

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Vector databases are storage systems specially designed to store high-dimensional vectors. They commonly store and query data in Machine Learning (ML) systems.
Unlike conventional databases, which store data as scalars, vector databases store vectors. This allows for fast retrieval of data where exact matches aren’t relevant.
These vectors can store different data types, such as images, documents, and audio. We can use several techniques, such as feature extraction, to convert unstructured data into vector data.
In this tutorial, we’ll see how and where vector databases are used.
Vector databases specialize in indexing and querying vector data efficiently. They employ various techniques such as hashing, quantization, or graph-based methods to organize and index the data effectively:
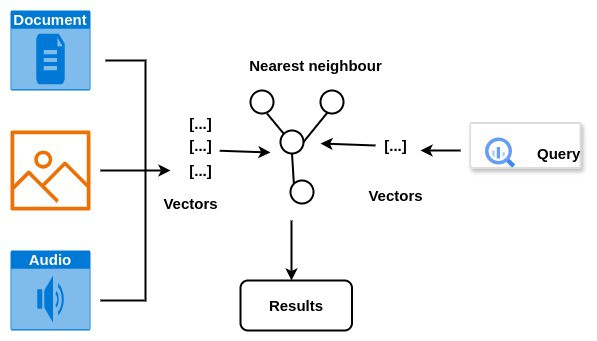
In vector databases, vectors representing similar meanings are stored near each other. This proximity is typically measured on a scale of 0 to 1, where a value close to 1 indicates a high similarity in meaning between two data objects.
Conversely, values close to zero suggest lower similarity. This organization facilitates faster retrieval of similar data objects, enabling tasks such as similarity search and content-based recommendation.
An embedding is a numerical value that represents some unstructured data. A machine learning model assigns embeddings during training. These values are expressed as n-dimensional vectors, with each dimension representing a data property.
Embeddings that are closely related are stored close to each other within a vector space.
To determine the closeness in relation between the data items, we need to measure the distance between a query vector and an embedding. We can achieve this using a distance function. This is simply a function that measures the distance between two vectors.
A distance metric is used to determine the similarity between data. A distance of zero would mean that the elements are an exact match.
There are several distance metrics. They vary because different data require different ways of measuring similarity and dissimilarity between data points. Additionally, the meaning of closeness differs when interpreting various types of data.
Let’s look at some of the most common ones and start with Minkowski distance.
This is a distance defined over a normed vector space. The distance over this space can be calculated using the formula below.
![\[D(x, y) = \left( \sum_{i=1}^{n} |x_i - y_i|^p \right)^{\frac{1}{p}}\]](/wp-content/ql-cache/quicklatex.com-c570dbc0ed0443afaa17b70cff0d51a0_l3.svg "Rendered by QuickLaTeX.com")
This metric is a generalized way of measuring distance between two points in a multi-dimensional space. It encompasses some other common metrics as special cases, depending on the value of p:
For any value of p greater than 2, we refer to it as Chebychev distance.
The next one that we can use is Cosine similarity.
This is the cosine angle between two points in a vector space:

It’s commonly used to find similarities between documents. We use this method when the distance between two vectors is irrelevant, but only the orientation.
The previously discussed distance metrics are used to search or query vector data. Here are some ways to search/query a vector database.
The most popular one is the semantic search. This search aims to query data within a given context to return relevant results. For example, a query for “machine learning algorithms” would retrieve documents containing the exact phrase and those discussing related topics like deep learning or neural networks.
Another variant is full-text search. This involves searching through the entire document to find matches for a query. For example, a full-text search for “dental jobs” would retrieve documents containing these exact words or variations like “dental positions” or “jobs in dental surgery”.
The decision on which vector database to use depends on its design/features and how this fits the project. Here are some of the more popular options:
This is an open-source project with support for both Python and Javascript clients. It ships with everything needed to start building AI applications. Notably, it has plugins for LLM providers like OpenAI, LangChain, and others. We can install Chroma using:
pip install chromaAfter setting this up, we can now see how to create our first collection:

A collection is a storage unit where we can store embeddings. This getting started page describes how to create and query a collection in Python or Javascript.
This is an open-source database written in Rust. It boasts clients in over eight programming languages, including Go, Java, and Javascript. Unlike Chroma, Qdrant currently offers a fully managed solution through Qdrant Cloud. As of this writing, Chroma is also developing its own cloud-based solution. We can install the latest Qdrant Docker image using the following:
docker pull qdrant/qdrantTo start the service, we run:
docker run -p 6333:6333 -p 6334:6334 \
-v $(pwd)/qdrant_storage:/qdrant/storage:z \
qdrant/qdrantWe can now access the REST API through localhost:6333:

Their quickstart page provides examples of how to get started with clients in different languages.
We also want to mention some notable solutions on this list that support vector data, such as Redis and PostgreSQL databases.
These two databases deserve special attention on this list since they weren’t specifically built to handle vector data but have capabilities for storing and managing it.
In this article, we have seen that vector databases are specialized storage systems for high-dimensional data. Additionally, they can be used for efficient similarity searches.