

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll take a look at a type of data structure called a B-tree and a variation of it – B+tree. We’ll learn about their features, how they’re created, and how they’re used effectively in Database Management Systems for creating and managing indexes.
Finally, we’ll use the knowledge we’ve gained to compare B-trees and B+trees.
B-trees are a type of self-balancing tree structure designed for storing huge amounts of data for fast query and retrieval. They can be often confused with their close relation – the Binary Search Tree. Although they’re both a type of m-way search tree, the Binary Search Tree is considered to be a special type of B-tree.
B-trees can have multiple key/value pairs in a node, sorted ascendingly by key order. We call this key/value pair a payload. Occasionally we may hear the value part of the payload being referred to as “satellite data” or just “data”.
In the context of databases, a key may be the primary key or indexed column of a row, and the value could be the actual row record itself or a reference to it.
In addition to the payload, nodes also keep references to their children. Since each node typically takes up a disk page, these child references usually refer to the page ID in which the child node lives in secondary storage. As any search tree, B-trees are organized so that the keys of any sub-tree must be larger than the keys of the sub-tree to its left.
For a tree to be classified as a B-tree, it must fulfill the following conditions:
 can have a maximum of children/2) children (rounded up)
can have a maximum of children/2) children (rounded up) children should have
children should have  keys
keysThe image below shows us an example of a B-tree. The maximum number of children in this tree is 3, so we can conclude that this is a tree of order 3. All the leaves are on the same level, and the root and internal nodes have a minimum of two children fulfilling all the conditions of a B-tree:
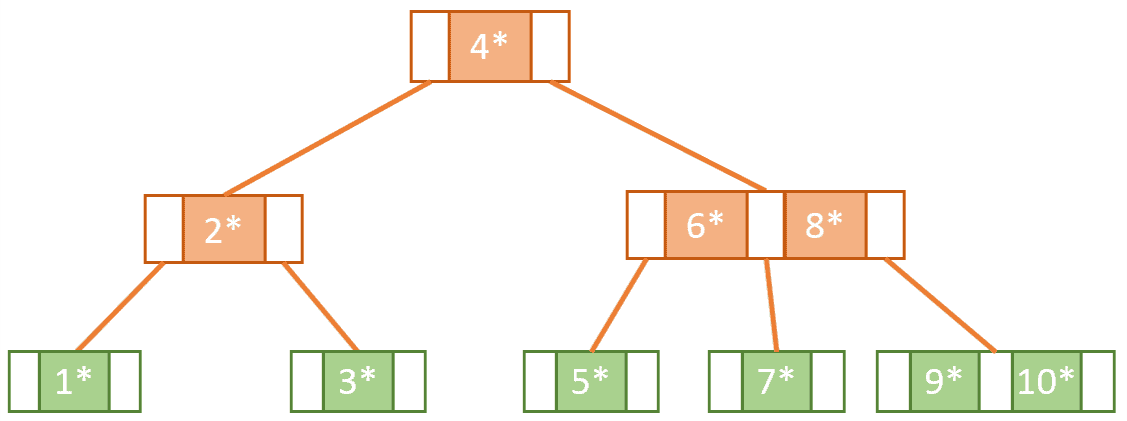
Now, let’s build our tree from scratch. To do this, we’ll learn how to insert items into the tree while keeping it balanced.
Since we’re starting with an empty tree, the first item we insert will become the root node of our tree. At this point, the root node has the key/value pair. The key is 1, but the value is depicted as a star to make it easier to represent, and to indicate it is a reference to a record.


Next, if we wanted to insert 3, for us to keep the tree balanced and fulfilling the conditions of a B-tree we need to perform what is called a split operation.
