Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 17, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll cover the Ternary Search Tree (TST) data structure. It’s a very interesting data structure that can solve the problem of fast string lookup.
Let’s assume we have a set of strings  . Without losing generality, we’ll assume the strings in
. Without losing generality, we’ll assume the strings in  are lexicographically sorted. The lexicographical order will simplify our discussion. We’ll also treat the strings as 1-indexed sequences of symbols.
are lexicographically sorted. The lexicographical order will simplify our discussion. We’ll also treat the strings as 1-indexed sequences of symbols.
For our complexity estimations, let’s denote:
by  . by
. by  .
. .
.We’ll use the previously established sets and notations in the following sections of this tutorial.
TST has been employed as an efficient solution for frequent string lookups in a set of strings. It offers the space efficiency of BST while providing the lightning-fast performance of Trie for searching strings.
TST is similar to Trie in terms of its structure – it splits string symbols and creates a tree out of them. Similarly to Trie and BST, TST consists of nodes, and each node contains:
 – a single symbol/occurrence in a string.
– a single symbol/occurrence in a string. – a reference to the left child node; the value in the left node is less than the value in the parent node.
– a reference to the left child node; the value in the left node is less than the value in the parent node. – a reference to the right child node; the value in the right node is greater than the value in the parent node.
– a reference to the right child node; the value in the right node is greater than the value in the parent node. – a reference to the middle child node; the value in the middle node is the next symbol in a string which contains the value in the parent node followed by the value in the middle node.
– a reference to the middle child node; the value in the middle node is the next symbol in a string which contains the value in the parent node followed by the value in the middle node. – a flag indicating whether the node is terminal, i.e., there’s a string in ending in the node.
– a flag indicating whether the node is terminal, i.e., there’s a string in ending in the node.Each node in TST has up to 3 children, hence the data structure’s name. The figure next depicts a TST structure constructed out of the strings in . In this case, blue nodes are terminating ones. The terminating nodes mark the end of a word in . Red edges are middle children’s references. Seeing a red edge means at least one string in  containing
containing  followed by
followed by  :
:
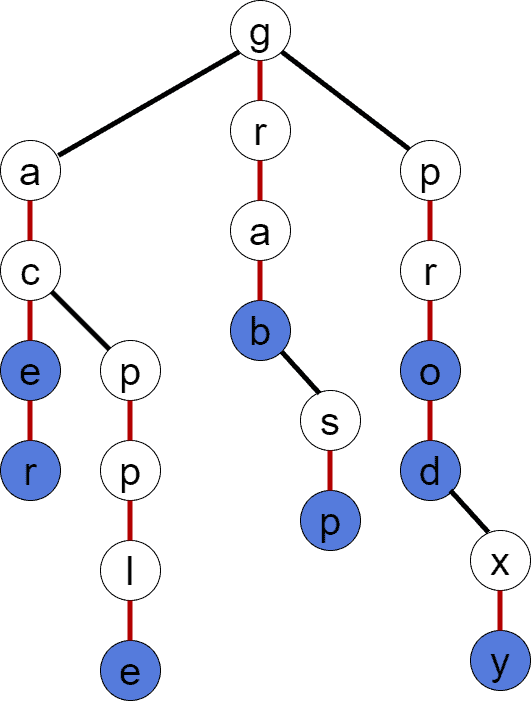
Similarly to BST, the performance of TST is strictly dependent on the tree depth. The lookup performance of TST is  , assuming TST is balanced. The estimation is derived from the fact that each symbol lookup – with a positive or negative result – may take up to
, assuming TST is balanced. The estimation is derived from the fact that each symbol lookup – with a positive or negative result – may take up to  time. Practically, the multiplier is much less than
time. Practically, the multiplier is much less than  , as not all symbols are present at each level of the tree.
, as not all symbols are present at each level of the tree.
Overall space usage depends on the number of nodes in TST. The number of nodes, in turn, relies on the number of strings in that share common prefixes. Thus, in the worst case with minimum prefix sharing, the space complexity is  .
