

Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
Elasticseach is a tool used for analytics and full-text search, and it’s most likely one of the leading open-source projects for this kind of purpose. Moreover, Elasticsearch is a distributed tool engine that can handle a large volume of data, and it’s built on top of the Apache Lucene project.
In this tutorial, we’ll explore this tool’s horizontal scaling, fault tolerance, and high availability capabilities. Hopefully, by the end of it, we’ll understand all its nuances and how to get the best out of it.
2. Shards
A key aspect that allows Elasticsearch to be a fault-tolerance and scalable tool is the ability to distribute data across multiple nodes. Shards are building blocks representing a subset of the data stored in the index. Not just that, a shard is a Lucene index defined and stored within a node, while the collection of one or more shards represents an Elacticsearch index. Shards are used as a way to distribute data horizontally across the cluster nodes/members.
Elacticsearch indexes represent a set of data distributed across the Elasticsearch cluster. A cluster is a group of machines running Elasticsearch that can communicate with each other. This means one cluster can contain multiple indexes and, therefore, various shards. Such shards improve fault tolerance by removing the single point of failure caused by the possibility of storing all the data in a single node.
The distribution of the shards across the nodes guarantees in case of loss, or when the node goes down, only a sub-part of the data becomes unavailable, but the cluster can continue serving the other part. Another benefit is stability, as each shard will try to handle the request concurrently, which may optimize the use of the cluster’s resources and result in better performance. Of course, this depends on several factors, like index size, instance size, and node load.
Sharding also reduces the amount of data Elasticsearch needs to scan to fulfill each request by distributing each across different instances and therefore parallelizing the execution of the query. However, this has its price, and when sharding an index, we add some extra costs like coordination and communication between nodes.
2.1. Specifications
In the current Elasticsearch version (8.7), when creating an index without specifying the desired number of shards, the engine will fall back to the default value, in this case, 1. In order to determine the desired number of shards, we need to add the settings.index.number_of_shards property when creating our index. It’s important to note that this setting is a static property, meaning changing them after creation is impossible.
Elasticsearch takes care of assigning each shard to a node, and once that happens, each allocated shard receives a shard ID that identifies and locates such a shard in the cluster.
Those shards are primary shards, primary shards responsible for all the write operations assigned to them. For example, the image below illustrates a valid cluster setup:
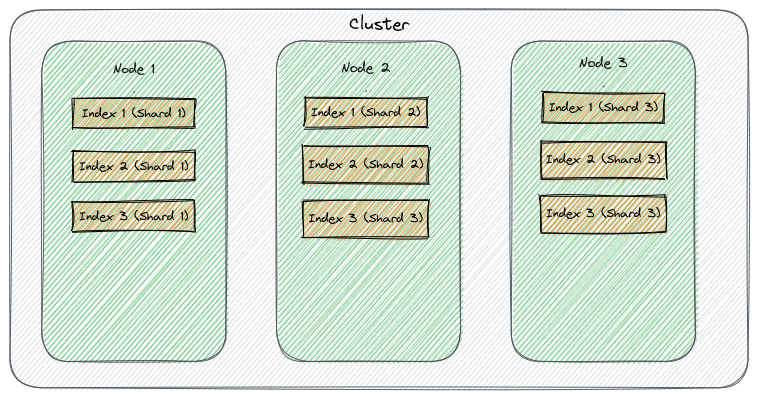
By default, Elasticsearch applies a formula to determine the shard to which an indexing request for a given document will be routed. This routing function uses the document ID, although it can be changed to use a different parameter or field.
Elasticsearch does this to ensure the shards stay in balance, and the algorithm is deterministic, meaning a given id will always go to the same shard.
3. Replicas
As mentioned, primary shards are super important as they hold all the data of our indexes and process requests like queries, indexing, and other operations. So that makes them critical to the normal functioning of the cluster.
We can imagine that losing one of those shards due to some hardware failure, data corruption, or any other kind of issue is dangerous. Luckily Elasticsearch has some mechanisms to prevent that from happening.
Replicas are exact copies of primary shards that live in different nodes, and we use them to improve the cluster’s availability and fault tolerance resilience. Given that each replica correlates with a primary shard, in the event of any critical incident with the primary shard, a replica can take its place and become a primary shard making sure data remains available.
That is the reason why a replica cannot be in the node as its primary shard. Otherwise, this would defeat its purpose.
