

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Calculating the Average of a Set of Circular Data
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this article, we’ll study how to calculate the average of a set of circular data points. We’ll begin by defining what circular data points are and what their average would look like. Then, we’ll discuss approaches to compute average points in a set of circular data.
At the end of this tutorial, we’ll be able to implement an algorithm that calculates the average in a set of circular data points.
2. Circular Data
This tutorial will prove useful if we’re working with spatial data and building geospatial applications. Very frequently, as is the case when we work with geospatial polygons, we’re given some sets of points, and we have to find a new one that is somewhere between them. Other times, when we work with geospatial distances, we have to find a point whose sum of distances from a set of points is minimal. In these cases, we’ll want to find the average in a set of circular data points.
2.1. The Unit Circle
A set of circular data points is characterized by two coordinates:  and
and  . These coordinates must also satisfy the Pythagorean equality that
. These coordinates must also satisfy the Pythagorean equality that  for some constant radius
for some constant radius  . In the case of the unit circle, this radius is assumed to be
. In the case of the unit circle, this radius is assumed to be  :
:

Any other circle is a scaled-up version of this unit circle. For this reason, we can study the unit circle, knowing that any other can later be obtained by simple scaling.
2.2. Sampling the Unit Circle as a Cartesian
If we have a unit circle, we can sample a set of points from it and thus develop a set of circular points. Let’s see how we can do that and develop our dataset.
To sample a unit circle and create a dataset containing one point, we’re free to choose the first coordinate but not the second. That is to say, if we randomly pick the first coordinate, the second coordinate can’t be any arbitrary coordinate: it can only have one of two values that satisfy the Pythagorean condition we set earlier.
Does this mean that the second coordinate is uniquely identified? No, unfortunately, it doesn’t; for each given value of one coordinate of a point on the unit circle, there are, in fact, two possible coordinates that correspond to points in the same unit circle:
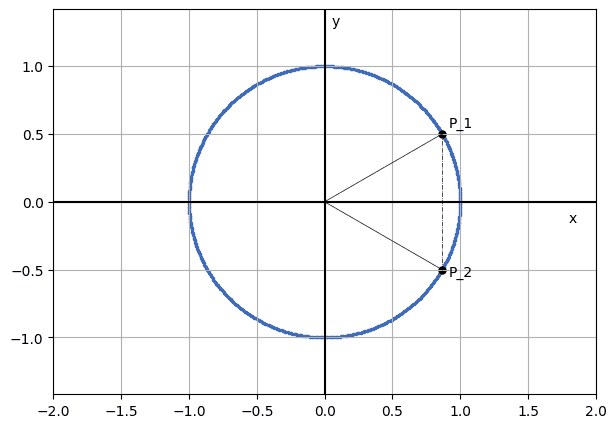
We can say, therefore, that the function that associates a coordinate to a given coordinate of a point on a circle isn’t a function but rather a map. Two points correspond to each value that we associate to a given coordinate, so a map that gives us points  given an input coordinate outputs two values
given an input coordinate outputs two values  is:
is:

If we want to generate a single point, we could randomly select an ![x \in [-1, 1]](/wp-content/ql-cache/quicklatex.com-4480ebebdb6973ea8e4a4032d32e052b_l3.svg "Rendered by QuickLaTeX.com") , then flip a coin and choose
, then flip a coin and choose  if the coin lands on the head or
if the coin lands on the head or  otherwise. The point we sampled corresponds to
otherwise. The point we sampled corresponds to  in the first case or
in the first case or  in the second.
in the second.
If we then want to generate  points drawn from the unit circle, we could simply repeat this operation
points drawn from the unit circle, we could simply repeat this operation  times and thus create our dataset.
times and thus create our dataset.
If we want to create a dataset comprising points sampled randomly from the unit circle, we can’t simply accept both and for each draw and insert both into our dataset. We’d like to do that, as it would decrease the number of draws we have to perform from to  ; however, if we did that, the points we’d draw are no longer independent draws. In fact, we’d be able to guess another point in a dataset, given a point , by simply flipping the sign of .
; however, if we did that, the points we’d draw are no longer independent draws. In fact, we’d be able to guess another point in a dataset, given a point , by simply flipping the sign of .
2.3. In Polar Coordinates
The previous method is thus not optimal since it requires drawing two random numbers per point: one for the coordinate and one for the sign of the coordinate. However, there is a better method based on a different definition of a circle.
A unit circle can be defined as the space spanned by a rotating segment of length 1 around the origin:
With this type of definition, a point on this circle can be uniquely identified by determining the angle existing between the rotating segment and one of the two basis vectors for the plane:
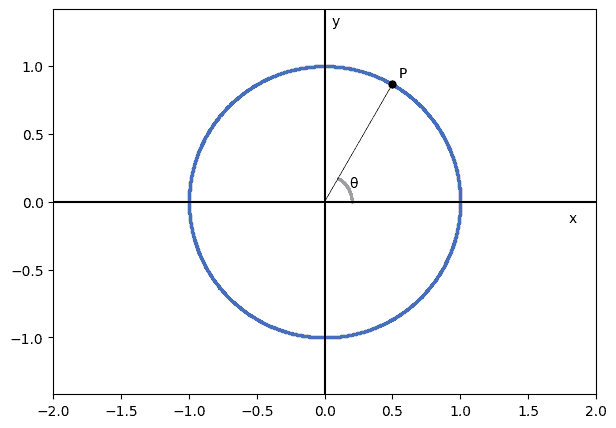
Most frequently, we select the axis as the one with respect to which we measure the angle. If the points come in polar coordinates, then they are defined as an ordered pair  , where is a radius, and
, where is a radius, and  is the angle with the axis. If we have a point in polar coordinates, but we want it in Cartesian coordinates, we can always convert via this transformation:
is the angle with the axis. If we have a point in polar coordinates, but we want it in Cartesian coordinates, we can always convert via this transformation:

