

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this article, we’ll discuss the problem of finding all the simple paths between two arbitrary vertices in a graph.
We’ll start with the definition of the problem. Then, we’ll go through the algorithm that solves this problem.
Finally, we’ll discuss some special cases. We’ll focus on directed graphs and then see that the algorithm is the same for undirected graphs.
Let’s first remember the definition of a simple path. Suppose we have a directed graph  , where
, where  is the set of vertices and
is the set of vertices and  is the set of edges. A simple path between two vertices
is the set of edges. A simple path between two vertices  and
and 
 is a sequence of vertices
is a sequence of vertices  that satisfies the following conditions:
that satisfies the following conditions:
 where
where  belong to the set of vertices
belong to the set of vertices  ,
, 
 , where
, where  , there is an edge
, there is an edge  that belongs to the set of edges
that belongs to the set of edges The problem gives us a graph and two nodes, and , and asks us to find all possible simple paths between two nodes and .
The graph can be either directed or undirected. We’ll start with directed graphs, and then move to show some special cases that are related to undirected graphs.
For example, let’s consider the graph:
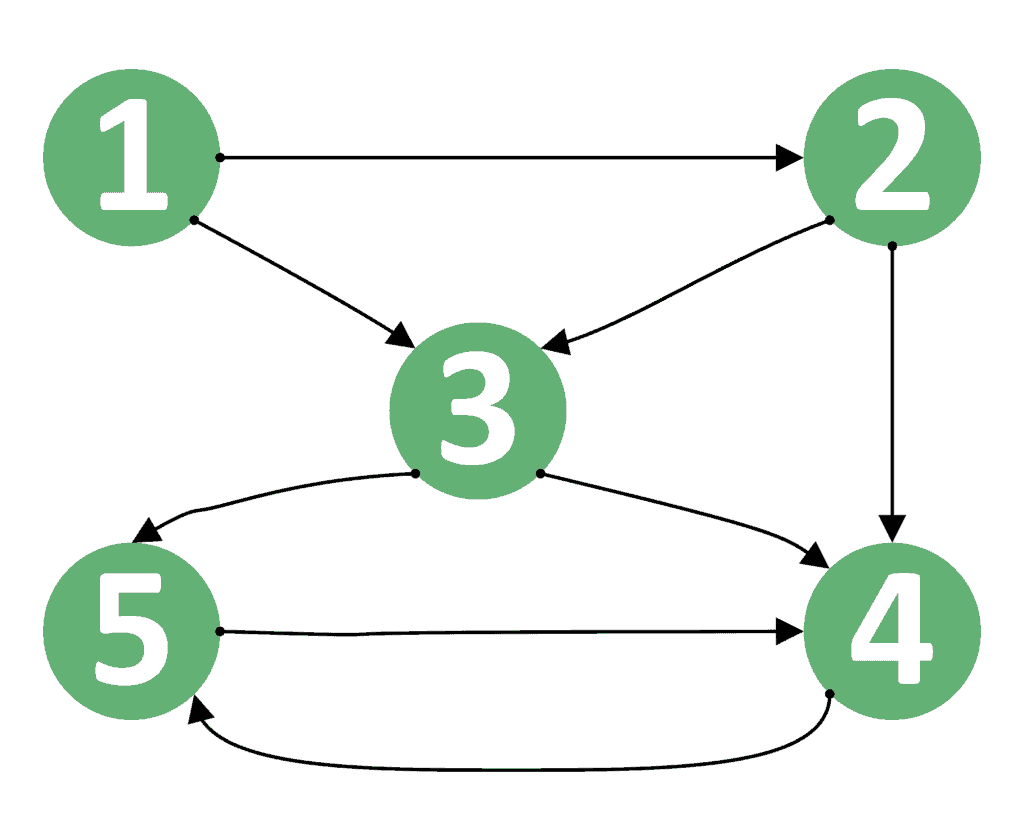
As we can see, there are 5 simple paths between vertices 1 and 4:





Note that the path  is not simple because it contains a cycle — vertex 4 appears two times in the sequence.
is not simple because it contains a cycle — vertex 4 appears two times in the sequence.
The basic idea is to generate all possible solutions using the Depth-First-Search (DFS) algorithm and Backtracking.
In the beginning, we start the DFS operation from the source vertex . Then, we try to go through all its neighbors. For each neighbor, we try to go through all its neighbors, and so on.
Hopefully, we’ll be able to reach the destination vertex . When this happens, we add the walked path to our set of valid simple paths. Then, we go back to search for other paths.
In order to avoid cycles, we must prevent any vertex from being visited more than once in the simple path. To do that, we mark every vertex as visited when we enter it for the first time in the path. Hence, when we try to visit an already visited vertex, we’ll go back immediately.
After processing some vertex, we should remove it from the current path, so we mark it as unvisited before we go back. The reason for this step is that the same node can be a part of multiple different paths. However, it can’t be a part of the same path more than once.