.
In this section, we’ll go over the general TST operations. Note that there’s no string removal operation, as it’s not common for TST. The strings are generally added to the structure without removal afterward.
The insertion operation is a bit subtle. It needs to handle the following:
For simplicity, let’s see the implementation of an auxiliary node creation operation. We’ll assume there’s a data type TSTNode =  :
:
algorithm CREATE_NODE(val):
// INPUT
// val = the value to be stored in the new node
// OUTPUT
// Returns a new TST node holding val, initialized with default values
// for the remaining fields.
node <- new TSTNode
node.value <- val
node.leftChild <- NULL
node.middleChild <- NULL
node.rightChild <- NULL
node.isTerminal <- FALSE
return nodeAnd we have a recursive version of the insertion operation next:
algorithm INSERT(node, str, pos):
// INPUT
// node = a node in the TST
// str = the string to insert
// pos = the position of the current symbol in the string to insert
// OUTPUT
// the string str is added to the TST
if pos = str.length + 1:
return node
if node = NULL:
node <- CREATE-NODE(str[pos])
if str[pos] < node.value:
node.leftChild <- Insert(node.leftChild, str, pos)
else if str[pos] > node.value:
node.rightChild <- Insert(node.rightChild, str, pos)
else:
if pos = str.length:
node.isTerminal <- TRUE
else:
node.middleChild <- Insert(node.middleChild, str, pos + 1)
return nodeThe intuition behind insertion is that we need to insert the current symbol if we’re in a NULL node. The recursion then takes care of assigning the newly created node to the appropriate child of the parent node when the call returns. If we have a match at a node, then there’s no need to create a node for the current symbol, and we need to consider the next symbol of the string and follow the middle subtree. Additionally, if there’s a match and it’s the last symbol of the string, we mark the node as terminal. Contrarily, if there’s no match at a node, insertion continues in either the left or the right subtree with the current symbol.
TST creation is actually a series of insertion operations. As in the case of BST, we have the worst-performing TST when inserting strings in sorted order.
There’re two cardinally different cases to consider when building TST:
is known beforehand, i.e., the offline mode. To have a well-balanced TST, consider inserting strings randomly. Another option is to sort the strings in , insert the middle string, and then continue insertions recursively in the left and right subsets of . Note that these approaches are directly derived from BST. is dynamic, i.e., the online mode. In this case, we should use balancing techniques to keep a good TST performance.Of course, we can always add balancing logic to our TST to guarantee performance.
Let’s write the pseudocode for the build operation in case of the offline mode. We’ll employ the version of random string insertion. To achieve randomness, we first shuffle the strings in and then insert them in order:
algorithm TST_BUILD(S):
// INPUT
// S = the set of strings
// OUTPUT
// The TST is constructed and its root node is returned
rootNode <- NULL
Shuffle S
for s in S:
rootNode <- INSERT(rootNode, s, 1)
return rootNodeWe have the pseudocode for a recursive string lookup in TST shown below:
algorithm TST_SEARCH(node, str, pos):
// INPUT
// node = a node in the TST
// str = the string to look up
// pos = the position of the current symbol in the string to look up
// OUTPUT
// Returns TRUE if str is found, FALSE otherwise
if node = NULL:
return FALSE
if str[pos] < node.value:
return TST_SEARCH(node.leftChild, str, pos)
if str[pos] > node.value:
return TST_SEARCH(node.rightChild, str, pos)
if pos = str.length and node.isTerminal:
return TRUE
return StringSearch(node.middleChild, str, pos + 1)Initially, the function is invoked on the TST’s root node to look up the string’s first symbol: INSERT( ). So, the first condition indicates the case when the string isn’t found. It’s reached when there’re still symbols in the string to search for, but there’s no way to go in the TST.
). So, the first condition indicates the case when the string isn’t found. It’s reached when there’re still symbols in the string to search for, but there’s no way to go in the TST.
