

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: June 29, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this article, we’ll discuss the Lowest Common Ancestors problem. We’ll start with the basic definition, then go through some of the methods used to find the lowest common ancestor of two nodes in a rooted tree.
The Lowest Common Ancestor (LCA) of two nodes  and
and  in a rooted tree is the lowest (deepest) node that is an ancestor of both and .
in a rooted tree is the lowest (deepest) node that is an ancestor of both and .
Remember that an ancestor of a node  in a rooted tree is any node that lies on the path from the root to (including ).
in a rooted tree is any node that lies on the path from the root to (including ).
For example, let’s look at the following tree, which is rooted at node 1:
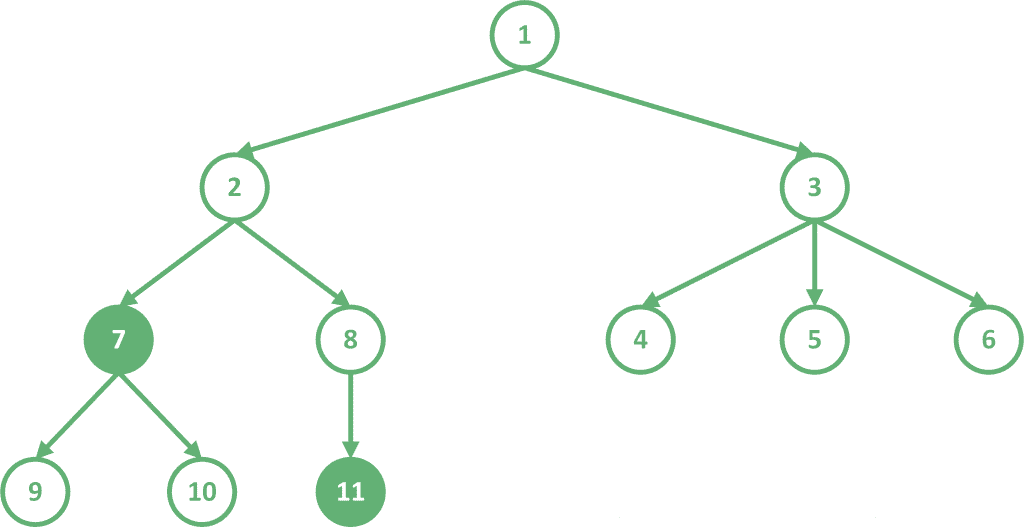
Let’s find the LCA of the two highlighted nodes 7 and 11. The common ancestors of these two nodes are nodes 1 and 2. Since node 2 is deeper than node 1,  .
.
The idea of this approach is to have two pointers, one on each node. We need to move these pointers towards the root in a way that allows them to meet at the LCA.
The first thing we can notice is that these pointers should be in the same depth. In addition to that, the deeper pointer can never be the LCA. Therefore, our first step should be to keep moving the deeper pointer to its parent until the two pointers are on the same depth.
Now, we have two pointers that are on the same depth. We can keep moving both pointers towards the root one step at a time until they meet at one node. Since this node is the deepest node that our pointers can meet at, therefore, it’s the deepest common ancestor of our starting nodes, which is the LCA.
In order to implement this solution, we will need to calculate the depth and the parent of each node. This can be done with a simple DFS traversal starting from the root.
algorithm DFS(v, Adj, Visited, Depth, Parent):
// INPUT
// v = current node
// Adj = adjacency list of the tree
// Visited = array to track visited nodes
// Depth = array to store the depth of each node
// Parent = array to store the parent of each node
// OUTPUT
// Depth and Parent arrays filled for each node
Visited[v] <- true
for u in Adj[v]:
if not Visited[u]:
Depth[u] <- Depth[v] + 1
Parent[u] <- v
DFS(u, Adj, Visited, Depth, Parent)
Firstly, we set the current node as visited. Secondly, we set the parent and depth of the child node before calling the function recursively for it.
The complexity of the preprocessing step in this approach is  , where
, where  is the number of nodes. The complexity is considered efficient because we only need to apply it once.
is the number of nodes. The complexity is considered efficient because we only need to apply it once.
