

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll talk about tabulation and memoization as two techniques of dynamic programming.
Dynamic Programming (DP) is an optimization paradigm that finds the optimal solution to the initial problem by solving its sub-problems and combining their solutions, usually in polynomial time. In doing so, DP makes use of Bellman’s Principle of Optimality, which we state as follows:
A sub-solution of the entire problem’s optimal solution is the optimal solution to the corresponding sub-problem.
So, DP first divides the problem so that the optimal solution of the whole problem is a combination of the optimal solutions to its sub-problems. But, the same applies to the sub-problems: their optimal solutions are also combinations of their sub-problems’ optimal solutions. This division continues until we reach base cases.
Therefore, each problem we solve using DP has a recursive structure that respects Bellman’s Principle. We can solve the problem by traversing the problem’s structure top-down or bottom-up.
Tabulation is a bottom-up method for solving DP problems. It starts from the base cases and finds the optimal solutions to the problems whose immediate sub-problems are the base cases. Then, it goes one level up and combines the solutions it previously obtained to construct the optimal solutions to more complex problems.
Eventually, tabulation combines the solutions of the original problem’s subproblems and finds its optimal solution.
Let’s say that we have a  grid. The cell
grid. The cell  contains
contains  coins (
coins ( ). Our task is to find the maximal amount of coins we can collect by traversing a path from the cell
). Our task is to find the maximal amount of coins we can collect by traversing a path from the cell  to the cell
to the cell  . In moving across the board, we can move from a cell to its right or bottom neighbor. We consider collected once we reach the cell
. In moving across the board, we can move from a cell to its right or bottom neighbor. We consider collected once we reach the cell  .
.
Here’s an example of a  grid, with the optimal path highlighted:
grid, with the optimal path highlighted:
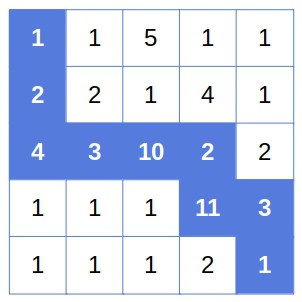
Let’s suppose that  is the optimal path from to and that it goes through cell . Then, the part of from to ,
is the optimal path from to and that it goes through cell . Then, the part of from to ,  represents the optimal path between the two cells. If it wasn’t so, then there would be a better path
represents the optimal path between the two cells. If it wasn’t so, then there would be a better path  from to . Consequently, wouldn’t be the optimal path to because the concatenation of
from to . Consequently, wouldn’t be the optimal path to because the concatenation of  and
and  would be better, and that would be a contradiction.
would be better, and that would be a contradiction.
Now, let’s say that we’ve determined the optimal path to and its total yield ![Y[t, n]](/wp-content/ql-cache/quicklatex.com-7c707a4c612f7b94fc7abace6a810e27_l3.svg "Rendered by QuickLaTeX.com") . Based on the previous analysis and the problem definition, we conclude that must pass through
. Based on the previous analysis and the problem definition, we conclude that must pass through  or
or  . So, the recursive definition of
. So, the recursive definition of ![Y[n, n]](/wp-content/ql-cache/quicklatex.com-228de4212d4ca1265aad63acd5b25102_l3.svg "Rendered by QuickLaTeX.com") is:
is:
![\[Y[n, n] = c_{n,n} + \max\{Y[n, n-1], Y[n-1, n] \}\]](/wp-content/ql-cache/quicklatex.com-3766ac2c0cdd39d850517ef81028bf59_l3.svg "Rendered by QuickLaTeX.com")
However, what holds for , also holds for any ![Y[i, j]](/wp-content/ql-cache/quicklatex.com-e0db4c482df3d4ea33b887c19eda1aa9_l3.svg "Rendered by QuickLaTeX.com") . When we account for the base cases, we get the recursive definition of :
. When we account for the base cases, we get the recursive definition of :
(1) ![\begin{equation*} Y[i, j] = \begin{cases} c_{1, 1}, & i=1 \text{ and } j=1\\ c_{1, j} + Y[1, j-1], & i=1 \text{ and } j > 1\\ c_{i,1} + Y[i-1, 1], & i>1 \text{ and } j=1\\ c_{i,j} + \max\{ Y[i-1, j], Y[i, j-1]\},& \text{otherwise} \\ \end{cases} \end{equation*}](/wp-content/ql-cache/quicklatex.com-4b5af8d02515ea28578043f1394f4d42_l3.svg "Rendered by QuickLaTeX.com")
To reconstruct the path, we can use an auxiliary matrix  where
where ![T[i, j]=R](/wp-content/ql-cache/quicklatex.com-f545b3a9d1ad5e660ca919272dea36a3_l3.svg "Rendered by QuickLaTeX.com") if the optimal path reaches from the left (i.e., by moving one cell right from the predecessor cell), and
if the optimal path reaches from the left (i.e., by moving one cell right from the predecessor cell), and ![T[i,j] = D](/wp-content/ql-cache/quicklatex.com-87513dcdf0ff0df01ec0635bf417ef9f_l3.svg "Rendered by QuickLaTeX.com") if it does so by moving one cell down. However, to keep things simple(r), we’ll omit path tracing and focus only on computing
if it does so by moving one cell down. However, to keep things simple(r), we’ll omit path tracing and focus only on computing  .
