

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: July 22, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll explain how to find common elements in two sorted arrays.
In this problem, we have two sorted arrays: ![a=[a_1 \leq a_2 \leq \ldots \leq a_n]](/wp-content/ql-cache/quicklatex.com-b5920c64ab09ae32ae00e2931cb13525_l3.svg "Rendered by QuickLaTeX.com") and
and ![b=[b_1 \leq b_2 \leq \ldots \leq b_m]](/wp-content/ql-cache/quicklatex.com-21b76afa259c6de3c9819888036a8081_l3.svg "Rendered by QuickLaTeX.com") . Our task is to find the common elements.
. Our task is to find the common elements.
For instance, if ![a = [1, 2, 3, 4, 5]](/wp-content/ql-cache/quicklatex.com-c35ee067d30cfd6dc179d27e3779367a_l3.svg "Rendered by QuickLaTeX.com") and
and ![b = [3, 4, 5, 6, 7]](/wp-content/ql-cache/quicklatex.com-e31ae1025781d98b8e920e9560bd2684_l3.svg "Rendered by QuickLaTeX.com") , our algorithm should output
, our algorithm should output ![[3, 4, 5]](/wp-content/ql-cache/quicklatex.com-55febaa002ccfd0b00189b5cd860b61c_l3.svg "Rendered by QuickLaTeX.com") as the result.
as the result.
To find the common elements efficiently, it should use the fact that  and
and  are already sorted. Additionally, we’ll also require the output array to be non-descending as the input arrays.
are already sorted. Additionally, we’ll also require the output array to be non-descending as the input arrays.
We’ll also assume that and can contain duplicates. So, if a common element is repeated twice in , and thrice in , we’ll include it twice in the result array. For instance:
![\begin{equation*} \begin{matrix} a&=& [1& 2& 2& 4& 5] \\ b&=& [2& 2& 2& 3& 5& 7] \\ result&=& [2& 2& 5]\\ \end{matrix} \end{equation*}](/wp-content/ql-cache/quicklatex.com-cb6745bf9e858b883d8319659e363f2f_l3.svg "Rendered by QuickLaTeX.com")
Let’s start with the naive algorithm that doesn’t use the fact that and are sorted:
algorithm NaiveFindCommonElements(a, b):
// INPUT
// a = a sorted array with n elements
// b = a sorted array with m elements
// OUTPUT
// c = the sorted array of the common elements of a and b
c <- an empty array
for i <- 1 to n:
for j <- 1 to m:
if a[i] = b[j]:
// We found a common element
append a[i] to c
return cFor each  , the algorithm iterates over the entire to check if
, the algorithm iterates over the entire to check if  . So, it has an
. So, it has an  time complexity, which implies
time complexity, which implies  if
if  and
and  are comparable. What can we change in this algorithm to get common elements faster?
are comparable. What can we change in this algorithm to get common elements faster?
Well, since the arrays are sorted, there’s no point in iterating over  if
if  . Each of those is greater than , so we can conclude that
. Each of those is greater than , so we can conclude that  . The converse is also true: if
. The converse is also true: if  , we can discard
, we can discard  .
.
That way, we iterate over each array only once. So, we don’t need nested loops. Instead, we can start with  and
and  . When
. When  , we discard by incrementing
, we discard by incrementing  . Similar goes for
. Similar goes for  if . If
if . If  , we append to the result array and update both counters. The loop stops once we reach the end of or . This approach is similar to the merge step in the Merge Sort algorithm:
, we append to the result array and update both counters. The loop stops once we reach the end of or . This approach is similar to the merge step in the Merge Sort algorithm:
algorithm LinearAlgorithmForCommonElements(a, b):
// INPUT
// a = a sorted array with n elements
// b = a sorted array with m elements
// OUTPUT
// c = the sorted array of the common elements of a and b
c <- an empty array
i <- 1
j <- 1
while i <= n and j <= m:
if a[i] < b[j]:
i <- i + 1
else if b[j] < a[i]:
j <- j + 1
else: // We've got a match: a[i] = b[j]!
append a[i] to c
i <- i + 1
j <- j + 1
return cAs a result, the algorithm’s time complexity is linear:  .
.
Let’s use the above example to show how the algorithm works.