We can determine how to split the node by picking the middle key. When we choose the middle key we need to consider the keys already present in the node and also the key which is to be inserted. In this case, 2 is the middle key used to split the node. This means the values to the left of 2 will go to a left sub-tree and the values to the right of 2 will go to a right sub-tree and 2 itself will get promoted as part of a new root node:
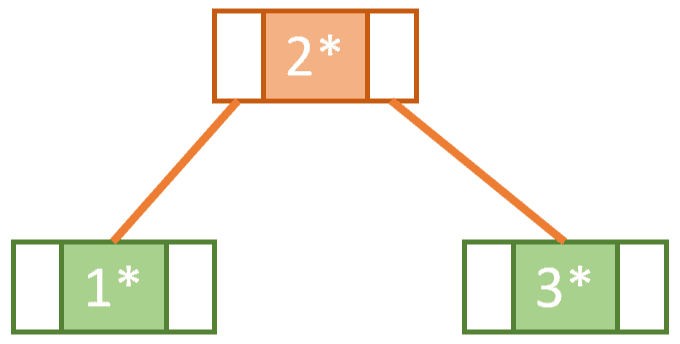
By performing this splitting operation each time we are about to exceed the maximum number of keys in a node, we keep the tree self-balancing.
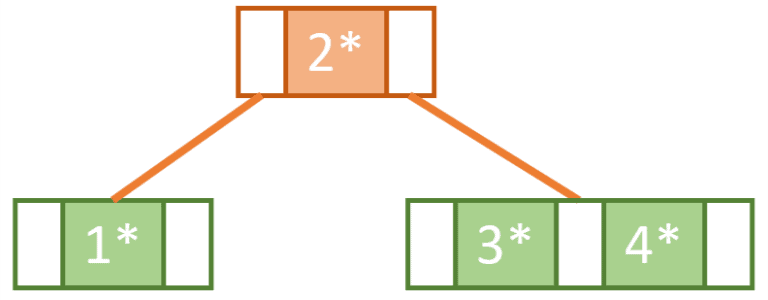
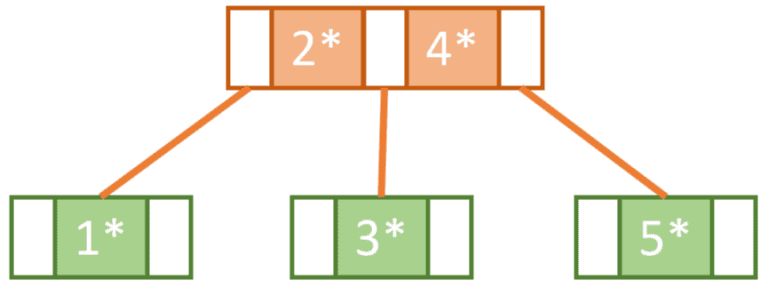
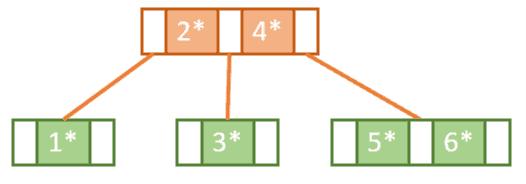
Next, we try to insert 7. However, since the rightmost tree is now at full capacity we know that we need to do another split operation and promote one of the keys.
But wait! The root node is also at full capacity, which means that it also needs to be split.
So, we end up doing this in two steps. First, we need to split the right nodes 5 and 6 so that 7 will be on the right, 5 will be on the left, and 6 will be promoted.
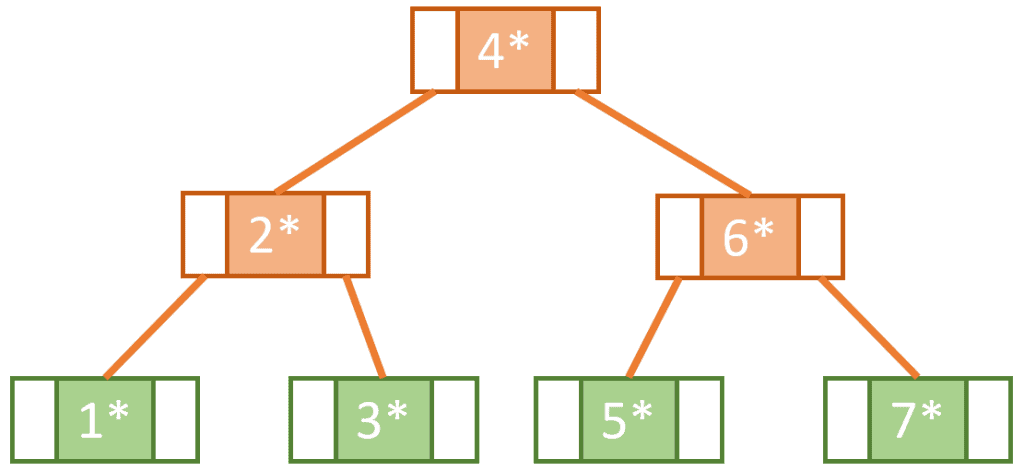
B-trees are considered to be so advantageous because they provide logarithmic  time complexity when it comes to insert, delete, and search operations.
