

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
1. Overview
Optimizing code for performance is a key part of programming, especially when dealing with expensive operations or data retrieval processes. One effective way of improving performance is caching.
The Project Reactor library provides a cache() method to cache expensive operations or data that hardly changes to avoid repeat operations and improve performance.
In this tutorial, we’ll explore memoization, a form of caching, and demonstrate how to use Mono.cache() from the Project Reactor library to cache the results of the HTTP GET request to JSONPlaceholder API. Also, we’ll understand the internals of Mono.cache() method through a marble diagram.
2. Understanding Memoization
Memoization is a form of cache that stores the output of expensive function calls. Then, it returns the cached result when the same function call occurs again.
It’s useful in a case involving recursive functions or computations that always produce the same output for a given input.
Let’s see an example that demonstrates memoization in Java using the Fibonacci sequence. First, let’s create a Map object to store the cache the result:
private static final Map<Integer, Long> cache = new HashMap<>();Next, let’s define a method to compute the Fibonacci sequence:
long fibonacci(int n) {
if (n <= 1) {
return n;
}
if (cache.containsKey(n)) {
return cache.get(n);
}
long result = fibonacci(n - 1) + fibonacci(n - 2);
logger.info("First occurrence of " + n);
cache.put(n, result);
return result;
}In the code above, we check if the integer n is already stored in the Map object before further computation. If it’s already stored in the Map object, we return the cached value. Otherwise, we compute the result recursively and store it in the Map object for future use.
This method significantly improves the performance of the Fibonacci calculation by avoiding redundant computations.
Let’s write a unit test for the method:
@Test
void givenFibonacciNumber_whenFirstOccurenceIsCache_thenReturnCacheResultOnSecondCall() {
assertEquals(5, FibonacciMemoization.fibonacci(5));
assertEquals(2, FibonacciMemoization.fibonacci(3));
assertEquals(55, FibonacciMemoization.fibonacci(10));
assertEquals(21, FibonacciMemoization.fibonacci(8));
}In the test above, we invoke the fibonacci() to compute sequences.
3. Describing Mono.cache() with Marble Diagram
The Mono.cache() operator helps cache the result of a Mono publisher and return the cached value for subsequent subscriptions.
The marble diagram helps to understand the internal details of reactive classes and how they work. Here’s a marble diagram that illustrates the behavior of the cache() operator:
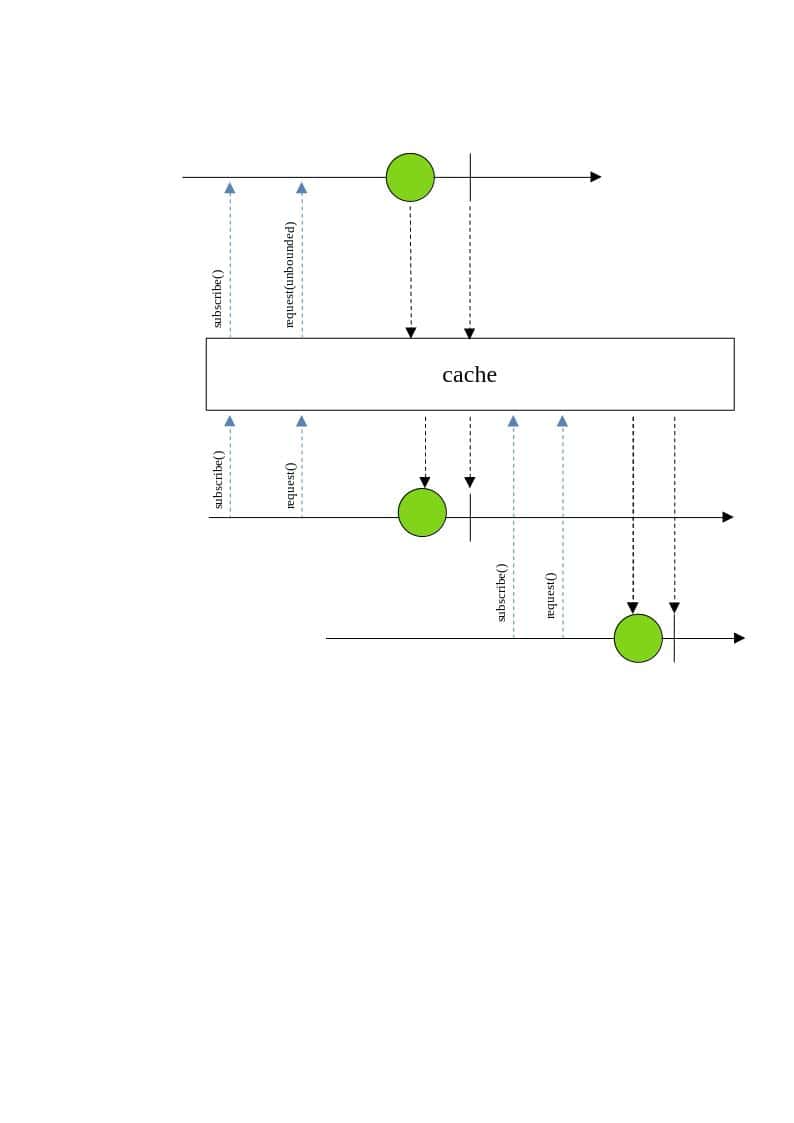
In the image above, the first subscription to the Mono publisher emits data and caches it. Subsequent subscriptions retrieve the cached data without triggering a new computation or data fetch.
