Apache Camel’s KServe Component: Inference via Model Serving
Last updated: September 19, 2025


Mocking is an essential part of unit testing, and the Mockito library makes it easy to write clean and intuitive unit tests for your Java code.
Get started with mocking and improve your application tests using our Mockito guide:
Handling concurrency in an application can be a tricky process with many potential pitfalls. A solid grasp of the fundamentals will go a long way to help minimize these issues.
Get started with understanding multi-threaded applications with our Java Concurrency guide:
Spring 5 added support for reactive programming with the Spring WebFlux module, which has been improved upon ever since. Get started with the Reactor project basics and reactive programming in Spring Boot:
Since its introduction in Java 8, the Stream API has become a staple of Java development. The basic operations like iterating, filtering, mapping sequences of elements are deceptively simple to use.
But these can also be overused and fall into some common pitfalls.
To get a better understanding on how Streams work and how to combine them with other language features, check out our guide to Java Streams:
Explore Spring Boot 3 and Spring 6 in-depth through building a full REST API with the framework:
Yes, Spring Security can be complex, from the more advanced functionality within the Core to the deep OAuth support in the framework.
I built the security material as two full courses - Core and OAuth, to get practical with these more complex scenarios. We explore when and how to use each feature and code through it on the backing project.
You can explore the course here:
Spring Data JPA is a great way to handle the complexity of JPA with the powerful simplicity of Spring Boot.
Get started with Spring Data JPA through the guided reference course:
Refactor Java code safely — and automatically — with OpenRewrite.
Refactoring big codebases by hand is slow, risky, and easy to put off. That’s where OpenRewrite comes in. The open-source framework for large-scale, automated code transformations helps teams modernize safely and consistently.
Each month, the creators and maintainers of OpenRewrite at Moderne run live, hands-on training sessions — one for newcomers and one for experienced users. You’ll see how recipes work, how to apply them across projects, and how to modernize code with confidence.
Join the next session, bring your questions, and learn how to automate the kind of work that usually eats your sprint time.
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
1. Overview
In today’s fast-paced world of AI service development, there is a vast array of pre-trained AI models and numerous model-serving platforms, such as TensorFlow and NVIDIA Triton, available to host them. In the Java ecosystem, the primary focus is on integrating applications with model-serving servers, enabling efficient communication with AI models.
Apache Camel’s KServe component offers a streamlined solution for AI model inference by facilitating interaction with KServe-compliant model servers. This component simplifies the communication between Java applications and the model servers that host the trained AI models.
In this tutorial, we’ll explore the tools necessary for enabling Java applications to interact with AI models. Additionally, we’ll walk through a practical example of a Java service that uses AI to analyze user-provided sentences and determine whether they express positive or negative sentiment.
2. High-Level Overview of the Tools
To integrate our Java application with an AI model, we require a trained AI model, a host to serve the model, and our Java application with a framework that facilitates easy integration with the host.
The model can be of any type, such as TensorFlow, PyTorch, ONNX, OpenVINO, etc. The host should be any host that supports the KServe Open Inference Protocol (OIP) V2, such as the latest versions of NVIDIA Triton.
Next, let’s have a quick look at the exact tools, protocols, and frameworks that we’re going to use in our application:
- KServe (formerly KFServing) is a Kubernetes-based tool for serving machine learning models. It’s designed to simplify deploying and managing ML models on Kubernetes, with features like autoscaling, rolling updates, and model versioning. KServe integrates well with tools like TensorFlow, PyTorch, and scikit-learn, making it easier to deploy these models at scale.
- Open Inference Protocol V2 is a standardized communication protocol. It was first introduced and used in the KServe project. Now, the protocol is supported by multiple backends, not just KServe.
- Apache Camel is an open-source integration framework that enables the integration of different systems using a variety of protocols and technologies. Camel has a ton of components, so it can work with almost any kind of technology we throw at it—HTTP, JMS, databases, and more. More specifically, Apache Camel’s KServe component makes integration with systems that support the KServe Open Inference Protocol (OIP) V2.
- NVIDIA Triton is an open-source model-serving platform designed for high-performance AI inference. It supports a variety of popular frameworks such as TensorFlow, PyTorch, and ONNX, allowing organizations to deploy models at scale with flexibility.
- Hugging Face is a leading platform in the natural language processing (NLP) space. It offers a wide range of pre-trained models and tools for NLP tasks like text classification, translation, and sentiment analysis. This is where we’ll get our trained AI model for our service as well.