It’s also important to understand that replicas are not read-only shards. They can actually receive write operations, but only from the primary ones they are related to. Another interesting point is that they increase the cluster throughput, as they also handle read requests and help spread the cluster load.
3.1. Specifications
Once again, referring to the current Elasticsearch version (8.7), when creating an index without specifying the desired number of replicas, the engine will fall back to the default value, in this case, 1. In order to determine the desired number of replicas, we need to add the settings.index.number_of_replicas property when creating our index. As opposed to the number of shards, the number of replicas can change during the life cycle of the index.
Elasticsearch takes care of assigning each replica to a node, taking into consideration the location of the primary shard:
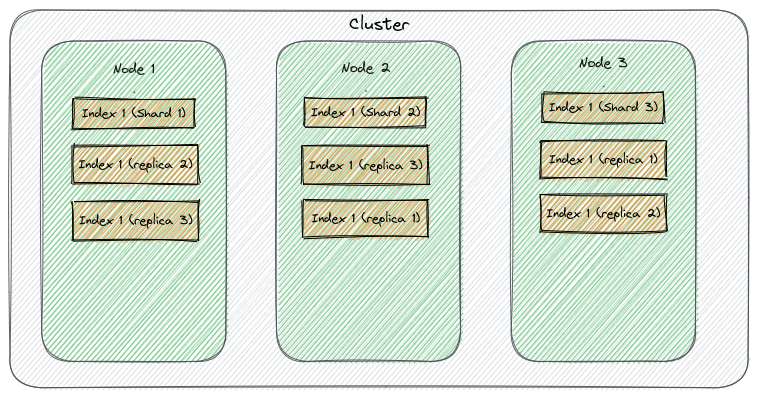
Another relevant property that is worth mentioning is the settings.index.auto_expand_replicas that allows expanding the number of replicas as more nodes join the cluster.
Elasticsearch indexes have statuses that indicate the index’s health. The respective status values are the following:
- Green: all the shards are allocated to at least one node in the cluster, and there are enough replicas to provide redundancy as configured.
- Yellow means that all primary shards are available, but not all replicas are available. This could be due to one or more replicas being unallocated or missing.
- Red: it means that one or more primary shards are not available. This could be due to one or more primary shards being unallocated or missing.
4. Cluster Setup
When defining the setup of a cluster is essential to ask the right questions to guarantee a good service level and appropriate budget spending. For example, it’s crucial to have a rough estimation of the load and the kind of data to define proper sharding. The same is valid for replication. It’s critical to know the right level of redundancy.
Let’s see some common mistakes and pitfalls.
4.1. Over-Replicating or Under-Replicating
Elasticsearch provides replicating capabilities to promote high availability and fault tolerance. However, this has its cost in terms of storage and network traffic, which means an overhead in the cluster. On the other hand, the lack of replication can lead to a risk of data loss. Hence, considering the use case’s requirements, balancing those two extremes is essential.
4.2. Uneven Shard Distribution
Similar to the previous point, having too many shards can lead to overprovisioning and high costs. However, too few shards can lead to performance issues due to hotspots. Then defining the sharding is important to consider the data volume, the query patterns, and instance size.
4.3. Poor Shard Allocation
Related to the number of nodes in the cluster, poor shard allocation can lead to slow query performance and uneven distribution of operations between the node of the cluster and, therefore, overloading specific nodes in the cluster while others are underused.
4.4. Inappropriate Sync/Refresh Intervals
Based on properties like settings.index.refresh_interval and settings.index.translog.sync_interval or even the Flush APIS, Elasticsearch can balance durability and performance. Those configurations can heavily impact the health and performance of the nodes because they may increase disk I/O and CPU consumption if set to frequent updates or cause data loss if set to more extended periods. So they need to be managed with caution depending on the use case.
5. Conclusion
Elasticsearch is a complex tool that offers many options to adjust its behavior to our use case. Consequently, it requires us to have a good level of understanding of its nuances.
In this article, we discussed Elasticsearch shards and replicas. We saw how to combine them in order to achieve a highly available, resilient, and fault-tolerant cluster. Moreover, we understood how they also impact the overall cluster performance and health.
Hopefully, now we can know more about this tool and how to leverage its capabilities best and avoid some common mistakes.


















