

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Disk scheduling is a major part of modern computer systems, directly impacting overall performance. The constant demand for systems with better I/O operations and faster data retrieval makes developing different disk scheduling algorithms necessary. Additionally, performance is significantly impacted by selecting the appropriate algorithm.
In this tutorial, we’ll discuss the SCAN disk scheduling algorithm. We will delve into the principles and operation of SCAN, its advantages and disadvantages, and provide examples for a deeper understanding of how it works.
The SCAN algorithm is also known as the Elevator Algorithm. It dates to the early days of computing when optimizing disk access first became a concern. Its development aimed to retrieve data more efficiently from rotating storage devices.
Effectively handling an endless flow of read/write requests aimed at a disk drive is a problem that arises in the context of disk scheduling. The goal is to maximize the performance of the disk system, mainly by reducing head movement or seeking time, which is an essential component of effective disk operations.
The SCAN algorithm is one of the algorithms designed to tackle this concern. It iteratively scans the disk’s surface, servicing requests as it goes and reversing direction upon reaching the disk’s end. The main objective of SCAN is to decrease seek time, thereby improving disk system efficiency. Also, the speed at which data is retrieved is enhanced.
However, the algorithm’s optimality may differ based on particular workloads and access patterns. Hence, choosing the best disk scheduling plan for a specific system is an important design choice.
Two operational principles govern the SCAN algorithm:
The read/write head starts at one end of the disk and moves in a single direction, either inward or outward, until it reaches the opposite end.
Then, it takes the reverse direction and repeats the process. This unidirectional movement reduces seek-time and mimics how elevators go up and down.
Requests are served on the wait list based on their (directed) proximity to the current head position. Hence, the requests closer to the head’s position in its current direction are processed first, which minimizes head movement.
Let’s consider the pseudocode of the SCAN algorithm. The algorithm takes a queue of requests, the current position of the disk-head and the direction of movement (either left or right) as input. It then optimizes the disk access to enhance performance:
algorithm SCANScheduling(queue, initial_position, direction):
if direction = "right":
queue = queue.append(0)
else:
queue = queue.append(disk_size - 1)
sort(queue) // Sort the queue in ascending order
While queue is not empty:
If direction = "right":
current_position <- initial_position
while current_position <= maximum_position:
for request in queue:
if request >= current_position:
process_request(request)
current_position <- request
remove request from queue
break
current_position <- current_position + 1
direction <- "left" // Change direction to left
if direction = "left":
current_position <- initial_position
while current_position >= minimum_position:
for request in reversed(queue):
if request <= current_position:
process_request(request)
current_position <- request
remove request from queue
break
current_position = current_position - 1
direction = "right" // change direction to right
New requests are added to the queue. However, they are scheduled for the next pass when the head reaches the end. The algorithm prioritizes requests in the direction of movement and closer to the current head position.
