

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
1. Overview
Apache Cassandra is an open-source, NoSQL, highly available, and scalable distributed database. To achieve high availability, Cassandra relies on the replication of data across clusters.
In this tutorial, we will learn how Cassandra provides us the control to manage the consistency of data while replicating data for high availability.Further reading:
Build a Dashboard Using Cassandra, Astra, and Stargate
Build a Dashboard With Cassandra, Astra, REST & GraphQL - Recording Status Updates
Build a Dashboard With Cassandra, Astra and CQL – Mapping Event Data
2. Data Replication
Data replication refers to storing copies of each row in multiple nodes. The reason for data replication is to ensure reliability and fault tolerance. Consequently, if any node fails for any reason, the replication strategy makes sure that the same data is available in other nodes.
The replication factor (RF) specifies how many nodes across the cluster would store the replicas.
There are two available replication strategies:
The SimpleStrategy is used for a single data center and one rack topology. First, Cassandra uses partitioner logic to determine the node to place the row. Then it puts additional replicas on the next nodes clockwise in the ring.
The NetworkTopologyStrategy is generally used for multiple datacenters and multiple racks. Additionally, it allows you to specify a different replication factor for each data center. Within a data center, it allocates replicas to different racks to maximize availability.
3. Consistency Level
Consistency indicates how recent and in-sync all replicas of a row of data are. With the replication of data across the distributed system, achieving data consistency is a very complicated task.
Cassandra prefers availability over consistency. It doesn’t optimize for consistency. Instead, it gives you the flexibility to tune the consistency depending on your use case. In most use cases, Cassandra relies on eventual consistency.
Let’s look at consistency level impact during the write and read of data.
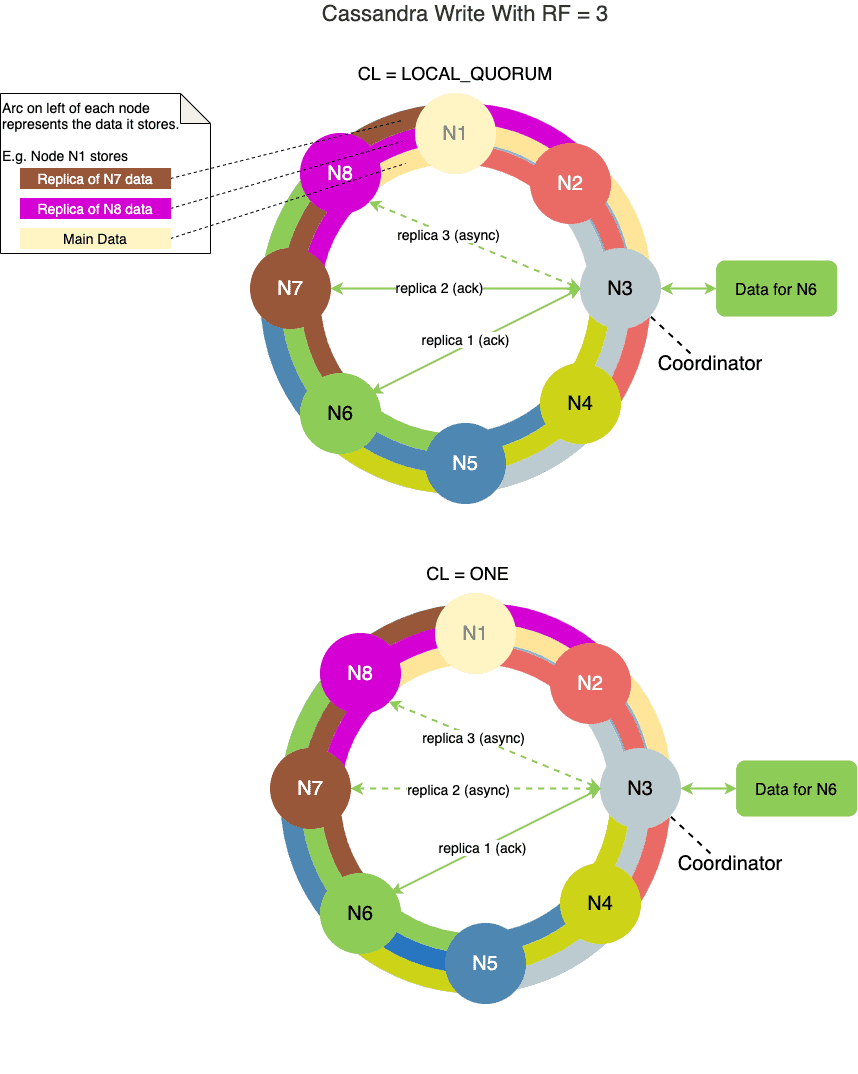
4. Consistency Level (CL) on Write
For write operations, the consistency level specifies how many replica nodes must acknowledge back before the coordinator successfully reports back to the client. More importantly, the number of nodes that acknowledge (for a given consistency level) and the number of nodes storing replicas (for a given RF) are mostly different.
