

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Disk scheduling is the process of arranging the order in which read/write operations are carried out on a computer’s hard disk. In modern computer systems, hard disks have a large storage capacity, and the data is stored in tracks and sectors.
The disk scheduling algorithms aim to optimize the use of the hard disk by reducing the seek time and rotational latency, which ultimately results in improved performance and efficiency of the system.
In this tutorial, we’ll discuss two disk scheduling algorithms – LOOK and CLOOK – and compare their performance and efficiency.
The LOOK algorithm is a disk scheduling algorithm that scans the disk from the current position of the disk arm to the last request in one direction and then moves back to the first request in the opposite direction.
The LOOK algorithm is designed to reduce the seek time by minimizing the distance the disk arm has to travel to service a request. The algorithm schedules the requests in such a way that the disk arm moves continuously in one direction without any backtracking, which indirectly improves performance by maximizing throughput and reducing the total time required to access and retrieve data from the disk.
The LOOK algorithm is a simple and efficient algorithm that can handle high loads of requests. It is also a fair algorithm that ensures that no request is starved, i.e., no request waits indefinitely for service.
However, the LOOK algorithm can cause disk arm thrashing, where the disk arm moves rapidly back and forth between the innermost and outermost tracks of the disk, resulting in increased access time and reduced performance.
The pseudocode of the LOOK algorithm is as follows:
algorithm LookDiskScheduling(queue, initial_position, direction):
// INPUT
// queue = the list of disk access requests
// initial_position = the initial position of the disk arm
// direction = the initial direction of the disk arm ("right" for outward, "left" for inward)
// OUTPUT
// The ordered scheduling of disk requests based on the LOOK algorithm
Sort(queue) // Sort the queue in ascending order
while queue is not empty:
if direction = "right":
current_position <- initial_position
while current_position <= maximum_position:
for request in queue:
if request >= current_position:
process_request(request)
current_position <- request
remove request from queue
break
current_position <- current_position + 1
direction <- "left" // Change direction to left
if direction = "left":
current_position <- initial_position
while current_position >= minimum_position:
for request in reversed(queue):
