessary, it’ll result in underutilization. In contrast, if set a small size, we’ll experience data loss and get inaccurate results.
We can determine the optimal size for an application’s buffer only through rigorous testing covering all possible scenarios. However, during the system design phase, we can reasonably estimate the buffer size by considering a few important factors.
The environment in which our application will work and the specified requirements can help us estimate the size of the buffer.
For instance, we need a large buffer at both the transmitter and receiver ends if our application uses networking to connect them. This is because the medium between them (lossy wireless channels) can have losses and delays. So, the buffer can mitigate these errors without affecting the quality of service.
A classical example is a video streaming service. Here, the video player at the client usually sets the buffer size as a function of the network characteristics. It prefetches media content from the server across the medium and stores it in the buffer so that the end user experiences no jitter or delay.
We usually choose a buffer size that is a multiple of the difference between the data generation and consumption rates to avoid buffer overflow. For example, if data is generated at a rate of 2 items per second but is consumed at 1 item/s, we can set the buffer’s size to  to avoid overflow.
to avoid overflow.
This also determines the buffer size. If we use the system disk space as a buffer, the read and write operations will be slower as compared to a buffer in RAM.
Most file systems read and write in blocks of 4096 or 8192 bytes (large power of 2). So, we need to set our buffer’s size to be a multiple of the disk block size. That way, we can make read-write operations extremely efficient.
Buffers suffer from two problems:
Buffer overflow or the bounded buffer problem happens when the producer program generates data at a rate much higher than that at which the consumer program can process them even with the help of a buffer. In such a case, the buffer becomes full, and new data either replace the old data or are lost.
For instance, let’s say that our producer generates sentences at a rate of 10 letters per second. The buffer can hold 8 letters, and the consumer can read a letter every 2 seconds. So, a buffer overflow occurs in the very first second:
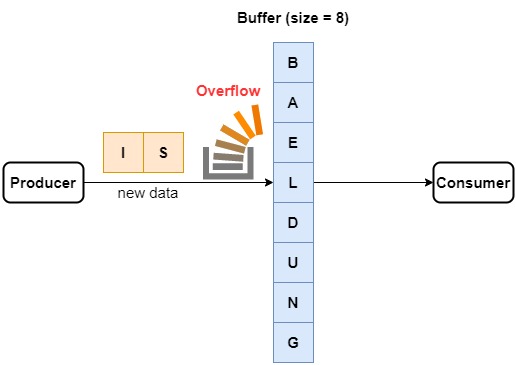
How do we handle this issue?
For instance, we can use a larger buffer. It’ll still get filled eventually, but if our application takes less time to complete than the buffer to fill, we may avoid the overflow.
We can also speed up the consumer or slow down the producer. However, if the producer gets slower than the consumer, we’ll get the converse issue, buffer underflow.
A buffer underflow occurs when the producer is filling the buffer much slower than the consumer processes data. As a result, the buffer is always partially filled and the consumer sits idle most of the time. The result is that overall the system underperforms, both in terms of idle time and wasted memory:
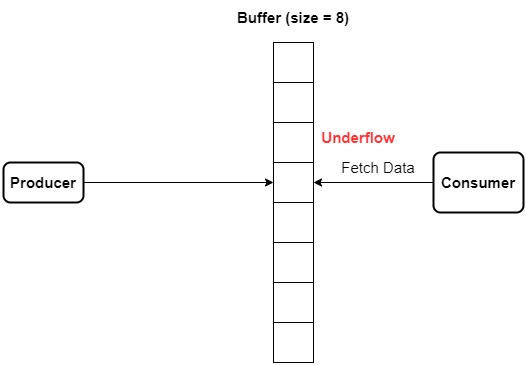
We have a few ways to solve this problem.
The first way is to use a smaller buffer. At any point in time, it’ll have more data than vacant space. This way, less memory will be underutilized.
Secondly, we can also speed up the producer or slow down the consumer. However, we get the converse effect if the consumer gets slower than the producer. In such a case, we run into buffer overflow.
We can avoid overflow and underflow problems if we ensure that the producer doesn’t produce data when the buffer is full. We also need to make the consumer not fetch the data when the buffer is empty. In other words, we need to synchronize them.
The general idea is to make the producer check the buffer upon generating a data item. If it’s full, the producer will go to sleep. Otherwise, it will add new data to the buffer as usual.
The consumer also checks the buffer when it gets ready to process new data. If the buffer is empty, the consumer will go to sleep. If not, it’ll take the oldest unprocessed item from the buffer:
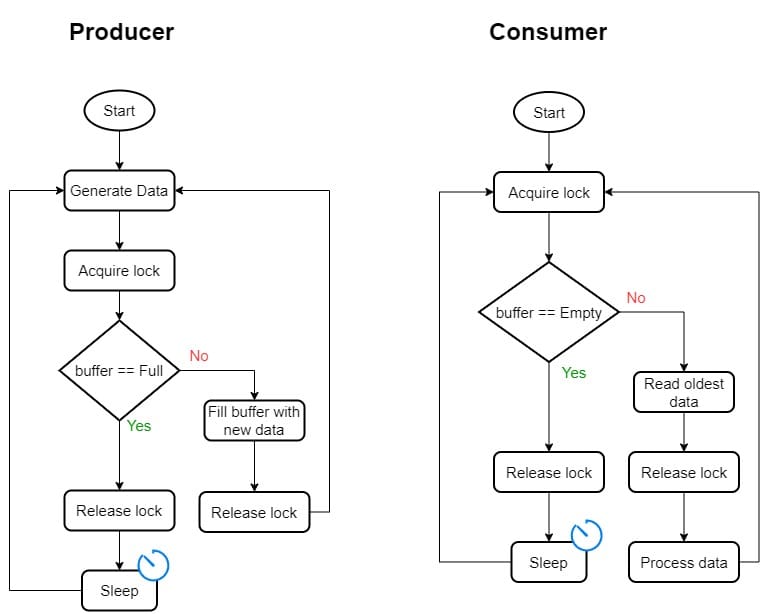
Here, we guard the reading and writing operations on the common buffer with an exclusive lock. Since the producer’s and consumer’s checks are exclusive, both release the lock after they do the checks, and go to sleep if the tests fail, we ensure no race condition happens. Thus, we get consistent behavior each time we run such an application.
Although both the buffer and the cache serve a similar purpose of temporary memory storage, they aren’t the same.
We use buffers when there’s a mismatch between the rates at which we generate and process data. On the other hand, the purpose of a cache is to store the most frequently and recently used data to speed up processing.
Further, a cache is usually considerably smaller than a buffer and reads and writes data faster. Additionally, all the processes share the cache whereas each program can have its buffer. Lastly, the cache size is fixed. In contrast, a buffer’s size can be configurable or fixed depending on the implementation.
In this article, we learned about buffers and the important role they play in computer programming. We use buffers when an application or a software component producing data is faster or slower than the one consuming the data.