For example, with the consistency level ONE and RF = 3, even though only one replica node acknowledges back for a successful write operation, Cassandra asynchronously replicates the data to 2 other nodes in the background.
Let’s look at some of the consistency level options available for the write operation to be successful.
The consistency level ONE means it needs acknowledgment from only one replica node. Since only one replica needs to acknowledge, the write operation is fastest in this case.
The consistency level QUORUM means it needs acknowledgment from 51% or a majority of replica nodes across all datacenters.
The consistency level of LOCAL_QUORUM means it needs acknowledgment from 51% or a majority of replica nodes just within the same datacenter as the coordinator. Thus, it avoids the latency of inter-datacenter communication.
The consistency level of ALL means it needs acknowledgment from all the replica nodes. Since all replica nodes need to acknowledge, the write operation is the slowest in this case. Moreover, if one of the replica nodes is down during the write operation, it fails, and availability suffers. Therefore, the best practice is not to use this option in production deployment.
We can configure the consistency level for each write query or at the global query level.
The diagram below shows a couple of examples of CL on write:
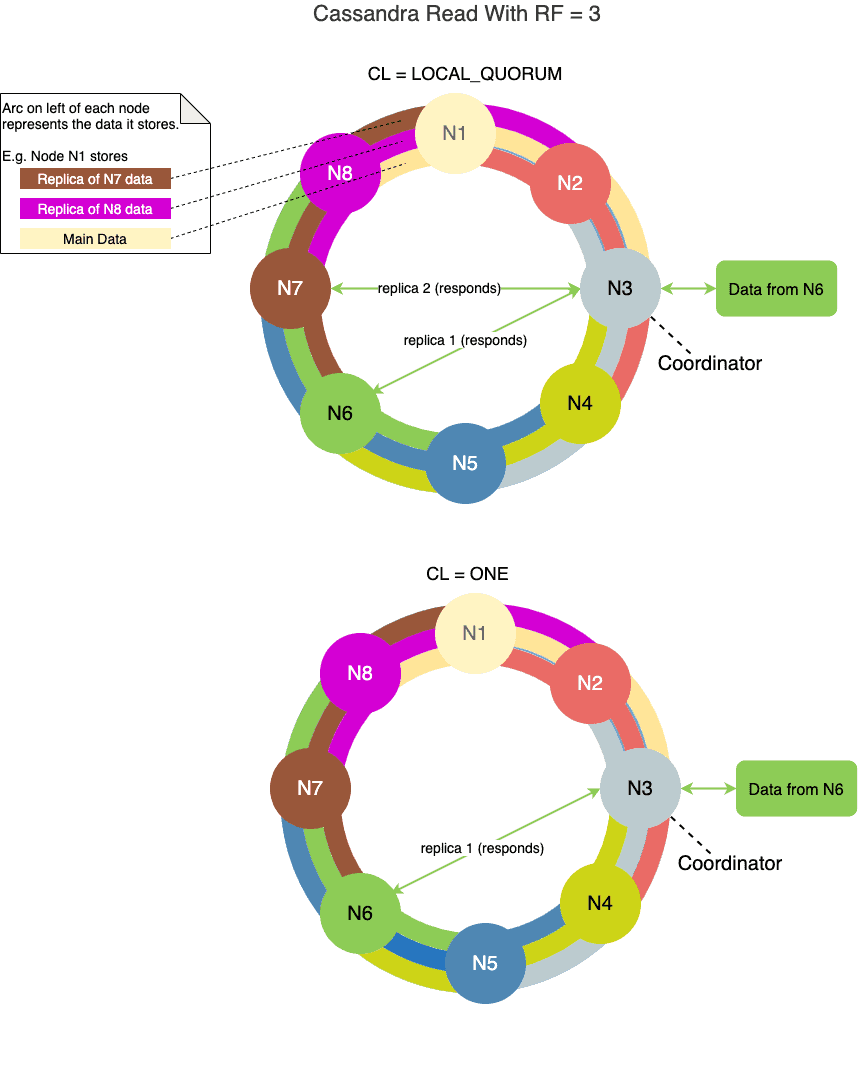
5. Consistency Level (CL) on Read
For read operations, the consistency level specifies how many replica nodes must respond with the latest consistent data before the coordinator successfully sends the data back to the client.
Let’s look at some of the consistency level options available for the read operation where Cassandra successfully returns data.
The consistency level ONE means only one replica node returns the data. The data retrieval is fastest in this case.
The consistency level QUORUM means 51% or a majority of replica nodes across all datacenters responds. Then the coordinator returns the data to the client. In the case of multiple data centers, the latency of inter-data center communication results in a slow read.
The consistency level of LOCAL_QUORUM means 51% or a majority of replica nodes within the same datacenter. As the coordinator responds, then the coordinator returns the data to the client. Thus, it avoids the latency of inter-datacenter communication.