3. Sentiments Service Using a Pre-Trained AI Model
For our demonstration, let’s create a practical application that accepts a sentence and predicts if the sentiment of the sentence is good or bad. All we need is a pre-trained AI model, a host for the model, and a Java application that will offer a more user-friendly experience.
3.1. Setting up the Pre-Trained AI Model of Sentiments
It’s not in the scope of this article to create, train, etc, an AI Model. We’ll use one existing from Hugging Face and more specifically, we’ll download the pre-trained model pjxcharya/onnx-sentiment-model. This model accepts a sentence, after being converted to the proper tokens, and responds with two numbers, one negative and one positive. If the negative’s absolute value is larger, then the sentiment is bad, or else it’s good.
The only things we need to do before we move on are to understand the inputs and outputs of the model. We’ll need those things later, when we use Apache Camel’s KServe Component to interact with the server. One easy way to do this is to use the online tool netron.app that provides the graph of the model and the properties:
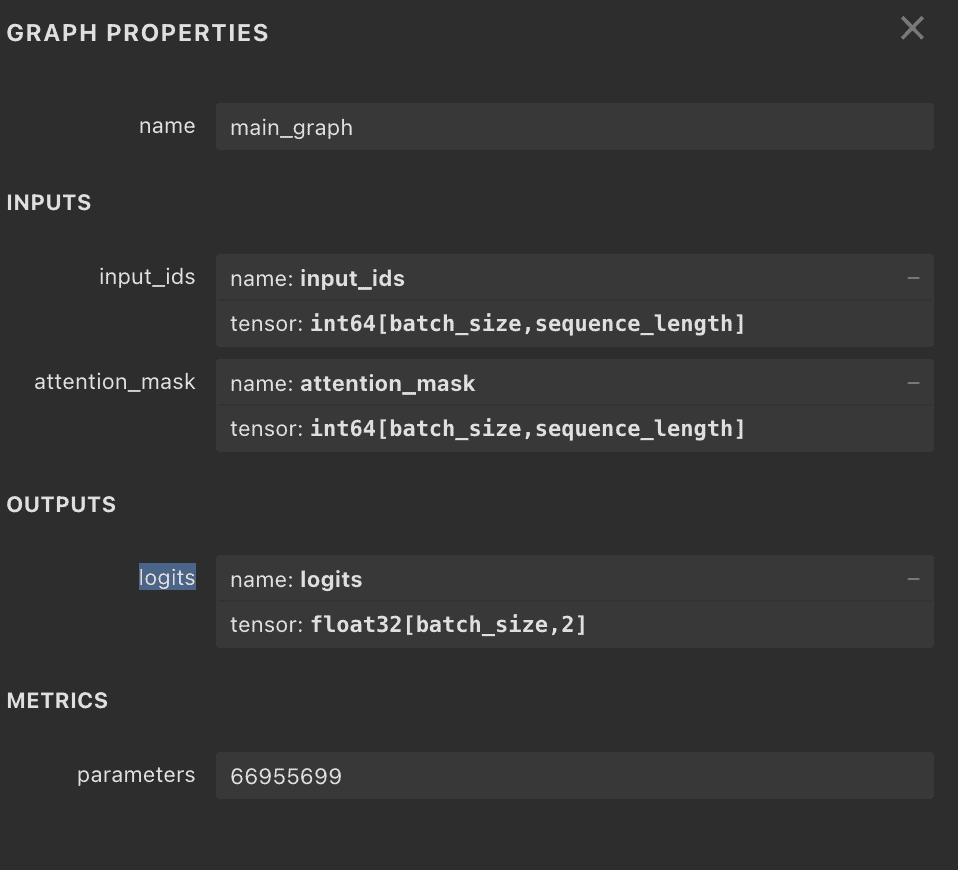
From the picture, we see that our inputs are input_ids and attention_mask, both of type int64. The output is logits of type float32.
3.2. Setting up the Triton Model Serving Server
NVIDIA’s Triton model Server can host our model of type ONNX. First, we put the ONNX model file in models/sentiment/1/model.onnx, and then we create the configuration file models/sentiment/config.pbtxt:
name: "sentiment"
platform: "onnxruntime_onnx"
max_batch_size: 8
input [
{
name: "input_ids"
data_type: TYPE_INT64
dims: [ -1 ]
},
{
name: "attention_mask"
data_type: TYPE_INT64
dims: [ -1 ]
}
]
output [
{
name: "logits"
data_type: TYPE_FP32
dims: [ 2 ]
}
]Here we set the name of the model and the names and types of input and output.
