

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
With the variety of existing attacks and exploits, security became a prominent concern for current digital systems. In this context, academia and industry moved efforts to propose efficient security mechanisms, overcoming a particular threat at a time.
One of these mechanisms is hashing. In summary, hashing aims to provide security, privacy, and even authenticity to digital data.
To accomplish the hashing mechanisms objectives, they employ different mathematical functions to transform a given sequence of data (source) into another one (result).
However, sometimes it is necessary to apply multiple hashing mathematical functions to the same data to guarantee strong security and reliability: a method called salting.
In this tutorial, we’ll learn about simple hashing and salted hashing. First, we’ll explore basic concepts of hashing mechanisms. Then, we’ll analyze simple hashing algorithms, highlighting their advantages and disadvantages. Similarly, we’ll study salted hashing. Finally, we’ll compare simple hashing and salted hashing in a systematic summary.
2. Basics of Hashing
Hashing, in short, consists of a mechanism to translate a given variable-length sequence of bytes into another byte sequence with a fixed length. So, we can call the hashing result (the fixed-length byte sequence) of hashes, hash codes, or digest.
Hashing mechanisms use a mathematical function (often called hash function) to do the described mapping process.
Hashing mathematical functions, in turn, are one-way processing. Thus, it processes the output for a given input without difficulties. However, it is hard, or even impossible, to determine the original input through its previously computed respective output.
A big concern regarding hashing is choosing an efficient mathematical function to do the mapping operations. In this way, we can observe some properties to select good mathematical functions:
- Easy computation: the computation of mathematical functions shouldn’t require complex algorithms or much processing power
- Uniform distribution: the hashes generated by the function should uniformly distribute in the range of possible codes, avoiding clusters
- Collisions avoidance: collisions occur the same output (the same hash code) is generated for different inputs. An adequate mathematical function avoids collision as much as possible
Even trying to avoid them, collisions are inevitable in hashing. As we saw, hashing maps any input to a fixed-length output. So, there are unlimited inputs to a limited number of outputs.
In such a way, we can understand collision not as a problem but as a characteristic to be managed when developing hashing mechanisms.
Finally, hash tables are structures used to link original inputs to their respective hash codes. Thus, we can recover the original input through the hashes with these tables.
The following image depicts the process of computing hashes abstractly:

2.1. Hashing Applications
Hashing has several applications in the computing context. We briefly describe some of the most typical applications next:
- Storing private information: passwords, credit card numbers, and other information with privacy and security requirements are frequently stored in databases as hashes
- Creating data structures: several programming languages use hashing to create key-value structures. Examples of these structures are dictionaries in Python and HashMaps in Java
- Signing digital documents: several digital sign methods use hashing to check the integrity of documents
3. Simple Hashing
Simple hashing consists of executing the hashing process only once for each provided input. We can understand it as the simplest and straightforward way to use hashing.
Let’s consider that we are hashing passwords of a given system when registering a user. In a simple hashing process, we receive the passwords, submit them to a single hashing mechanism, and store the results into a particular column of the user’s table.
Thus, when a user tries to log in, he sends his password hash. The login system, in turn, only checks if the provided hash corresponds to the registered user’s hash: if yes, the login succeeds; otherwise, the login fails.
The following image depicts the presented example:

The main advantage of using simple hashing is the high performance of comparing provided hashes with the stored ones. Furthermore, as the comparison is direct, it does not require any extra operation.
The main disadvantage, in turn, consists of the vulnerabilities of simple hashing.
For example, attacks that benefit from simple hashing employment are brute force attacks and rainbow table attacks.
4. Salted Hashing
Salted hashing consists of subsequently submitting inputs to a series of hashing and reductions mechanisms. In this context, the reduction process converts a hash into plaintext.
It is relevant to highlight that the reduction process also employs a one-way mathematical function. However, this function doesn’t revert the hash function. So, the reduction process converts a hash into a plaintext different from the original input.
Let’s consider the same example shown in the single hashing section. Again, if we use salted hashing, we’ll execute at least two hashing mechanisms and one reduction mechanism.
Thus, when we receive a password, it is submitted to the first hashing mechanism. The result of this mechanism is then submitted to the reduction mechanism. Then, the plaintext generated is hashed again with the second hashing mechanism. Finally, the password is stored.
The routine of reduction and hashing processes can repeat as much as necessary.
In this way, when the user tries to log in, we must compare the provided hash with the ones stored in the credentials database. If it matches, the login succeeds. But, if there is not a match, we reduct the hash and execute the subsequent hashing mechanism, testing the result with the database.
This process repeats until all the available reductions/hashing mechanisms execute. If none of the generated hashes matches, the login fails.
The following image shows the described process of salting hashes:
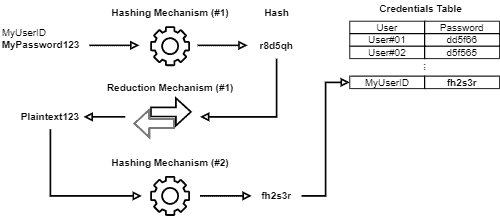
The main advantage of using salted hashed is the improvement of security. Salted hashes are more robust against brute force and rainbow table attacks.
The main disadvantage, in turn, consists of the extra processing needed to compare hashes. Salted hashing typically requires more computational resources and time to do the matching check.
5. Systematic Summary
In the previous sections, we studied the mechanisms of simple hashing and salted hashing in terms of the security they provide and the processing power required to compute them.
Summarily, we can note a clear tradeoff between security and processing power. In this way, as the security increases when salting hashes, the processing power required to compute them also increases.
Thus, the main advantage of using simple hashing mechanisms consists of fast computation and a straightforward and cheap process to compare received hashes with a particular hash table.
On the other hand, the main advantage of employing salted hashing mechanisms is their security gain, better tolerating attacks and exploits, such as brute force and rainbow table attacks.
The following table presents and compares some characteristics of both simple hashing and salted hashing:
| Simple Hashing | Salted Hashing | |
|---|---|---|
| Hashing Iterations | = 1 | > 1 |
| Processing Power | Low (when compared to salted hashing) | High (when compared to simple hashing) |
| Rainbow Table Attacks | Very susceptible | Very robust (if well planned) |
| Brute Force Attacks | Can find the plaintext corresponding to the hash quickly | Typically, requires much time to find the plaintext corresponding to the hash |
6. Conclusion
In this tutorial, we learned about simple and salted hashing. First, we had an overview of the general concepts of hashing. So, we in-depth studied how simple hashing works. Similarly, we analyzed the particular characteristics of salted hashing. Finally, we overviewed and compared the studied concepts in a systematic summary.
We can conclude that hashing is essential to the current computing scenario. Hashing enables several relevant functionalities, such as secured data storing and digital signing.
Choosing between simple hashing or salted hashing, in turn, is a decision that should consider the desired security level in contrast to the available computing power and processing time.