The SCAN disk scheduling algorithm initiates by setting the disk head at one extremity of the disk and managing pending I/O requests within a designated queue. The algorithm maintains one-directional movement of the disk head, progressing either from left to right or vice versa. Along the trajectory, requests are serviced based on their proximity to the head but exclusively in the direction of its movement.
Upon reaching the end of the disk in its current direction, the SCAN reverses direction, changing from left to right or vice versa. The algorithm processes requests along the reversed path until it services the last (farthest) request.
This iterative process persists until all pending requests have been handled. Upon completion, the algorithm terminates, and the disk head reverts to its initial position, concluding the SCAN disk scheduling procedure.
For a deeper understanding, let’s consider the example we used for the LOOK and CLOOK algorithms.
A disk has 251 tracks and a queue of access requests: 240, 94, 179, 51, 118, 15, 137, 29, and 75. The Read/Write head (C) is initially located at track 55 and is moving to the right:
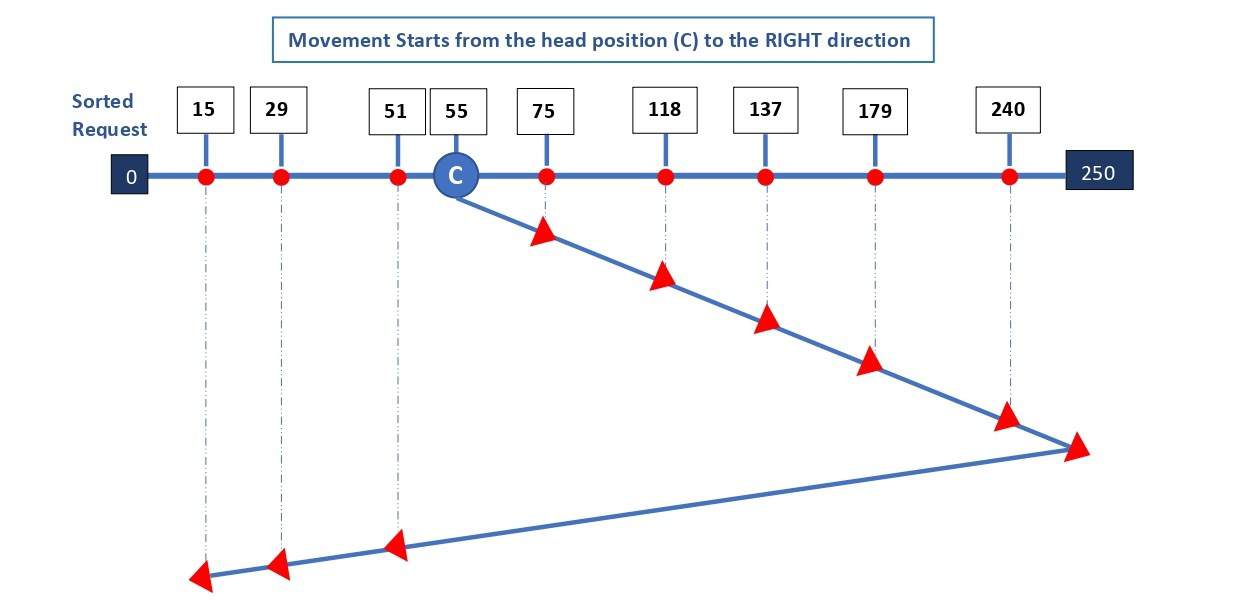
The movement towards the right stops at the end of the disk (250), even though no request is at 250. Then, it reverses its direction and stops at the last request (in track 15). Hence, the total head movement ( ) is:
) is:
![\[THM = (250-55) + (250-15) = 195 + 235 = 430\]](/wp-content/ql-cache/quicklatex.com-069943de4ceac60bb6b5160eb3dde371_l3.svg "Rendered by QuickLaTeX.com")
The diagram below illustrates the SCAN algorithm in a case where the head direction is towards the left:
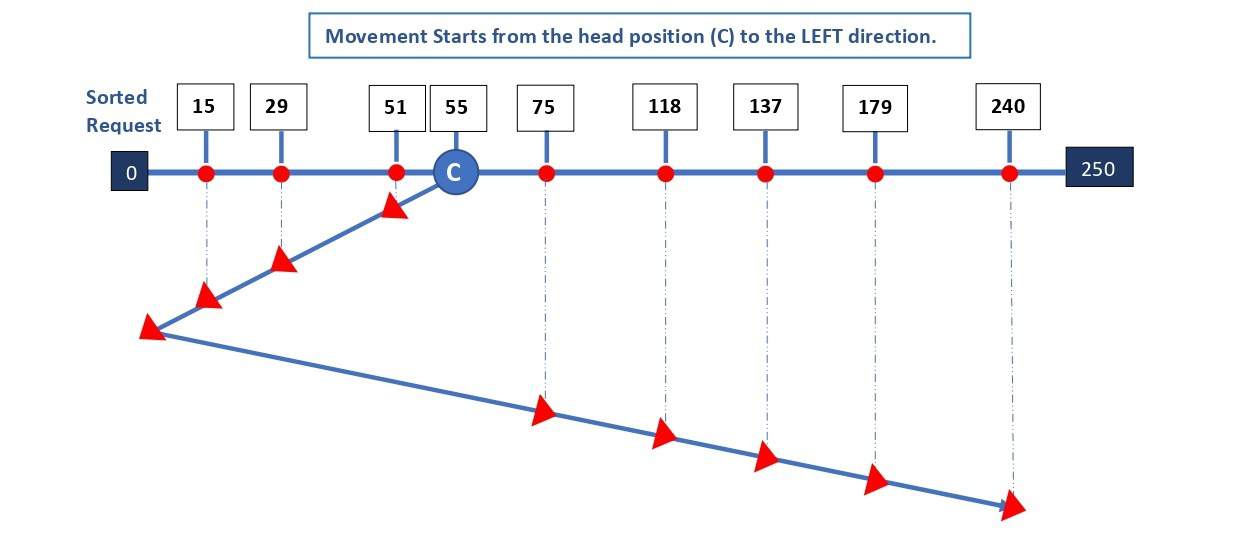
The movement towards the left stops at the end of the disk (0), even though there’s no request at 0. Then, the head reverses its direction and stops at the last request (in track 240). Hence, the total head movement () is:
![\[THM = (55-0) + (240-0) = 55 + 240 = 295\]](/wp-content/ql-cache/quicklatex.com-0f3bb2eed1678ce6b97f014b9ce8c395_l3.svg "Rendered by QuickLaTeX.com")
Here’s a quick summary of SCAN’s advantages and disadvantages:
| Advantages | Disadvantages |
| Minimized seek time | Inefficient direction changes |
| Fair access | No time guarantees |
| Prevents starvation | Has variable service time |
| Predictable behavior | Lack of adaptability |
Let’s discuss them in detail.
Firstly, SCAN minimizes seek time by reducing the read/write head’s traversal distance. As a result, it retrieves data faster than other algorithms like FCFS. Additionally, SCAN provides fair access to all pending requests by scanning the entire disk surface, making it suitable for multi-user environments.
Unlike algorithms such as Shortest Seek Time First (SSTF), it also prevents starvation by processing all requests over time, ensuring older requests are eventually serviced. Lastly, SCAN exhibits predictable behavior with its back-and-forth scanning pattern. This aids in request anticipation, which can be advantageous in specific applications.
SCAN may suffer from inefficient direction changes due to frequent shifts, potentially leading to suboptimal performance.
Moreover, SCAN isn’t ideal for real-time systems demanding strict response time guarantees. Service-time variability can be high in SCAN, depending on the request distribution.
Lastly, the lack of adaptability in SCAN hinders its effectiveness in dynamic environments with changing request patterns, limiting its versatility in such scenarios.
In this article, we discussed the SCAN algorithm. It minimizes the seek time, provides fair access, and prevents starvation. However, it has drawbacks, such as the lack of adaptability and inefficiency in systems with frequent direction changes.
Therefore, the SCAN scheduling algorithm is well-suited for real-time systems. Particularly in applications like multimedia streaming or interactive scenarios, where minimizing disk arm movement enhances responsiveness by efficiently servicing requests along a unidirectional path, reducing seek time.