4. Example Setup
To demonstrate the usage of Mono.cache(), let’s add reactor-core to the pom.xml:
<dependency>
<groupId>io.projectreactor</groupId>
<artifactId>reactor-core</artifactId>
<version>3.6.5</version>
</dependency>
The library provides operators, Mono, Flux, etc., to implement reactive programming in Java.
Also, let’s add spring-boot-starter-webflux to the pom.xml:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
<version>3.2.5</version>
</dependency>
The above dependency provides the WebClient class to consume an API.
Also, let’s see a sample response when we get a GET request to https://jsonplaceholder.typicode.com/users/2:
{
"id": 2,
"name": "Ervin Howell",
"username": "Antonette"
// ...
}Next, let’s create a POJO class named User to deserialize the JSON response from the GET request:
public class User {
private int id;
private String name;
// standard constructor, getter and setter
}Furthermore, let’s create a WebClient object and set the base URL for the API:
WebClient client = WebClient.create("https://jsonplaceholder.typicode.com/users");This serves as the base URL for the HTTP response that will be cached using the cache() method.
Finally, let’s create an AtomicInteger object:
AtomicInteger counter = new AtomicInteger(0);The object above helps to keep track of the number of times we make a GET request to the API.
5. Fetching Data Without Memoization
Let’s start by defining a method that fetches a user from the WebClient object:
Mono<User> retrieveOneUser(int id) {
return client.get()
.uri("/{id}", id)
.retrieve()
.bodyToMono(User.class)
.doOnSubscribe(i -> counter.incrementAndGet())
.onErrorResume(Mono::error);
}In the code above, we retrieve a user with a specific ID and map the response body to a User object. Also, we increment the counter on every subscription.
Here’s a test case that demonstrates fetching a user without caching:
@Test
void givenRetrievedUser_whenTheCallToRemoteIsNotCache_thenReturnInvocationCountAndCompareResult() {
MemoizationWithMonoCache memoizationWithMonoCache = new MemoizationWithMonoCache();
Mono<User> retrieveOneUser = MemoizationWithMonoCache.retrieveOneUser(1);
AtomicReference<User> firstUser = new AtomicReference<>();
AtomicReference<User> secondUser = new AtomicReference<>();
Disposable firstUserCall = retrieveOneUser.map(user -> {
firstUser.set(user);
return user.getName();
})
.subscribe();
Disposable secondUserCall = retrieveOneUser.map(user -> {
secondUser.set(user);
return user.getName();
})
.subscribe();
assertEquals(2, memoizationWithMonoCache.getCounter());
assertEquals(firstUser.get(), secondUser.get());
}Here, we subscribe to the retrieveOneUser Mono twice, and each subscription triggers a separate GET request to the WebClient object. We assert that the counter increments twice.
6. Fetching Data With Memoization
Now, let’s modify the previous example to leverage Mono.cache() and cache the result of the first GET request:
@Test
void givenRetrievedUser_whenTheCallToRemoteIsCache_thenReturnInvocationCountAndCompareResult() {
MemoizationWithMonoCache memoizationWithMonoCache = new MemoizationWithMonoCache();
Mono<User> retrieveOneUser = MemoizationWithMonoCache.retrieveOneUser(1).cache();
AtomicReference<User> firstUser = new AtomicReference<>();
AtomicReference<User> secondUser = new AtomicReference<>();
Disposable firstUserCall = retrieveOneUser.map(user -> {
firstUser.set(user);
return user.getName();
})
.subscribe();
Disposable secondUserCall = retrieveOneUser.map(user -> {
secondUser.set(user);
return user.getName();
})
.subscribe();
assertEquals(1, memoizationWithMonoCache.getCounter());
assertEquals(firstUser.get(), secondUser.get());
}The major difference from the previous example is that we invoke the cache() operator on the retrieveOneUser object before subscribing to it. This caches the result of the first GET request, and subsequent subscriptions receive the cached result instead of triggering a new request.
In the test case, we assert that the counter increment once since the second subscription uses the cached value.
7. Setting a Cache Duration
By default, Mono.Cache() caches the result indefinitely. However, in a scenario where the data could become stale over time, it’s essential to set a cache duration:
// ...
Mono<User> retrieveOneUser = memoizationWithMonoCache.retrieveOneUser(1)
.cache(Duration.ofMinutes(5));
// ...In the code above, the cache() method accepts an instance of Duration as a parameter. The cached value will expire after 5 minutes, any subsequent subscriptions after will trigger a new GET request.
8. Conclusion
In this article, we learned the key concept of memorization and its implementation in Java using the Fibonacci sequence example. Then, we deep dive into the usage of Mono.cache() from the Project Reactor library and demonstrate how to cache the results of HTTP GET requests.
Caching is a powerful technique for improving performance. However, it’s essential to consider cache invalidation strategies to ensure that stale data is not served indefinitely.


