Finally, we create a Dockerfile to make it easily deployable:
FROM nvcr.io/nvidia/tritonserver:25.02-py3
# Copy the model repository into the container
COPY models/ /models/
# Expose default Triton ports
EXPOSE 8000 8001 8002
# Set entrypoint to run Triton with your model repo
CMD ["tritonserver", "--model-repository=/models"]All we need to do is copy the models folder into the container and set it as the model-repository.
3.3. The Web Service Using Apache Camel’s KServe Component
Apache Camel can be used to communicate with a model server just by using HTTP or gRPC. However, with Apache Camel’s KServe Component, the interaction is more straightforward and better suited for any model server that supports the KServe V2 protocol.
Let’s start by setting the dependencies for using the KServe component. Note that the component is available from 4.10.0 and later versions:
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-main</artifactId>
<version>4.13.0</version>
</dependency>
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-kserve</artifactId>
<version>4.13.0</version>
</dependency>Next, we proceed by creating the Apache Camel Kserve route, which takes the request (in our case, it’s an HTTP request) and routes it to a call to the Triton Server:
public class SentimentsRoute extends RouteBuilder {
@Override
public void configure() {
// (code that configures the REST incoming call)
// Main route
from("direct:classify")
.routeId("sentiment-inference")
.setBody(this::createRequest)
.setHeader("Content-Type", constant("application/json"))
.to("kserve:infer?modelName=sentiment&target=localhost:8001")
.process(this::postProcess);
}
// ...
}Assuming we have set the configuration to accept the incoming REST call and route it to “direct:classify”, we set the route to integrate with the Triton Server. The createRequest() method creates the body of the request, and postProcess() handles the response, as we’ll see later in this tutorial. The endpoint for the KServer protocol starts with “kserve:…”, then the method, which is usually infer for Triton. The modelName and target properties are set to point to the correct URL and model (note that for our case, using Docker Compose, we’ll need to set the host to host.docker.internal).
3.4. Handling Apache Camel’s KServe Component Input
Apache Camel provides a rich library for creating requests for our routes. The KServe Component adds the InferTensorContents class to create objects for the request. It allows us to set the data type of the model’s attribute, name, shapes, content, and more:
private ModelInferRequest createRequest(Exchange exchange) {
String sentence = exchange.getIn().getHeader("sentence", String.class);
Encoding encoding = tokenizer.encode(sentence);
List<Long> inputIds = Arrays.stream(encoding.getIds()).boxed().collect(Collectors.toList());
List<Long> attentionMask = Arrays.stream(encoding.getAttentionMask()).boxed().collect(Collectors.toList());
var content0 = InferTensorContents.newBuilder().addAllInt64Contents(inputIds);
var input0 = ModelInferRequest.InferInputTensor.newBuilder()
.setName("input_ids").setDatatype("INT64").addShape(1).addShape(inputIds.size())
.setContents(content0);
var content1 = InferTensorContents.newBuilder().addAllInt64Contents(attentionMask);
var input1 = ModelInferRequest.InferInputTensor.newBuilder()
.setName("attention_mask").setDatatype("INT64").addShape(1).addShape(attentionMask.size())
.setContents(content1);
ModelInferRequest requestBody = ModelInferRequest.newBuilder()
.addInputs(0, input0).addInputs(1, input1)
.build();
return requestBody;
}As noted earlier, we need to create a request with two inputs. The tokenizer object comes from the ai.djl.huggingface:tokenizers dependency and helps us encode the human-readable String to encoding.ids that our model accepts. This is all we need for the request to the Triton Server.
3.5. Handling Apache Camel’s KServe Component Output
Similarly, we can use the ModelInferResponse class to receive the response from the model serving server:
private void postProcess(Exchange exchange) {
ModelInferResponse response = exchange.getMessage().getBody(ModelInferResponse.class);
List<List<Float>> logits = response.getRawOutputContentsList().stream()
.map(ByteString::asReadOnlyByteBuffer)
.map(buf -> buf.order(ByteOrder.LITTLE_ENDIAN).asFloatBuffer())
.map(buf -> {
List<Float> longs = new ArrayList<>(buf.remaining());
while (buf.hasRemaining()) {
longs.add(buf.get());
}
return longs;
})
.toList();
String result = Math.abs(logits.getFirst().getFirst()) < logits.getFirst().getLast() ? "good" : "bad";
exchange.getMessage().setBody(result);
}Here, we use the getRawOutputContentsList() method to translate the bytes to float numbers and compare the negative to the positive, to understand if the prediction is good or bad sentiment.