Notice that, for the unit circle, the Cartesian coordinates of a point equal the output of the two trigonometric functions associated with the corresponding angle.
If we’re working in polar coordinates, and we want to draw a random point on a circle of radius , all we have to do is draw a random angle from the uniform distribution  , and repeat for as often as necessary.
, and repeat for as often as necessary.
3. Calculating the Average of a Set of Circular Data
3.1. The Average of a Set
Now that we have a method for drawing random points from a circle, we can calculate their average. In general, if we have a set  of
of  elements drawn from
elements drawn from  , such that
, such that  , then we define its average
, then we define its average  as:
as:

The average of is provably contained in . This is because the set from which the variable is created, the set of the real numbers, is closed under the operations of addition and division that make up .
3.2. The Average in a Bivariate Distribution
If we have a bivariate distribution  of real numbers, such that and
of real numbers, such that and  , we can define the average
, we can define the average  of this bivariate distribution as:
of this bivariate distribution as:

In other words, if we have two real variables, the average of the bivariate distribution can be calculated by independently computing the average of each of the two variables. The same principle generalizes to any  -variate distribution comprising independent variables. In that case, we simply compute the average of each independent variable and consider, as the average for the multivariate distribution, the tuple comprising each computed average.
-variate distribution comprising independent variables. In that case, we simply compute the average of each independent variable and consider, as the average for the multivariate distribution, the tuple comprising each computed average.
3.3. Average of a Set of Circular Data
A set of points drawn from a circle doesn’t however comprise independent variables, and it doesn’t, therefore, fall under the hypothesis of multivariate distribution described above. This is because we impose an additional constraint between the coordinates of the points of a circle. In fact, if the point  is on a -sphere, then the following relationship must persist:
is on a -sphere, then the following relationship must persist:

There is however no guarantee that the average of the coordinates of several points, with each point satisfying the previous condition for the same, unique , also satisfies that same condition.
Let’s consider the trivial case in which the two points,  and
and  , lie at two opposite poles of the unit circle: both points then satisfy the conditions that they lie on a circle of radius . The average computed according to the previous rule, as , is however:
, lie at two opposite poles of the unit circle: both points then satisfy the conditions that they lie on a circle of radius . The average computed according to the previous rule, as , is however:

This average doesn’t satisfy the condition of the unit circle because its squared coordinates aren’t equal to 1. This may satisfy us in some cases, as we might, for example, be interested in finding the barycenter for a gravitational system of static objects of equal mass. In that case, the average computed above will suffice.
However, if we want to compute averages that lie on the same circle as the points they refer to, we need to impose some additional constraints.
3.4. The Average Itself Is on a Circle
To find an average of points that lie on a circle, with the average itself on that circle, we should refer to the considerations we made above and convert all coordinates to their polar form. Then, we compute the average of the polar coordinates, which guarantees that the result lies on the circle.
If we want the average of the two points and , in this order, to be located at  , we could then calculate a value of
, we could then calculate a value of  to
to  and
and  to
to  . In doing so, we can find the average angle
. In doing so, we can find the average angle  as:
as:

This gives us a nice angle of 90 degrees, orthogonal to the axis, as we’d expect.
4. The Algorithm to Compute the Average
4.1. Transforming Into Polar Coordinates
In general terms, the procedure for computing the average of a set of circular data is as follows.
We begin with a set of points  . We can express their coordinates as tuples, as
. We can express their coordinates as tuples, as  . Then, if we assume that they all belong to the same circle, we compute the circle’s radius as
. Then, if we assume that they all belong to the same circle, we compute the circle’s radius as  . We only need to do it for the first tuple since the radius is constant.
. We only need to do it for the first tuple since the radius is constant.
In polar form, the radius is the first of the two coordinates for each of the points. The remaining coordinate, the angle  , can be calculated as a function of a temporary variable
, can be calculated as a function of a temporary variable  . We construct as:
. We construct as:

Then, according to the signs of and , we generate from as:

4.2. Averaging the Angle
Once the set  has thus been computed, its average can be calculated as:
has thus been computed, its average can be calculated as:

The point on the circle that corresponds to  is therefore the one that we find by transforming back into Cartesian coordinates:
is therefore the one that we find by transforming back into Cartesian coordinates:

This point with coordinates  is, finally, the average of the points of the set of circular data. We can prove that this point is guaranteed to lie on the circle with radius :
is, finally, the average of the points of the set of circular data. We can prove that this point is guaranteed to lie on the circle with radius :

The average point  is thus
is thus  .
.
4.3. If the Radius Isn’t Constant
The last case to consider is where the radius can vary. This can happen if all points are drawn from a spheroid with the same center but with some variance in its radius. This is the case, for example, for all points drawn from the surface of Earth since the radius of the planet isn’t constant.
In this case, it isn’t sufficient to average out the angles  . Instead, we have to average two variables: the angle itself, and the radius as well, with the latter calculated with respect to every single point.
. Instead, we have to average two variables: the angle itself, and the radius as well, with the latter calculated with respect to every single point.
For each point  , we can obtain the associated radius
, we can obtain the associated radius  as
as  . Then, the average point for the set of points becomes
. Then, the average point for the set of points becomes  , found by averaging out all computed radii.
, found by averaging out all computed radii.
5. Conclusions
In this article, we studied how to calculate the average of a set of circular data. We began by defining the conditions that make a set of points circular. We also studied how to create a set of circular points by randomly drawing from a circle.
Then, we defined the concept of average in relation to a set of points. Finally, we also added the additional constraint that the average, itself, must be a point on a circle and relaxed the constraint that the radius is constant among all points.