time complexity when it comes to insert, delete, and search operations.
Let’s take a look at how we would perform a search operation on our B-tree using the pseudocode below:
algorithm Search(node, searchKey):
// INPUT
// node = the current node being searched
// searchKey = the key to search for
// OUTPUT
// the value associated with the searchKey if found, otherwise null
i <- 0
while i < node.Payloads.Count and searchKey > node.Payloads[i].Key:
i <- i + 1
if searchKey = node.Payloads[i].Key:
return node.Payloads[i].Value
else if node.IsLeaf = true:
return null
else:
return Search(node.Children[i], searchKey)Our pseudocode assumes the following:
Let’s see how we can apply this pseudocode if we assume that the keys of our tree refer to IDs of a table, and we’d like to search for the record whose ID is 6. That means we’d be calling the Search method defined in the pseudocode with the parameters node = root node of the B-tree and searchKey = 6.
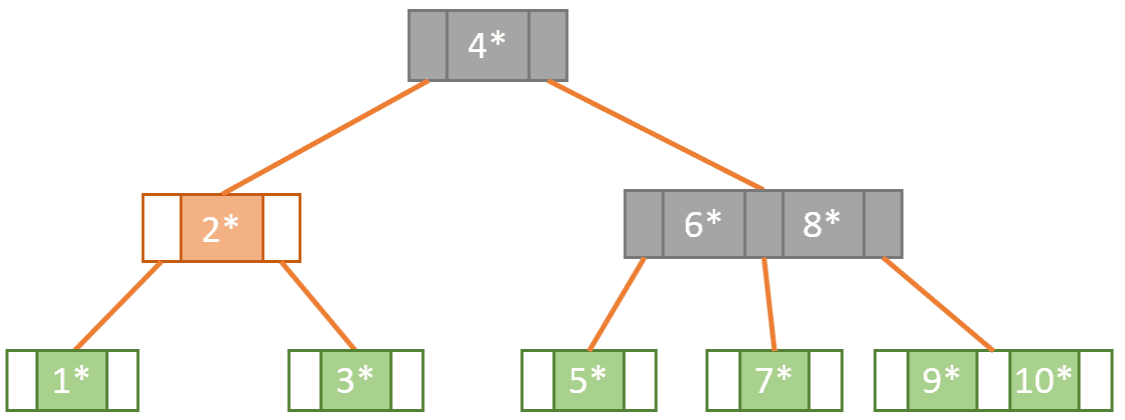
Using a while loop, we iterate through the root node keys increasing our counter value i until we find a key that is greater than or equal to 6 or until we have finished the keys of that node. The loop ends with i being at the value 1.
Now using i = 1 as an index, we select node.Children[1] (the child node at index 1). Iterating through its keys, we find node.Payload[0].Key to be an exact match to our searchKey. We end the search by returning node.Payload[0].Value, which is the satellite data associated with key 6.