Initially,  is empty, and both and point to the first elements:
is empty, and both and point to the first elements:
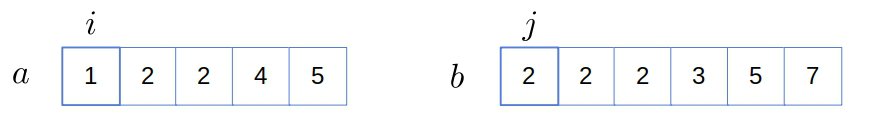
Since  , we increment :
, we increment :
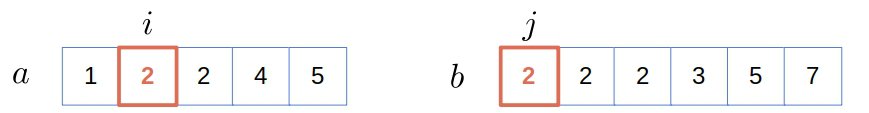
Now, we have a match, so we append 2 to and increment both counters:
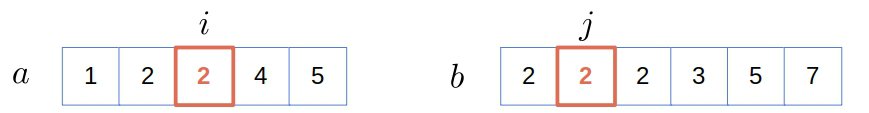
We have a match again, so we do the same as in the previous step:
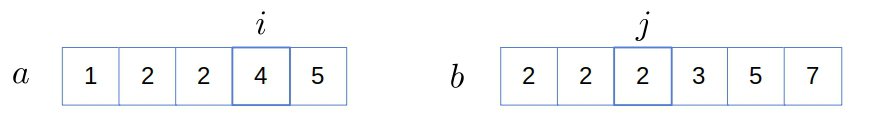
Now,  , so we discard
, so we discard  and move on to
and move on to  :
:
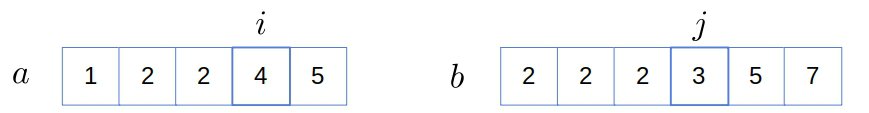
The situation is the same ( ), so we increment only :
), so we increment only :
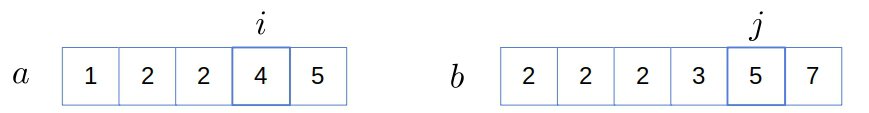
Since  , we increment only :
, we increment only :
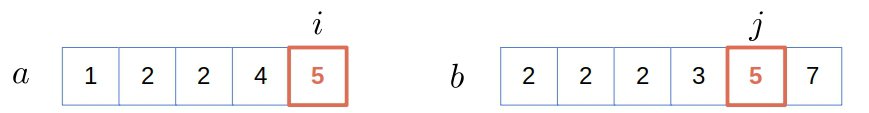
We found a new common element, so we add it to and increment both counters:
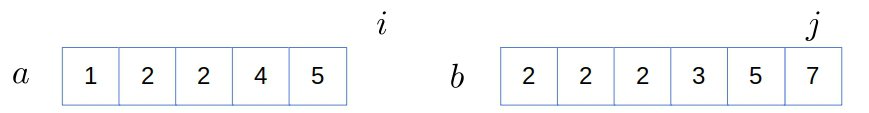
Finally,  , so we stop and output the result:
, so we stop and output the result: ![c=[2, 2, 5]](/wp-content/ql-cache/quicklatex.com-41027316025a8f1765e7e464ce0bd963_l3.svg "Rendered by QuickLaTeX.com") .
.
Let’s suppose that  . Then, for each
. Then, for each  , we can look for
, we can look for  in
in  with the logarithmic binary search. Since
with the logarithmic binary search. Since  , if the binary search finds at the
, if the binary search finds at the  -th position in , we can discard all the element to the left and search for
-th position in , we can discard all the element to the left and search for  in the remainder:
in the remainder: ![[a_{k+1}, a_{k+2}, \ldots, a_n]](/wp-content/ql-cache/quicklatex.com-6a9048ff9260098c9ea6304c4cf30d25_l3.svg "Rendered by QuickLaTeX.com") .
.
Similarly, let’s say the binary search doesn’t find in , but the last index it checks in is . If  , we search for in
, we search for in ![[a_{k+1}, a_{k+2}, \ldots, a_{n}]](/wp-content/ql-cache/quicklatex.com-fba74c321ba9b4a2c97932f3a69e267d_l3.svg "Rendered by QuickLaTeX.com") . On the other hand, if
. On the other hand, if  , it can still happen that
, it can still happen that  , so we don’t discard
, so we don’t discard  .
.
Here’s how the above algorithm works:
algorithm FindCommonElementsBinarySearch(a, b):
// INPUT
// a = a sorted array with n elements
// b = a sorted array with m elements
// OUTPUT
// c = the sorted array of the common elements of a and b
c <- an empty array
k <- 1
j <- 1
while j <= m and k <= n:
// Find the position b[j] should be at in a[k:n]
k <- BINARY-SEARCH(b[j], a[k:n])
if b[j] = a[k]:
append b_j to c
k <- k + 1
else:
if j < m and b[j+1] > b[j]:
k <- k + 1
j <- j + 1
return cThe worst-case time complexity is  . If , we can consider to be a constant with respect to . In that case, the algorithm has an approximate
. If , we can consider to be a constant with respect to . In that case, the algorithm has an approximate  complexity. However, if
complexity. However, if  , we get an
, we get an  algorithm. That’s still better than the naive approach but worse than the
algorithm. That’s still better than the naive approach but worse than the  runtime of the two-side linear search.
runtime of the two-side linear search.
In this article, we presented two efficient ways of finding common elements of two sorted arrays. One approach has an complexity, whereas the other combines binary and linear searches and runs in an  time.
time.