After calling the previous function starting from the root, we will have the depth and parent of each node. We can now apply the approach that we discussed earlier.
algorithm NaiveLCA(u, v, Depth, Parent):
// INPUT
// u, v = Pair of nodes to find LCA for
// Depth = Array storing the depth of each node
// Parent = Array storing the parent of each node
// OUTPUT
// the LCA of nodes u and v
while Depth[u] != Depth[v]:
if Depth[u] > Depth[v]:
u <- Parent[u]
else:
v <- Parent[v]
while u != v:
u <- Parent[u]
v <- Parent[v]
return u
First of all, we keep moving the deeper node to its parent until both nodes have the same depth. After that, we move both nodes to their parents until they meet.
Although the approach is considered fairly simple, however, finding the LCA of a pair of nodes also has a complexity of  , where
, where  is the height of the tree. This complexity can go as far as becoming in case of an almost linear tree (consider two long chains connected at the root).
is the height of the tree. This complexity can go as far as becoming in case of an almost linear tree (consider two long chains connected at the root).
In order to enhance our approach discussed in section 3, we need to present some background on the sparse table data structure. The sparse table has to be built first. Then, it can then answer minimum range queries in a low complexity.
We’ll discuss the main idea of the sparse table. Later, we’ll update it to fit our needs.
A sparse table is a data structure capable of answering range queries on static arrays in  with
with  preprocessing. The intuition behind this data structure is that any range can be represented as a concatenation of at most
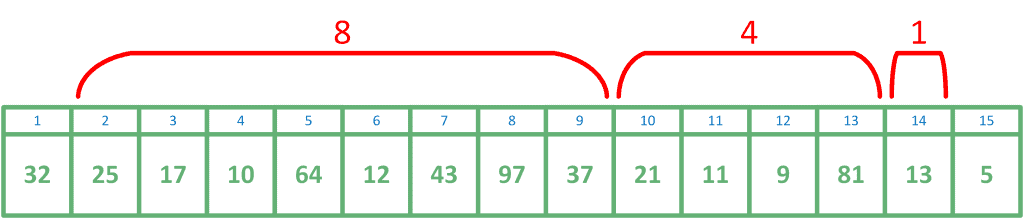
preprocessing. The intuition behind this data structure is that any range can be represented as a concatenation of at most  ranges whose lengths are powers of two. This is equivalent to representing the length of the range in binary. For example, a range of length
ranges whose lengths are powers of two. This is equivalent to representing the length of the range in binary. For example, a range of length  can be represented as the concatenation of three ranges with lengths 8, 4, and 1.
can be represented as the concatenation of three ranges with lengths 8, 4, and 1.
Let’s discuss a sparse table used to answer minimum range queries in an array  . The sparse table will consist of a
. The sparse table will consist of a  array
array  of size
of size  .
. ![ST[i][j]](/wp-content/ql-cache/quicklatex.com-263498466b78c305ad968138e3c15181_l3.svg "Rendered by QuickLaTeX.com") will store the minimum value in the range that starts at the
will store the minimum value in the range that starts at the  element of the array and has a length of
element of the array and has a length of  .
.
Let’s fill this array in increasing order of  :
:
![ST[i][0]](/wp-content/ql-cache/quicklatex.com-e40005e02be66eac4b2853bb9a910633_l3.svg "Rendered by QuickLaTeX.com") is simply equal to
is simply equal to ![Arr[i]](/wp-content/ql-cache/quicklatex.com-ce9d0649cb4126b5e2f93bb55327a286_l3.svg "Rendered by QuickLaTeX.com") . for
. for  : We know that this value is the minimum value in the range with length starting at index
: We know that this value is the minimum value in the range with length starting at index  . We can break this range into two equal parts, each of length
. We can break this range into two equal parts, each of length  , one starting at , and the other one starting at
, one starting at , and the other one starting at  . This means that is equal to the minimum value between
. This means that is equal to the minimum value between ![ST[i][j-1]](/wp-content/ql-cache/quicklatex.com-4551600d20dc8cde313c8a830843d006_l3.svg "Rendered by QuickLaTeX.com") and
and ![ST[i+2^{j-1}][j-1]](/wp-content/ql-cache/quicklatex.com-9d158744d8fa9ea1a26b3c2c0bc2cecc_l3.svg "Rendered by QuickLaTeX.com") .