The image below shows our search path shaded in grey:
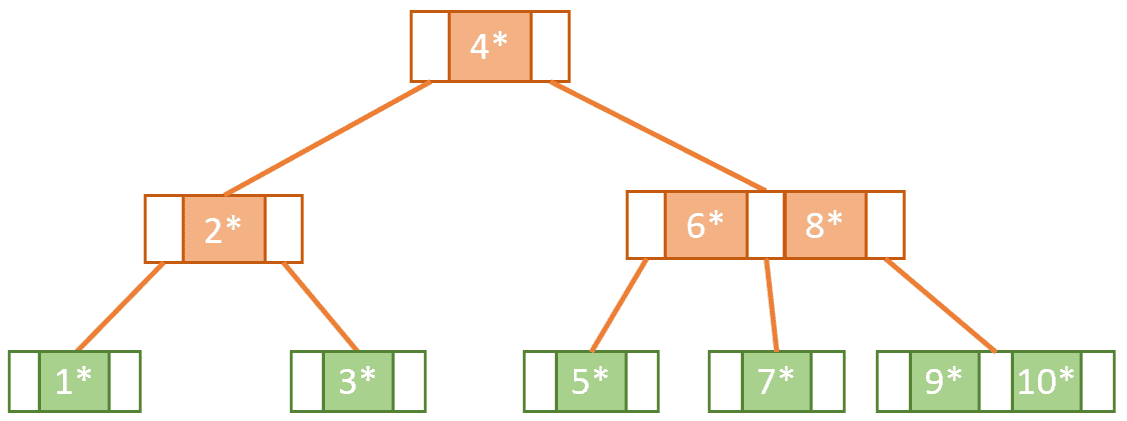
The most well-known version of the B-tree is the B+tree. What distinguishes the B+tree from the B-tree are two main aspects:
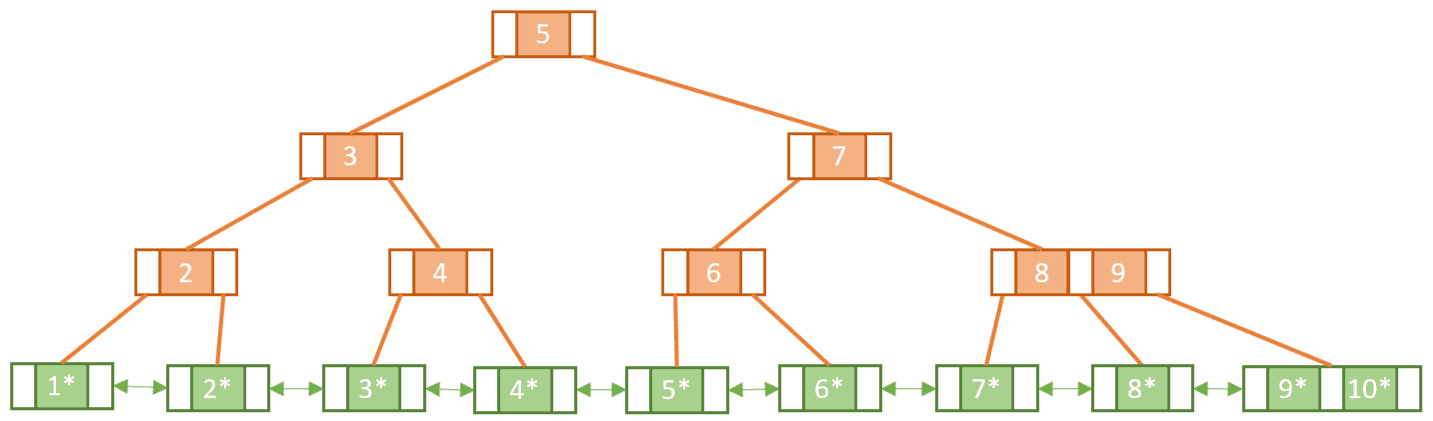
Let’s see how our B-tree would look like if we were to represent its content as a B+tree:
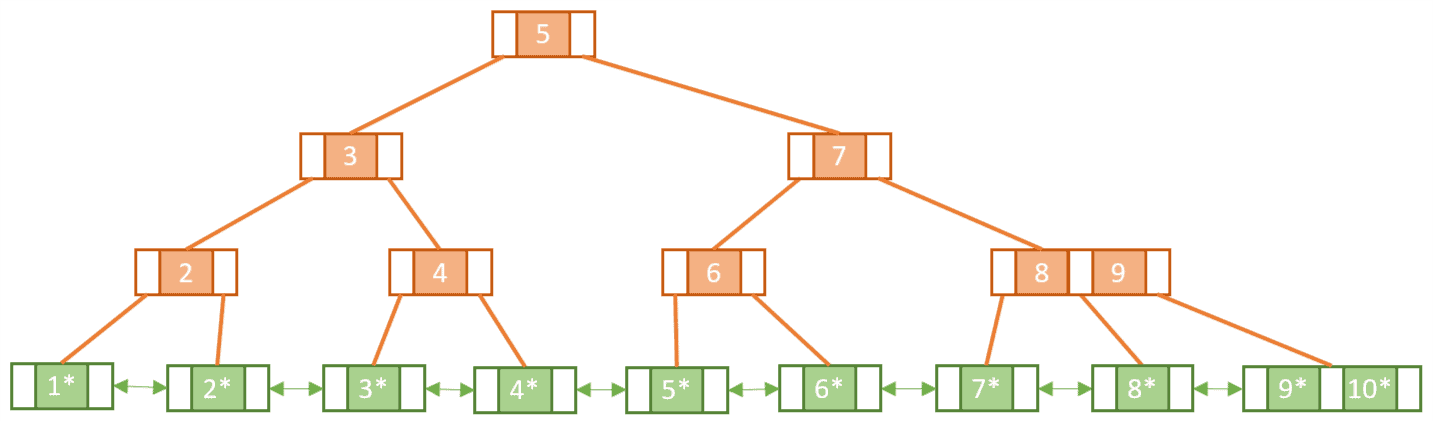
Notice that some keys seem to be duplicated, like 2, 4, and 5. This is because, unlike leaf nodes, the internal nodes of a B+tree cannot hold satellite data and so we must make sure in some way that the leaf nodes include all the keys/value pairs.
Let’s build up our tree from scratch and see how this happens.

