Replication Strategies and Partitioning in Cassandra
Last updated: January 8, 2024


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In this article, we’ll learn about how Apache Cassandra partitions and distributes the data among nodes in a cluster. Additionally, we’ll see how Cassandra stores the replicated data in multiple nodes to achieve high availability.
2. Node
In Cassandra, a single node runs on a server or virtual machine (VM). Cassandra is written in the Java language, which means a running instance of Cassandra is a Java Virtual Machine (JVM) process. A Cassandra node can live in the cloud or in an on-premise data center or in any disk. For data storage, per recommendation, we should use local storage or direct-attached storage but not SAN.
A Cassandra node is responsible for all the data it stores in the form of a distributed hashtable. Cassandra provides a tool called nodetool to manage and check the status of a node or a cluster.
3. Token Ring
A Cassandra maps each node in a cluster to one or more tokens on a continuous ring form. By default, a token is a 64-bit integer. Therefore, the possible range for tokens is from -263 to 263-1. It uses a consistent hashing technique to map nodes to one or more tokens.
3.1. Single Token per Node
With a single token per node case, each node is responsible for a token range of values less than or equal to the assigned token and greater than the assigned token of the previous node. To complete the ring, the first node with the lowest token value is responsible for the range of values less than or equal to the assigned token and greater than the assigned token of the last node with the highest token value.
On the data write, Cassandra uses a hash function to calculate the token value from the partition key. This token value is compared with the token range for each node to identify the node the data belongs to.
Let’s look at an example. The following diagram shows an eight-node cluster with a replication factor (RF) of 3 and a single token assigned to each node:
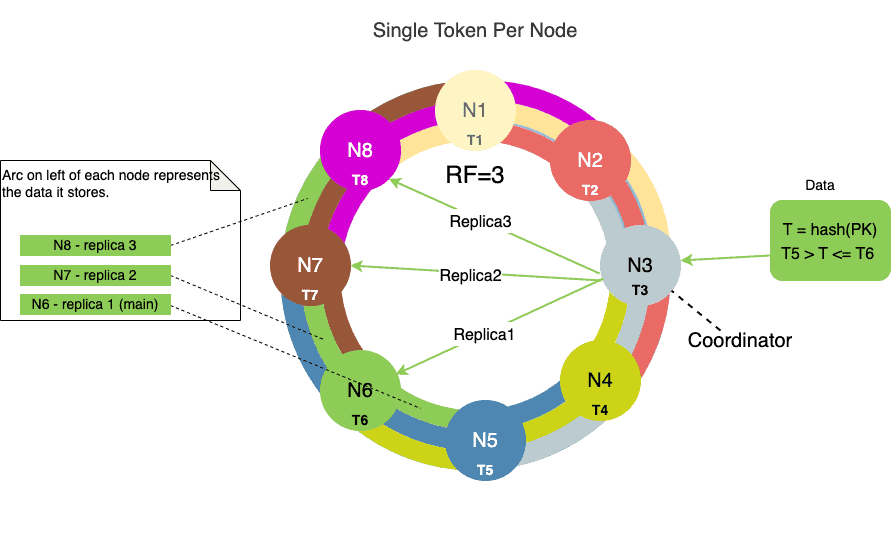
A cluster with RF=3 means each node has three replicas.
The innermost ring in the above diagram represents the main data token range.
The drawback with a single token per node is the imbalance of tokens created when nodes are either added to or removed from the cluster.
Assume that, in a hash ring of N nodes, each node owns an equal number of tokens, say 100. Further, assume there’s an existing node X that owns token ranges 100 to 200. Now, if we add a new node Y to the left of node X, then this new node Y now owns half of the tokens from node X.
That is, now node X will own a token range of 100 – 150 and node Y will own a token range of 151 – 200. Some of the data from node X has to be moved to node Y. This results in data movement from one node X to another node Y.
3.2. Multiple Tokens per Node (vnodes)
Since Cassandra 2.0, virtual nodes (vnodes) have been enabled by default. In this case, Cassandra breaks up the token range into smaller ranges and assigns multiple of those smaller ranges to each node in the cluster. By default, the number of tokens for a node is 256 – this is set in the num_tokens property in the cassandra.yaml file – which means that there are 256 vnodes within a node.
This configuration makes it easier to maintain the Cassandra cluster with machines of varying compute resources. This means we can assign more vnodes to the machines with more compute capacity by setting the num_tokens property to a larger value. On the other hand, for machines with less compute capacity, we can set num_tokens to a lower number.
When using vnodes, we have to pre-calculate the token values. Otherwise, we have to pre-calculate the token value for each node and set it to the value of the num_tokens property.