.Take a look at the implementation of the algorithm.
algorithm BuildSparseTable(Arr, n):
// INPUT
// Arr = The array to preprocess (1-based indexing)
// n = Length of the array Arr
// OUTPUT
// Sparse table ST filled for range minimum queries
Log <- ceil(log2(n))
for i <- 1 to n:
ST[i, 0] <- Arr[i]
for j <- 1 to Log:
for i <- 1 to n - 2^j + 1:
ST[i, j] <- min(ST[i, j-1], ST[i + 2^(j-1), j-1])
The complexity of building the sparse table is , where is the number of elements.
Now that we have the sparse table built, let’s look at how we can answer range minimum queries using it. One way to convert a number  into binary is to go through the powers of two in decreasing order. If the current power is less than or equal to , activate the corresponding bit and subtract it from . We’ll be doing something similar. Let’s say we want to find the minimum value in the range
into binary is to go through the powers of two in decreasing order. If the current power is less than or equal to , activate the corresponding bit and subtract it from . We’ll be doing something similar. Let’s say we want to find the minimum value in the range ![[l,r]](/wp-content/ql-cache/quicklatex.com-5ace8360e5e38aee92d7525c91c7cefd_l3.svg "Rendered by QuickLaTeX.com") .
.
First, our current location is at  . We want to find the largest such that
. We want to find the largest such that  (longest range whose length is a power of 2 and contained in ). After finding this value, we can get the minimum value in this range in
(longest range whose length is a power of 2 and contained in ). After finding this value, we can get the minimum value in this range in  since it is already stored in
since it is already stored in ![ST[l][j]](/wp-content/ql-cache/quicklatex.com-b094f123dbade2dad2698ffd55e2fd05_l3.svg "Rendered by QuickLaTeX.com") .
.
Next, we have to find the minimum value in the range ![[l+2^j, r]](/wp-content/ql-cache/quicklatex.com-f8421452a2b70c3fd8ddbb733a08d84d_l3.svg "Rendered by QuickLaTeX.com") in the same way. We keep doing this until we end up with an empty interval. The values of will be strictly decreasing, so one loop through values of in decreasing order will be enough to calculate the answer.
in the same way. We keep doing this until we end up with an empty interval. The values of will be strictly decreasing, so one loop through values of in decreasing order will be enough to calculate the answer.
Let’s have a look at the described algorithm.
algorithm RangeMinQuery(L, R, ST, N):
// INPUT
// L, R = Range to find the minimum value in
// ST = Sparse table prepared by BuildSparseTable
// N = The length of the original array
// OUTPUT
// Minimum value in the range [L, R]
Log <- ceil(log2(N))
Ans <- infinity
for j <- Log to 0:
if L + 2^j - 1 <= R:
Ans <- min(Ans, ST[L, j])
L <- L + 2^j
return Ans
The complexity of querying the sparse table is , where is the number of elements.
Now that we have some background on how sparse tables work, we can take a look at a more efficient algorithm to find the LCA.
Let’s build a structure similar to a sparse table, but instead of storing the minimum/maximum value in a range whose length is a power of two, it will store the  ancestor of each node for every
ancestor of each node for every  .
.
In other words, if we had a pointer to some node , and moved this pointer to its parent times, we will end up at node ![ST[x][j]](/wp-content/ql-cache/quicklatex.com-5b31a789709997555f05dd754366bc15_l3.svg "Rendered by QuickLaTeX.com") . Let’s call this a jump from .
. Let’s call this a jump from .
Before we start building this structure, we need an array  that stores the immediate parent of each node.
that stores the immediate parent of each node.