if request <= current_position:
process_request(request)
current_position <- request
remove request from queue
break
current_position <- current_position - 1
direction <- "right" // Change direction to rightLet’s consider an example of a disk with 251 tracks and a queue of disk access requests in the following order: 240, 94, 179, 51, 118, 15, 137,29 75. The current position of the Read/Write head (C) is at track 55 and moving in the Right direction. The LOOK algorithm can be illustrated as shown in the below diagram:
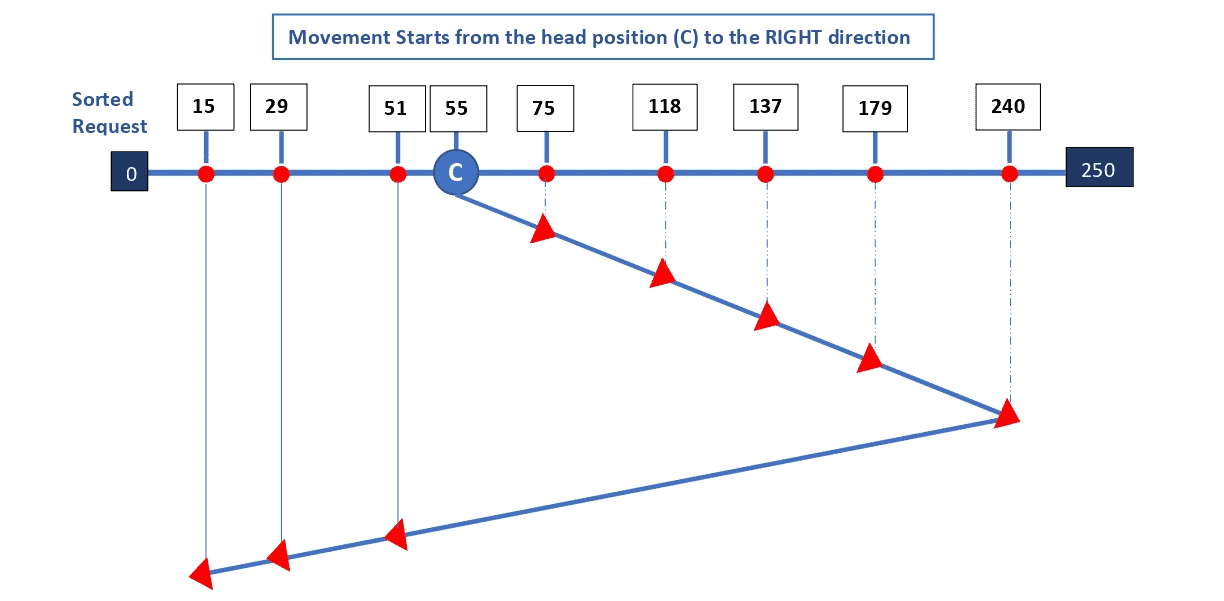
The total head movement ( ) can be calculated as follows:
) can be calculated as follows:
![\[ \text{$THM$} = (240-51) + (240-15) \]](/wp-content/ql-cache/quicklatex.com-c9cac3c69f492c892a56a32b0f58af4e_l3.svg "Rendered by QuickLaTeX.com")
![\[ \text{$THM$} = 189 + 225 \]](/wp-content/ql-cache/quicklatex.com-3d06500808ac5041ad1b11b6d7b64644_l3.svg "Rendered by QuickLaTeX.com")
![\[ \text{$Total Head Movement$} = 414 \]](/wp-content/ql-cache/quicklatex.com-e8fa186ee0352b9b7f04bede2186c01b_l3.svg "Rendered by QuickLaTeX.com")
The CLOOK algorithm (circular LOOK) is a disk scheduling algorithm similar to the LOOK algorithm but differs in how it handles the requests. The CLOOK algorithm scans the disk in one direction only, from the current position of the disk arm to the last request in that direction, and then starts again from the first request in that direction.
The CLOOK algorithm reduces the seek time and rotational latency by scheduling the requests in a circular manner, where the disk arm moves from the outermost track to the innermost track and then back to the outermost track.
The CLOOK algorithm is a more efficient algorithm than the LOOK algorithm and outperforms all other disk scheduling algorithms. However, it is not a fair algorithm and can cause some requests to starve. This is because the algorithm only services requests in one direction, and any request in the opposite direction is ignored.
The pseudocode of the CLOOK algorithm is as follows:
algorithm CLookScheduling(queue, initial_position, direction):
// INPUT
// queue = a list of disk requests
// initial_position = the starting position of the disk head
// direction = the initial direction of disk head movement ("right" or "left")
// OUTPUT
// The disk requests are processed in the CLOOK order
Sort(queue) // Sort the queue in ascending order
while queue is not empty:
if direction = "right":
current_position <- initial_position
while current_position <= maximum_position:
for request in queue:
if request >= current_position:
process_request(request)
current_position <- request