Let’s take a look at the implementation of the idea we’ve just described:
algorithm findAllSimplePaths(G, u, v):
// INPUT
// G = The graph stored in an adjacency list
// u = The starting node
// v = The ending node
// OUTPUT
// Returns a list of all simple paths from u to v
visited <- array of false for each node in G
currentPath <- empty list
simplePaths <- empty list
DFS(u, v, visited)
return simplePaths
function DFS(u, v, visited):
if visited[u] = true:
return
visited[u] <- true
currentPath.addToBack(u)
if u = v:
simplePaths.add(currentPath)
visited[u] <- false
currentPath.removeFromBack()
return
for next in G[u]:
DFS(next, v, visited)
currentPath.removeFromBack()
visited[u] <- falseFirst of all, we initialize the  array with
array with  values, indicating that no nodes have been visited yet. Also, we initialize the
values, indicating that no nodes have been visited yet. Also, we initialize the  and
and  lists to be empty. The list will store the current path, whereas the list will store the resulting paths.
lists to be empty. The list will store the current path, whereas the list will store the resulting paths.
After that, we call the DFS function and then return the resulting simple paths. Let’s check the implementation of the DFS function.
First, we check whether the vertex has been visited or not. If so, then we go back because we reached a cycle. Otherwise, we add to the end of the current path using the  function and mark node as visited.
function and mark node as visited.
Second, we check if vertex is equal to the destination vertex . If so, then we’ve reached a complete valid simple path. Therefore, we add this path to our result list and go back.
However, if we haven’t reached the destination node yet, then we try to continue the path recursively for each neighbor of the current vertex.
Finally, we remove the current node from the current path using a  function that removes the value stored at the end of the list (remember that we added the current node to the end of the list). Also, we mark the node as unvisited to allow it to be repeated in other simple paths.
function that removes the value stored at the end of the list (remember that we added the current node to the end of the list). Also, we mark the node as unvisited to allow it to be repeated in other simple paths.
We’ll consider the worst-case scenario, where the graph is complete, meaning there’s an edge between every pair of vertices. In this case, it turns out the problem is likely to find a permutation of vertices to visit them.
For each permutation of vertices, there is a corresponding path. Hence, the complexity is  , where
, where  is the number of vertices and
is the number of vertices and  is the factorial of the number of vertices.
is the factorial of the number of vertices.
This complexity is enormous, of course, but this shouldn’t be surprising because we’re using a backtracking approach.
The previous algorithm works perfectly fine for both directed and undirected graphs. The reason is that any undirected graph can be transformed to its equivalent directed graph by replacing each undirected edge  with two directed edges
with two directed edges  and
and  .
.
However, in undirected graphs, there’s a special case where the graph forms a tree. We’ll discuss this case separately.
Remember that a tree is an undirected, connected graph with no cycles.
In this case, there is exactly one simple path between any pair of nodes inside the tree. Specifically, this path goes through the lowest common ancestor (LCA) of the two nodes. In other words, the path starts from node , keeps going up to the LCA between and , and then goes to .
For example, let’s take the tree shown below:
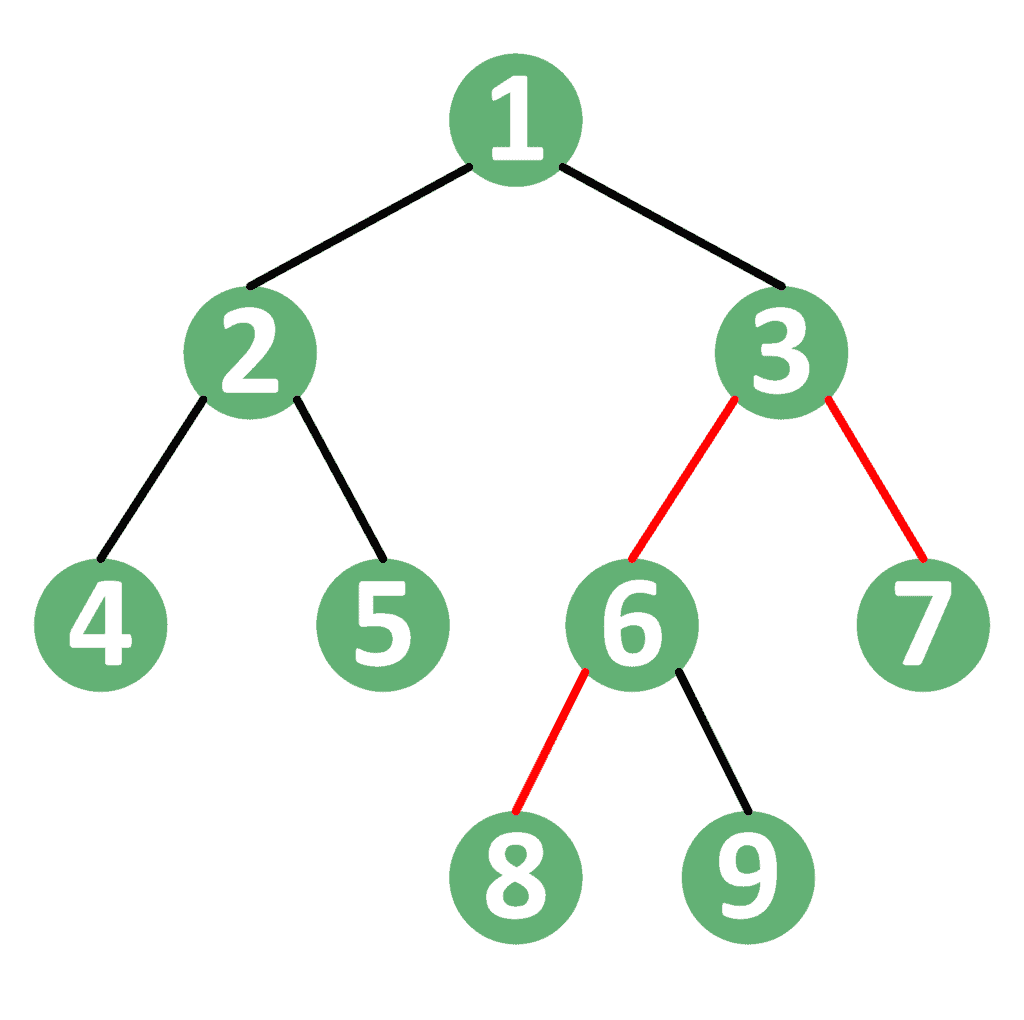
In this tree, the simple path between nodes 7 and 8 goes through their LCA, which is node 3. Similarly, the path between nodes 4 and 9 goes through their LCA, which is node 1.