3.6. Demonstration Using Docker Compose
Let’s create a docker-compose.yml file to easily spin up both the Triton Server and our Java applications:
services:
triton-server:
build: ./triton-server
environment:
- NVIDIA_VISIBLE_DEVICES=all
ports:
- "8000:8000" # HTTP
- "8001:8001" # gRPC
- "8002:8002" # Metrics
sentiment-service:
build: ./sentiment-service
ports:
- "8080:8080"After we spin up the services, we can request our Java service to test the bad sentiment:
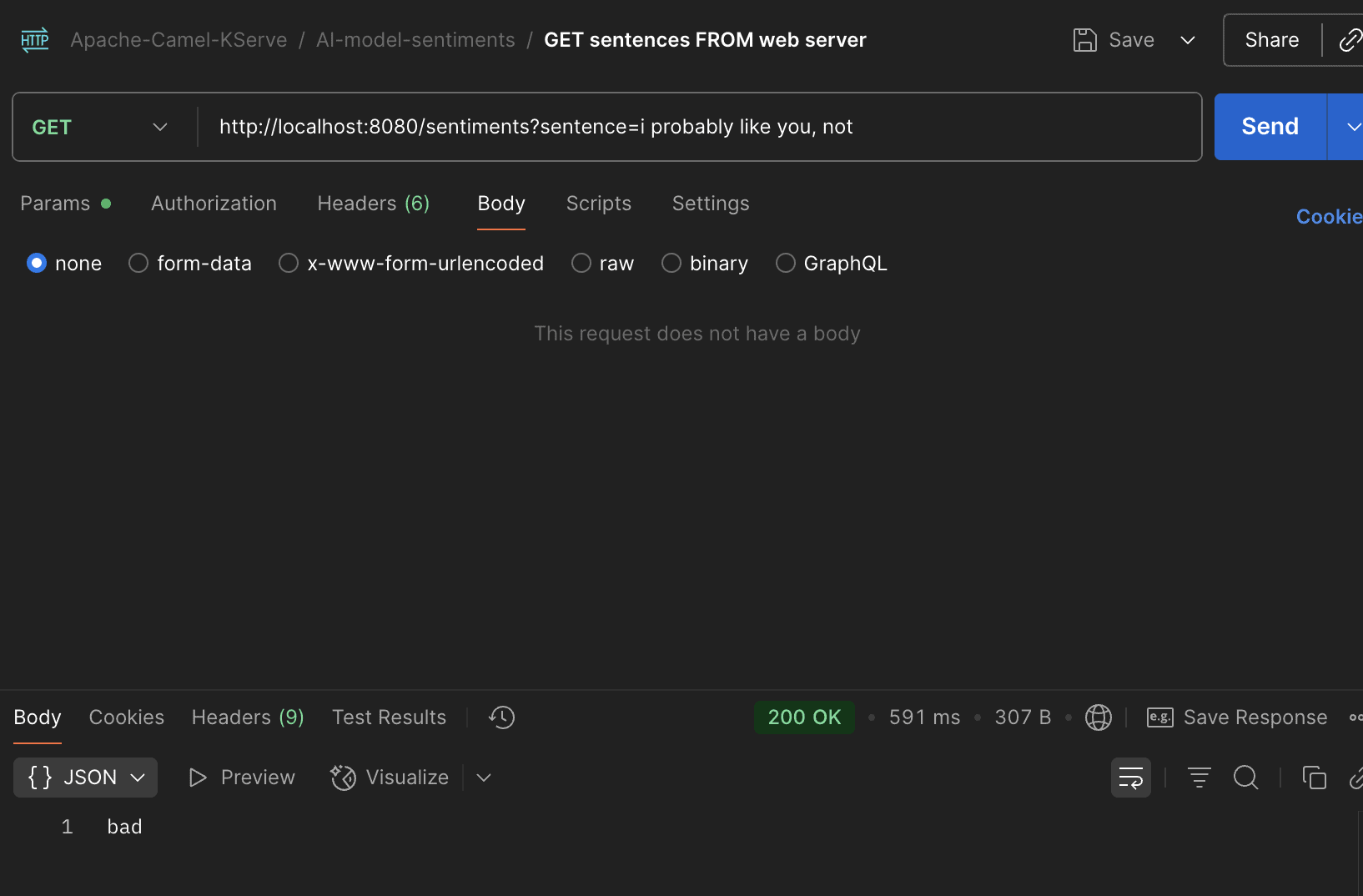