The consistency level of ALL means all the replica nodes respond, then the coordinator returns the data to the client. Since all replica nodes need to acknowledge, the read operation is the slowest in this case. Moreover, if one of the replica nodes is down during the read operation, it fails, and availability suffers. The best practice is not to use this option in production deployment.
We can configure the consistency level for each write query or at the global query level.
The diagram below shows a couple of examples of CL on read:
6. Strong Consistency
Strong consistency means you are reading the latest written data into the cluster no matter how much time between the latest write and subsequent read.
We saw in the earlier sections how we could specify desired consistency level (CL) for writes and reads.
Strong consistency can be achieved if W + R > RF, where R – read CL replica count, W – write CL replica count, RF – replication factor.
In this scenario, you get a strong consistency since all client reads always fetches the most recent written data.
Let’s look at a couple of examples of strong consistency levels:
6.1. Write CL = QUORUM and Read CL = QUORUM
If RF = 3, W = QUORUM or LOCAL_QUORUM, R = QUORUM or LOCAL_QUORUM, then W (2) + R (2) > RF (3)
In this case, the write operation makes sure two replicas have the latest data. Then the read operation also makes sure it receives the data successfully only if at least two replicas respond with consistent latest data.
6.2. Write CL = ALL and Read CL = ONE
If RF = 3, W = ALL, R = ONE, then W (3) + R (1) > RF (3)
In this case, once the coordinator writes data to all the replicas, the write operation is successful. Then it’s enough to read the data from one of those replicas to make sure we read the latest written data.
But as we learned earlier, write CL of ALL is not fault-tolerant, and the availability suffers.
7. Conclusion
In this article, we looked at data replication in Cassandra. We also learned about the different consistency level options available on data write and read. Additionally, we looked at a couple of examples to achieve strong consistency.

