In the general case, undirected graphs that don’t have cycles aren’t always connected. If the graph is disconnected, it’s called a forest. A forest is a set of components, where each component forms a tree itself.
When dealing with forests, we have two potential scenarios. For one, both nodes may be in the same component, in which case there’s a single simple path. The reason is that both nodes are inside the same tree.
On the other hand, if each node is in a different tree, then there’s no simple path between them. This is because each node is in a different disconnected component.
For example, take a look at the forest below:
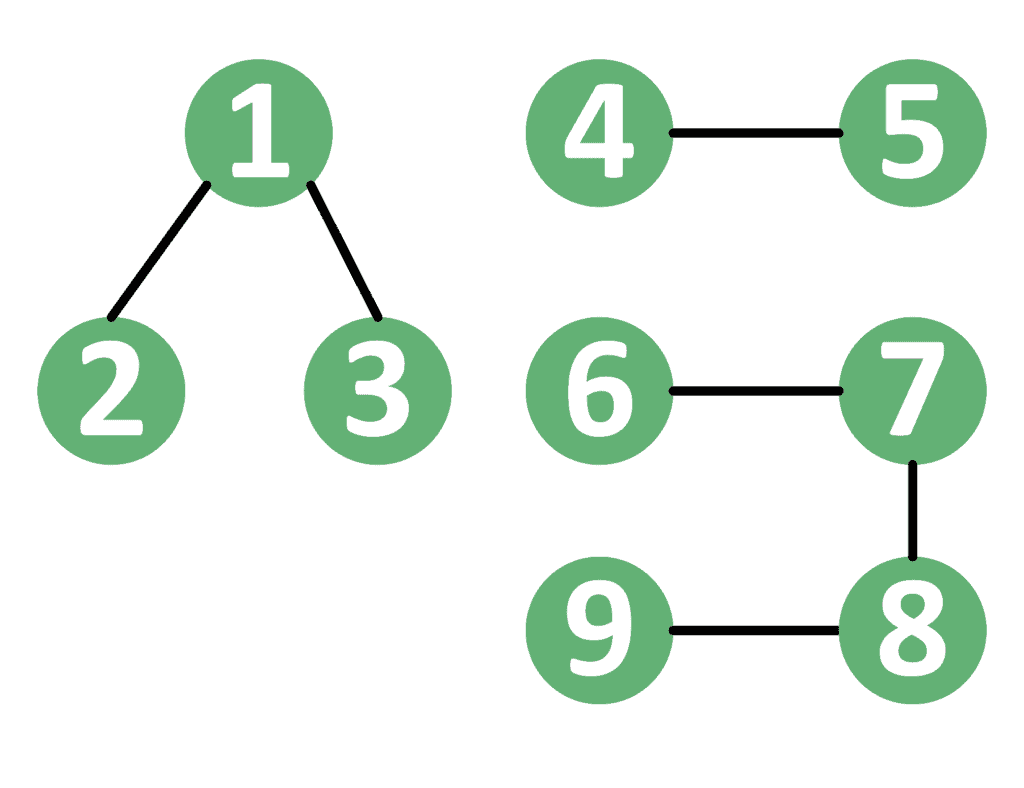
In this graph, there’s a simple path between nodes 2 and 3 because both are in the same tree containing nodes { }. However, there isn’t any simple path between nodes 5 and 8 because they reside in different trees.
}. However, there isn’t any simple path between nodes 5 and 8 because they reside in different trees.
In this tutorial, we’ve discussed the problem of finding all simple paths between two nodes in a graph.
In the beginning, we started with an example and explained the solution to it. After that, we presented the algorithm along with its theoretical idea and implementation.
Finally, we explained a few special cases that are related to undirected graphs.