remove request from queue
break
current_position <- current_position + 1
initial_position <- minimum_position // Start from the first position
if direction = "left":
current_position <- initial_position
while current_position >= minimum_position:
for request in reversed(queue):
if request <= current_position:
process_request(request)
current_position <- request
remove request from queue
break
current_position <- current_position - 1
initial_position <- maximum_position // Start from the maximum (last) positionLet’s illustrate the LOOK algorithm using the example we considered in subsection 2.2:
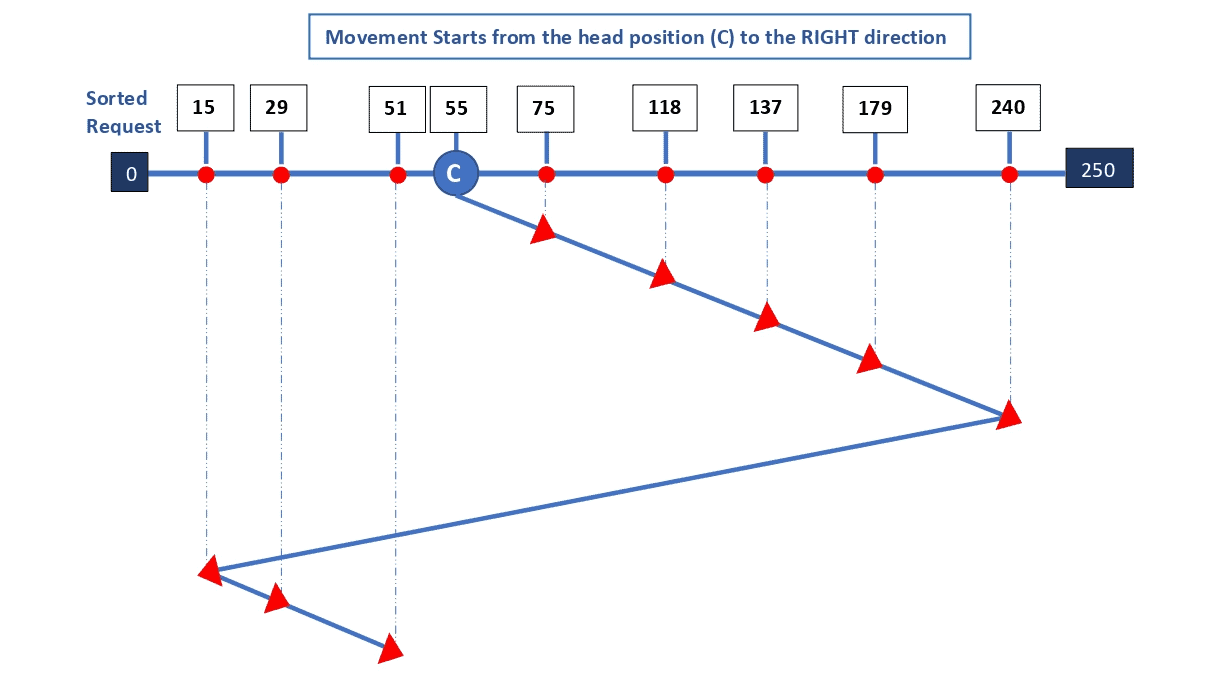
The total head movement () can be calculated as follows:
![\[ \text{$THM$} = (240-51) + (240-15) + (51-15) \]](/wp-content/ql-cache/quicklatex.com-d8c40218ac77a34f8bf172fe37417fea_l3.svg "Rendered by QuickLaTeX.com")
![\[ \text{$THM$} = 189 + 225 + 36 \]](/wp-content/ql-cache/quicklatex.com-edaf208ad95f83d5fb048b8d04d08229_l3.svg "Rendered by QuickLaTeX.com")
![\[ \text{$Total Head Movement$} = 450 \]](/wp-content/ql-cache/quicklatex.com-6c69a1ec3be7b901e661c6d1c3b68043_l3.svg "Rendered by QuickLaTeX.com")
| Criteria | LOOK Algorithm | CLOOK Algorithm |
|---|---|---|
| Scan direction | Both directions (outward and inward) | One direction (outward only) |
| Request handling | Services requests in both directions | Services requests in one direction only |
| Starvation | No request is starved | Requests in the opposite direction may starve |
| Efficiency | Handling request is not as efficient as in CLOOK | More efficient in handling request as compared to LOOK |
| Arm Movement | Minimizes head movement | Requires more head movement |
| Time | Better throughput and low variance in response time | Uniform wait and response time |
| Performance | Lower Performance compared to CLOOK | Better Performance compared to LOOK |
| Best suited for | Systems that require fairness and service all requests. Also suitable for systems with a high load of requests. | Systems that require high performance and can tolerate some requests starving. Not suitable for heavy loads |
Overall, the LOOK algorithm is fairer to all requests, while the CLOOK algorithm is better suited for systems that require high performance.
In this article, we discussed two disk scheduling algorithms – LOOK and CLOOK, comparing their performance and efficiency.
Both algorithms have their strengths and weaknesses, and the best algorithm should be chosen based on the needs of the system. Hence, the choice between the LOOK and CLOOK algorithms depends on the specific requirements and constraints of the system.