The following two conditions are for the cases when there’s no match in the current node, and we need to continue the search in either the left or the right subtree. Finally, the remaining part of the function handles the match and indicates if the search has finished or if we need to continue the search in the middle subtree.
There’re a lot of practical applications of TST. It may be used anywhere Trie is used. Thus, let’s see some typical applications of TST:
This section will discuss alternative data structures used in string lookup. Indeed, there are several of them, and each has its own peculiarities.
In the following figure, we can see a possible balanced BST constructed from :
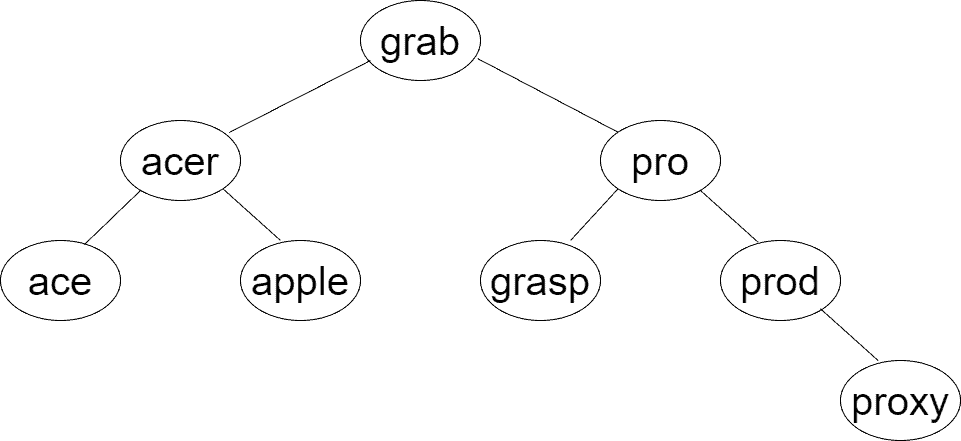
A balanced BST offers  performance during a general lookup. However, when keys are of the string type, there’s an additional complexity multiplier. The overall complexity for a string lookup is
performance during a general lookup. However, when keys are of the string type, there’s an additional complexity multiplier. The overall complexity for a string lookup is  because every single key comparison is an
because every single key comparison is an  string comparison.
string comparison.
Consider the lookup of  . After comparing the first characters of
. After comparing the first characters of  and , the search goes to the right branch. Now,
and , the search goes to the right branch. Now,  is fully compared to symbol by symbol until there’s no match, and we need to go right.
is fully compared to symbol by symbol until there’s no match, and we need to go right.
The same brute-force comparison is made when comparing to  . And finally, we find in the rightmost node of the tree. The evident drawback of BST for searching strings is redundant comparisons of common prefixes. We need a faster way to skip the current key and move forward.
. And finally, we find in the rightmost node of the tree. The evident drawback of BST for searching strings is redundant comparisons of common prefixes. We need a faster way to skip the current key and move forward.
Furthermore, the space usage of BST is .