When we come to insert Key 3, we find that in doing so we will exceed the capacity of the root node.
Similar to a normal B-tree this means we need to perform a split operation. However, unlike with the B-tree, we must copy-up the first key in the new rightmost leaf node. As mentioned, this is so we can make sure we have a key/value pair for Key 2 in the leaf nodes:
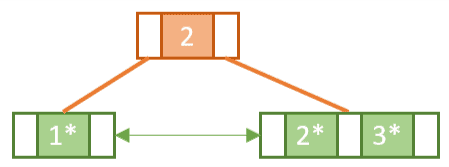
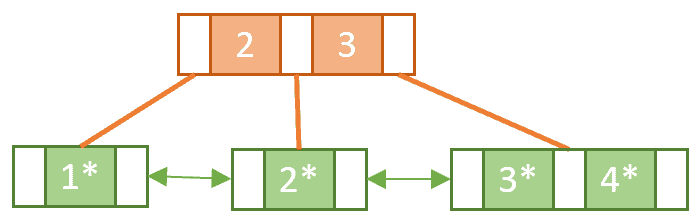
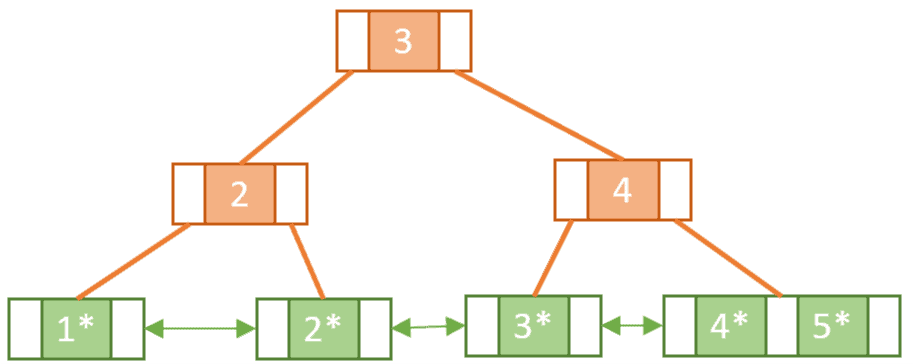
Notice the difference between splitting a leaf node and splitting an internal node. When we split the internal node in the second split operation we didn’t copy-up Key 3.