Below is a diagram showing a four-node cluster with two tokens assigned to each node:
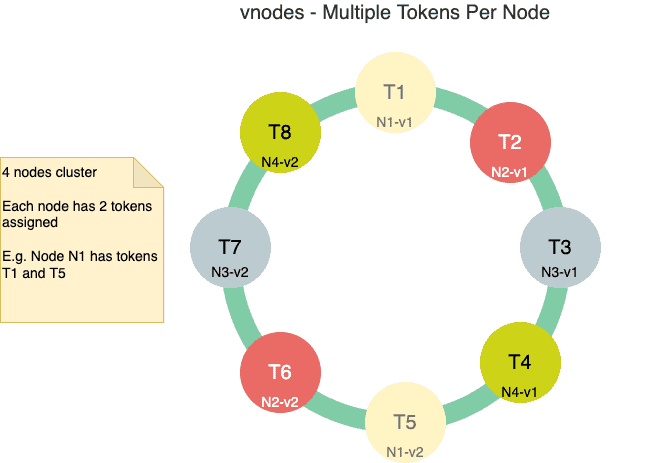
The advantage of this setup is that when a new node is added or an existing node is removed, then the redistribution of the data happens to/from multiple nodes.
When we add a new node in the hash ring, that node will now own multiple tokens. These token ranges were previously owned by multiple nodes, so that data movement post-addition is from multiple nodes.
4. Partitioners
The partitioner determines how data is distributed across the nodes in a Cassandra cluster. Basically, a partitioner is a hash function to determine the token value by hashing the partition key of a row’s data. Then, this partition key token is used to determine and distribute the row data within the ring.
Cassandra provides different partitioners that use different algorithms to calculate the hash value of the partition key. We can provide and configure our own partitioner by implementing the IPartitioner interface.
The Murmur3Partitioner is the default partitioner since Cassandra version 1.2. It uses the MurmurHash function that creates a 64-bit hash of the partition key.
Prior to Murmur3Partitioner, Cassandra had RandomPartitioner as default. It uses the MD5 algorithm to hash partition keys.
Both Murmur3Partitioner and RandomPartitioner use tokens to evenly distribute the data throughout the ring. However, the main difference between the two partitioners is RandomPartitioner uses a cryptographic hash function and Murmur3Partitioner uses non-cryptographic hash functions. Generally, the cryptographic hash function is non-performant and takes a longer time.
5. Replication Strategies
Cassandra achieves high availability and fault tolerance by replication of the data across nodes in a cluster. The replication strategy determines where replicas are stored in the cluster.
Each node in the cluster owns not only the data within an assigned token range but also the replica for a different range of data. If the main node goes down, then this replica node can respond to the queries for that range of data.
Cassandra asynchronously replicates data in the background. And the replication factor (RF) is the number that determines how many nodes get the copy of the same data in the cluster. For example, three nodes in the ring will have copies of the same data with RF=3. We have already seen the data replication shown in the diagram in the Token Ring section.
Cassandra provides pluggable replication strategies by allowing different implementations of the AbstractReplicationStrategy class. Out of the box, Cassandra provides a couple of implementations, SimpleStrategy and NetworkTopologyStrategy.
Once the partitioner calculates the token and places the data in the main node, the SimpleStrategy places the replicas in the consecutive nodes around the ring.
On the other hand, the NetworkTopologyStrategy allows us to specify a different replication factor for each data center. Within a data center, it allocates replicas to nodes in different racks in order to maximize availability.
The NetworkTopologyStrategy is the recommended strategy for keyspaces in production deployments, regardless of whether it’s a single data center or multiple data center deployment.
The replication strategy is defined independently for each keyspace and is a required option when creating a keyspace.
6. Consistency Level
Consistency means we’re reading the same data that we just wrote in a distributed system. Cassandra provides tuneable consistency levels on both read and write queries. In other words, it gives us a fine-grained trade-off between availability and consistency.
A higher level of consistency means more nodes need to respond to read or write queries. This way, more often than not, Cassandra reads the same data that was written a moment ago.
For read queries, the consistency level specifies how many replicas need to respond before returning the data to the client. For write queries, the consistency level specifies how many replicas need to acknowledge the write before sending a successful message to the client.
Since Cassandra is an eventually consistent system, the RF makes sure that the write operation happens to the remaining nodes asynchronously in the background.
7. Snitch
The snitch provides information about the network topology so that Cassandra can route the read/write request efficiently. The snitch determines which node belongs to which data center and rack. It also determines the relative host proximity of the nodes in a cluster.
The replication strategies use this information to place the replicas into appropriate nodes in clusters within a single data center or multiple data centers.
8. Conclusion
In this article, we learned about general concepts like nodes, rings, and tokens in Cassandra. On top of these, we learned how Cassandra partitions and replicates the data among the nodes in a cluster. These concepts describe how Cassandra uses different strategies for efficient writing and reading of the data.
These are a few architecture components that make Cassandra highly scalable, available, durable, and manageable.


