Trie is the best data structure for string lookup in terms of speed. But, it uses a lot of redundant space and isn’t always applicable. Below, we can see the Trie for ; the terminating nodes are colored in blue. Note that for image simplicity, we haven’t visualized the redundant references kept at each node:
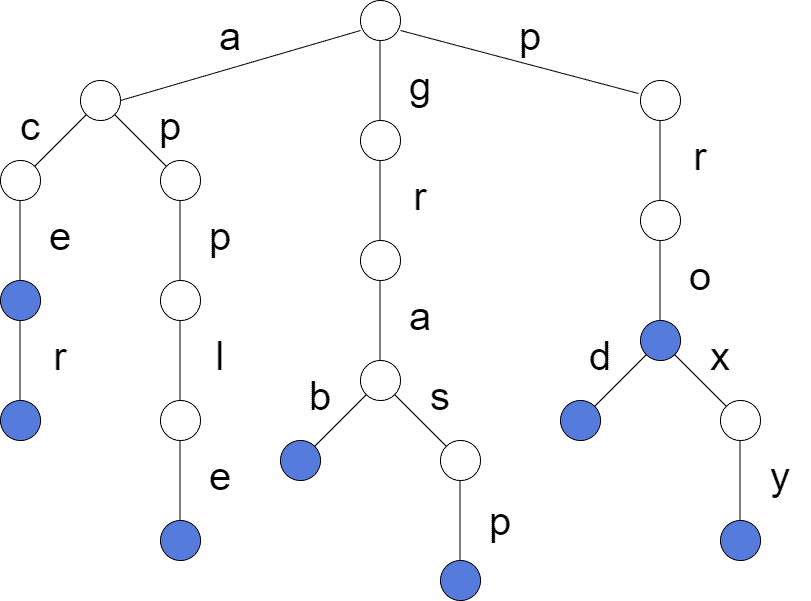
The specifics of the Trie structure allow us to look up a string in  time. Tries are fast because each node keeps the (random-access) array of references to indicate which symbols branch out from a node. So, it’s possible to tell in
time. Tries are fast because each node keeps the (random-access) array of references to indicate which symbols branch out from a node. So, it’s possible to tell in  time if the search needs to continue for any symbol of the search string at any node in Trie. Since there are symbols in a string, the lookup works in .
time if the search needs to continue for any symbol of the search string at any node in Trie. Since there are symbols in a string, the lookup works in .
However, the space requirement is huge – each node takes  space. For example, if our alphabet consists of uppercase and lowercase English letters, each node keeps 52 references. So, most of the time, we have lots of redundant references. Furthermore, the overall space usage, as in the case of TST, depends on the number of nodes in Trie. In the worst case with minimum prefix sharing, the space complexity goes up to
space. For example, if our alphabet consists of uppercase and lowercase English letters, each node keeps 52 references. So, most of the time, we have lots of redundant references. Furthermore, the overall space usage, as in the case of TST, depends on the number of nodes in Trie. In the worst case with minimum prefix sharing, the space complexity goes up to  .
.
Hash tables are known as the best general lookup data structure. Below is the hash table for , with 4 slots and the hash function ![h(s) = (\Sigma_{i=0}^{length(s) - 1} s[i] * 31^i)mod 4, s \in S](/wp-content/ql-cache/quicklatex.com-c01e811f49581d8f1ac75a1bba6b248d_l3.svg "Rendered by QuickLaTeX.com") :
:
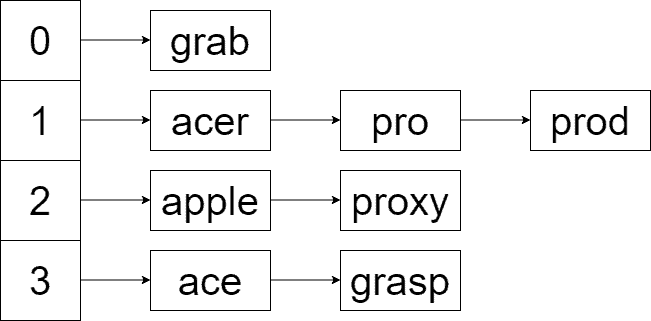
Hash tables offer amortized lookup by generally assuming the use of an hash function. When storing strings, there’s usually a multiplier for computing the hash value. Similarly to the BST case, there’s a multiplier for comparing a constant number of strings in the slot to find the searched string.
So, the lookup runs in amortized  time. Moreover, space usage is
time. Moreover, space usage is  , where , in such a case, is the number of slots in the hash table.
, where , in such a case, is the number of slots in the hash table.
Additionally, hash tables keep the data unordered. Contrarily, the rest of the discussed data structures are ordered. Thus, a hash table isn’t an option for applications where ordering matters, despite the good practical performance.
In this tutorial, we studied the TST data structure. Initially, the main concepts regarding TST were presented. Thus, we discussed the TST operations and provided pseudocodes for them. Then, we enumerated practical applications of this data structure. Finally, we discussed some alternative data structures for string lookup.