.
Now, we reverse the direction of the recursion. We start from the base case ![Y[1, 1]](/wp-content/ql-cache/quicklatex.com-2e5b662e77d1704b03574d7fc1b33da7_l3.svg "Rendered by QuickLaTeX.com") . From there, we find the yields of the paths to the cells in the
. From there, we find the yields of the paths to the cells in the  st column and the first row. Then, we compute the values for the second column and row, and so on:
st column and the first row. Then, we compute the values for the second column and row, and so on:
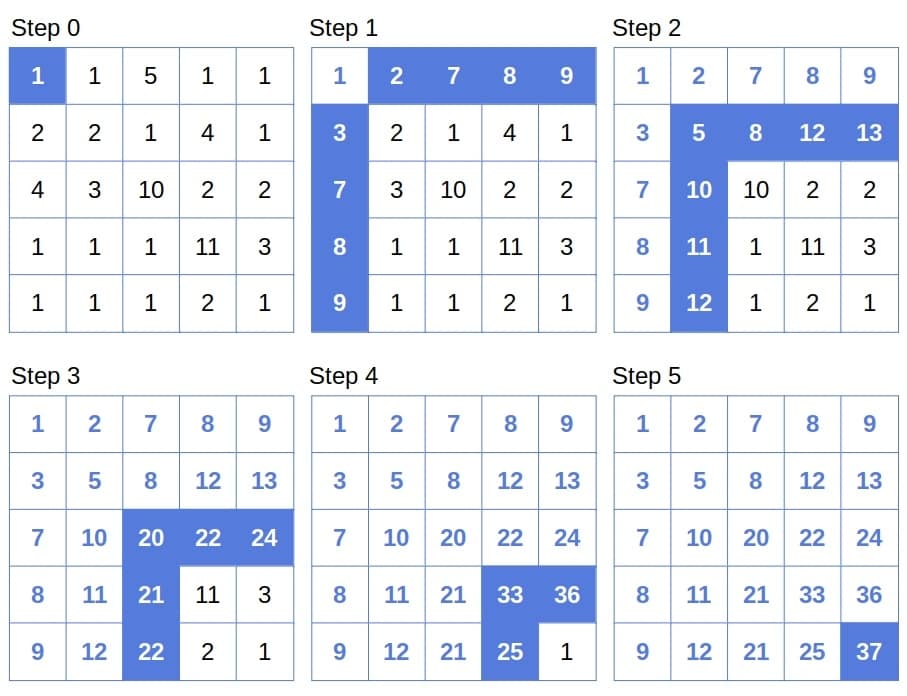
Processing the  -shaped stripes one by one, we get our tabulation algorithm:
-shaped stripes one by one, we get our tabulation algorithm:
algorithm TabulationAlgorithmForCollectingCoins(c, n):
// INPUT
// c = a square matrix such that c[i, j] is the number of coins in the cell (i, j)
// n = the order of the matrix
// OUTPUT
// The maximal number of coins we can collect on a path from (1,1) to (n,n)
Y <- an empty n x n matrix
// Cover the base case
Y[1, 1] <- c[1, 1]
// Compute Y for the first row and the first column
for j <- 2, 3, ..., n:
Y[1, j] <- Y[1, j - 1] + c[1, j]
for i <- 2, 3, ..., n:
Y[i, 1] <- Y[i - 1, 1] + c[i, 1]
// Now, compute one Γ-shaped layer at a time
for k <- 2, 3, ..., n:
for i <- k, k + 1, ..., n:
Y[i, k] <- c[i, k] + max{Y[i - 1, k], Y[i, k - 1]}
// We start from k + 1 because we covered (k, k) in the i-loop
for j <- k + 1, k + 2, ..., n:
Y[k, j] <- c[k, j] + max{Y[k, j - 1], Y[k - 1, j]}
return Y[n, n]This algorithm’s time and space complexities are  .
.
Tabulation algorithms are usually very efficient. Most of the time, they’ll have polynomial complexity. And, since they’re iterative, they don’t risk throwing the stack overflow error. However, there are certain drawbacks.
First, we invest a lot of effort into identifying the problem’s recursive structure to get the recurrence right. However, the tabulation algorithms aren’t recursive. What’s more, they solve the problems in the reverse direction: from the base cases to the original problem. That’s the first drawback of tabulation. It may be hard to get the tabulation algorithm from a recursive formula.
Also, recursive relations such as (1) are natural descriptions of the problems to solve. So, they’re easier to understand than an iterative algorithm in which the recursive structure of the problem isn’t as apparent.