And the good sentiment:
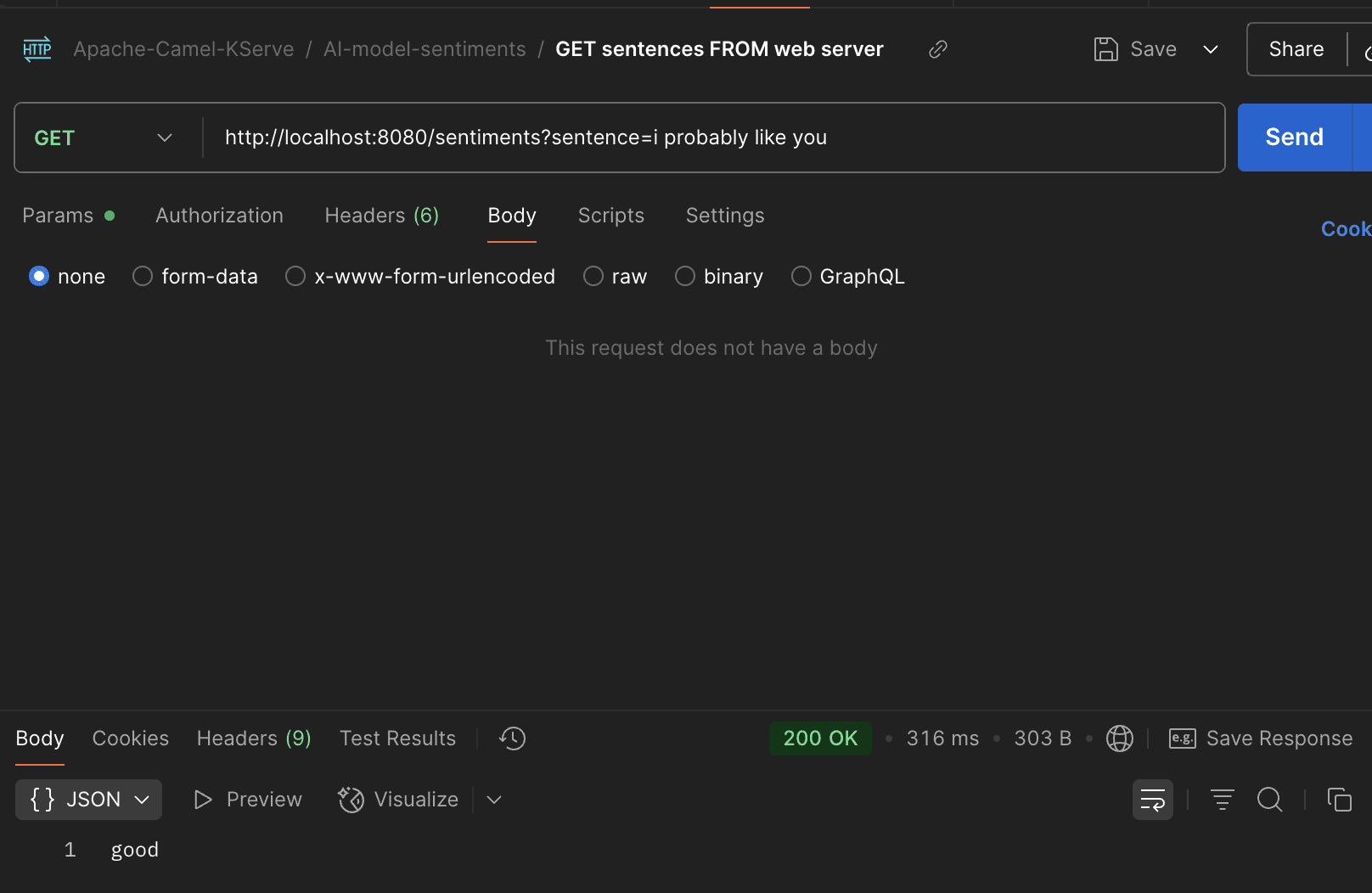
We see in the pictures that the model works as expected through our web service.
4. Conclusion
In this article, we demonstrated how to create a Java application with AI model inference, using Apache Camel’s KServe component. We used Apaceh Camel to easily integrate with the model serving host Triton. We pre-loaded Triton with an AI model that offers predictions about the sentiment of the provided sentence (good or bad).


