Building the structure is similar to building a normal sparse table:
![ST[i][0] = Par[i]](/wp-content/ql-cache/quicklatex.com-20cdf3bc5278979724e4d9d70c67fde5_l3.svg "Rendered by QuickLaTeX.com") for , we need to do a jump from . However, we already know that if we do a jump from , we will end up at node
for , we need to do a jump from . However, we already know that if we do a jump from , we will end up at node ![x = ST[i][j-1]](/wp-content/ql-cache/quicklatex.com-3bbf194ef030cd1b002e717e688807ad_l3.svg "Rendered by QuickLaTeX.com") . We also know that if we do a jump from , we will end up at node
. We also know that if we do a jump from , we will end up at node ![ST[x][j-1]](/wp-content/ql-cache/quicklatex.com-95ef6ce4e7bfee559512a093ccbd5425_l3.svg "Rendered by QuickLaTeX.com") . Since two consecutive jumps are equivalent to a jump, this means that
. Since two consecutive jumps are equivalent to a jump, this means that ![ST[i][j] = ST[x][j-1] = ST[ST[i][j-1]][j-1]](/wp-content/ql-cache/quicklatex.com-6f59769db03cb24b691cec4949de7ea1_l3.svg "Rendered by QuickLaTeX.com") .
.algorithm BuildBinaryLiftingSparseTable(N, Par):
// INPUT
// N = Number of nodes in the tree
// Par = Array storing the immediate parent of each node
// OUTPUT
// Sparse table ST (N x log(N)) for binary lifting
Log <- ceil(log2(N))
for i <- 1 to N:
ST[i, 0] <- Par[i]
for j <- 1 to Log:
for i <- 1 to N:
ST[i, j] <- ST[ST[i, j-1], j-1]Now, let’s see how we can use the sparse table structure to optimize the naive approach. The naive approach consisted of two main steps.
The first step was to move the deeper pointer to its parent until both pointers are on the same depth.
Let’s assume that the deeper pointer is at node , and the other one is at node . We need to move the pointer a known amount of steps which is equal to ![Need = Depth[u] - Depth[v]](/wp-content/ql-cache/quicklatex.com-3436de8d4b79319062bb39ce5547dae4_l3.svg "Rendered by QuickLaTeX.com") . If we convert
. If we convert  into binary, and do
into binary, and do  jumps for every such that the bit is activated, we would end up with a jump. This jump would put this pointer on the same depth as the other pointer.
jumps for every such that the bit is activated, we would end up with a jump. This jump would put this pointer on the same depth as the other pointer.
Since each jump is and we need to check types of jumps, this whole step has a complexity of .
The second step was to move both pointers simultaneously until they meet at some node.
The main idea here is to try a huge jump at first. If doing a huge jump on both pointers leads them to the same node, then we have arrived at a common ancestor. However, we may have jumped too far. There could be some deeper common ancestor. So we can’t do this jump, let’s try something smaller.
If the current jump leads them to different nodes, then we should do this jump and update the pointers. This basically means that we made the largest possible jump that doesn’t reach any common ancestor yet. Therefore, the parent of both pointers will be the deepest common ancestor, which is the LCA. During this step, we also consider different jumps, so the complexity is also .
algorithm EfficientLCA(u, v, Depth, ST, N):
// INPUT
// u, v = Pair of nodes to find the LCA for
// Depth = Array storing the depth of each node
// ST = Sparse Table for binary lifting
// N = Number of nodes in the tree
// OUTPUT
// the LCA of u and v
if Depth[u] < Depth[v]:
swap(u, v)
Log <- ceil(log2(N))
Need <- Depth[u] - Depth[v]
for j <- Log to 0:
if 2^j <= Need:
u <- ST[u, j]
Need <- Need - 2^j
if u = v:
return u
for j <- Log to 0:
if ST[u, j] != ST[v, j]:
u <- ST[u, j]
v <- ST[v, j]
return ST[u, 0]
The complexity of this algorithm is , where is the number of nodes.
To recap, finding the LCA with this approach consists of two main parts:
due to the complexity of building the sparse table. since we are only doing jumps.Let’s have a final comparison between the two approaches in this tutorial.
| Naive Approach | Binary Lifting | |
|---|---|---|
| Preprocessing Complexity | |
 |
| Complexity per query | |
 |
| Memory Complexity | |
|
| Requirements |  |
 |
The main bonus when using the binary lifting approach is that we can handle a large number of queries. First, we have to apply the preprocessing once, and then we can have a large number of queries, where each query is answered in . Therefore, each query will be answered in a better complexity than when using the naive approach.
In this tutorial, we’ve discussed the Least Common Ancestors problem for tree data structures.
First, we took a look at the definition, then discussed two methods of finding the LCA. Finally, we did a simple comparison between the two methods.