Finally, systematic in constructing more complex problems from the simpler ones, tabulation algorithms may compute the solutions to the sub-problems that aren’t necessary to solve the original problem.
Is there a way to have the efficiency of tabulation and keep the elegance and understandability of recursion? Yes, there is, and it’s called memoization.
The idea behind it is as follows. First, we write the recursive algorithm as usual. Then, we enrich it with a memory structure where we store the solutions to the sub-problems we solve. If we reencounter the same sub-problem during the execution of the recursive algorithm, we don’t re-calculate its solution. Instead, we read it from memory.
This way, we avoid repeated computation and reduce the time complexity to the number of different sub-problems. We do so at the expense of the space complexity but don’t use more memory than the corresponding tabulation algorithm.
Here’s the memoization algorithm for the grid problem:
algorithm MemoizationCollectingCoins(i, j, c, n, Y):
// INPUT
// i = the row index of the current cell
// j = the column index of the current cell
// c = the matrix where c[i, j] is the number of coins in the cell (i, j)
// n = the order of the matrix
// Y = a memory structure for storing the results
// OUTPUT
// The maximal number of coins we can collect on a path from (1, 1) to (i, j)
if Y[i, j] has been calculated:
return Y[i, j]
// Cover the base case
if i = 1 and j = 1:
Y[1,1] <- c[1,1]
return Y[1, 1]
// Implement the recursive steps
if i = 1 and j > 1:
Y[i, j] <- c[1, j] + MemoizationCollectingCoins(1, j - 1, c, n, Y)
else if i > 1 and j = 1:
Y[i, j] <- c[i, 1] + MemoizationCollectingCoins(i - 1, 1, c, n, Y)
else:
Y[i, j] <- c[i, j] + max(MemoizationCollectingCoins(i - 1, j, c, n, Y),
MemoizationCollectingCoins(i, j - 1, c, n, Y))
return Y[i, j]This algorithm’s time and space complexities are .
Let’s draw the first three levels of the memoization’s recursion tree:
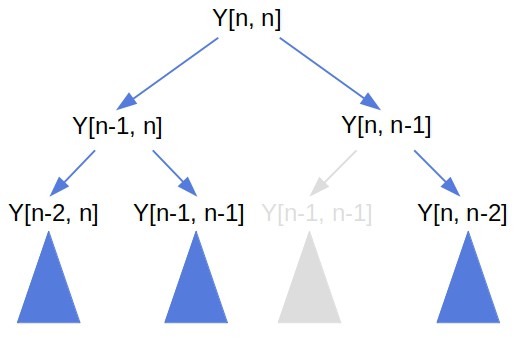
The algorithm calculates the value ![Y[n-1, n-1]](/wp-content/ql-cache/quicklatex.com-ba52873986cd927f2f31477edac01657_l3.svg "Rendered by QuickLaTeX.com") while computing
while computing ![Y[n, n-1]](/wp-content/ql-cache/quicklatex.com-9fd636b2a20b171c37c86b3e43a8ac61_l3.svg "Rendered by QuickLaTeX.com") in the root’s left sub-tree. Later, when it calculates
in the root’s left sub-tree. Later, when it calculates ![Y[n-1, n]](/wp-content/ql-cache/quicklatex.com-c7346cf47d17b3c3afe4d1ffa6bf4fd9_l3.svg "Rendered by QuickLaTeX.com") in the right sub-tree, it doesn’t have to compute from scratch. Instead, it reuses the readily available value in the memory.
in the right sub-tree, it doesn’t have to compute from scratch. Instead, it reuses the readily available value in the memory.
So, we see that memoization effectively prunes the execution tree.
Even though it’s intuitive and efficient, memoization sometimes isn’t an option. The problem is that it can cause the stack overflow error. That will be the case if the input size is too big. Iterative, the memoization algorithms don’t suffer from the same issue.
A more subtle but still relevant issue is related to the memory we use to store the results. For memoization to work, we need an  -access memory structure. Hash maps, especially with double hashing, offer the constant worst-case access time. However, they require a hash function for the (sub-)problems. In the coin example, it’s easy to devise a quality hash. However, the problems may be complex, so a hash could be very hard to design.
-access memory structure. Hash maps, especially with double hashing, offer the constant worst-case access time. However, they require a hash function for the (sub-)problems. In the coin example, it’s easy to devise a quality hash. However, the problems may be complex, so a hash could be very hard to design.
Finally, some authors don’t consider memoization a DP tool, whereas others do. That isn’t a drawback by itself but is worth keeping in mind.
In this article, we talked about tabulation and memoization. Those are the bottom-up and top-down approaches of dynamic programming (DP). Although there’s no consensus about the latter being a DP technique, we can use both methods to obtain efficient algorithms.
While the memoization algorithms are easier to understand and implement, they can cause the stack overflow (SO) error. The tabulation algorithms are iterative, so they don’t throw the SO error but are generally harder to design.