In the same way, we keep adding the keys from 6 to 10, each time splitting and copying-up when necessary until we have reached our final tree:
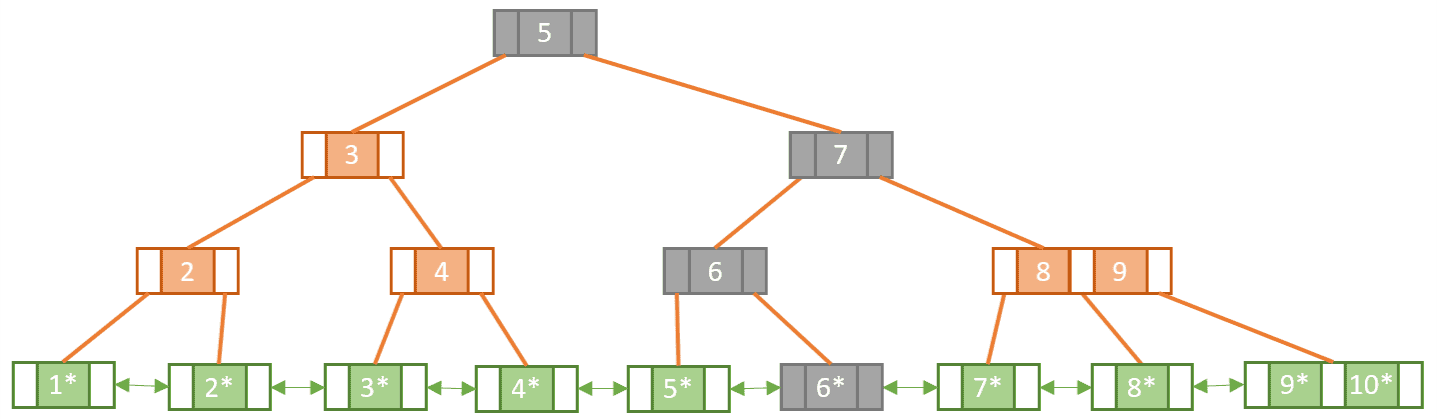
The shaded nodes show us the path we have taken in order to find our match. Deduction tells us that searching within a B+tree means that we must go all the way down to a leaf node to get the satellite data. As opposed to B-trees where we could find the data at any level.
In addition to exact key match queries, B+trees support range queries. This is enabled by the fact that the B+tree leaf nodes are all linked together. To perform a range query all we need to do is:
Storing and managing data is a fundamental part of computing. Main memory is considered to be a primary data storage, but we cannot store everything in it because it’s volatile and also expensive. That’s why we have secondary storage that’s less expensive and not volatile. Secondary storage is typically stored on magnetic disks in units called pages.
Transferring elements from disk to memory requires a read from the disk. A single disk read performs full-page access even if we are only trying to read one element from that page. Disk reads aren’t as fast as main memory reads since each time we do a read there it’s a seek and a rotational delay. The more disk accesses we need, the longer the search operation will take.
DBMSs leverage the logarithmic efficiency of B-tree indexing to reduce the number of reads required to find a particular record. B-trees are typically constructed so that each node takes up a single page in memory and they are designed to reduce the number of accesses by requiring that each node be at least half full.
Let’s cover the most obvious points of comparison between B-trees and B+trees:
Finally, although B-trees are useful, B+trees are more popular. In fact, 99% of database management systems use B+trees for indexing.
This is because the B+tree holds no data in the internal nodes. This maximizes the number of keys stored in a node thereby minimizing the number of levels needed in a tree. Smaller tree depth invariably means faster search.
In this article, we took a close look at both B-trees and B+trees. We learned how they are built and how to search for a certain key.
Finally, with the information we learned, we were able to compare between the two in terms of structure, usage, and popularity.