

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
A key part of neural network architecture is the non-linearity. Without it, as the name suggests, neural networks would just be compositions of linear functions. Meaning they would be linear functions. Without them, they would not have the powerful learning and representation capacity.
So, what are they? What does it mean for a non-linearity to saturate? Are there non-saturating non-linearities? These questions illuminate the inner workings of a neural network and are key to understanding many modern designs and implementations.
In this tutorial, we answer those questions. We first introduce non-linearities and what it means for them to saturate. Secondly, we explore the problems caused by saturation, and in the final part of this tutorial, we discuss detecting, measuring, and avoiding saturation.
When implementing a neural network, we normally introduce a weight matrix multiplied by some input vector. To solve more complex problems, we need to turn this linear operation into a non-linear one. This will allow us to approximate non-linear functions. This is the goal of the non-linearity.
Often, the first non-linearity introduced when learning about neural networks is the Sigmoid function. This is a differentiable version of the step function, which would output either a  or a
or a  signaling whether or not the neuron fired. Another common activation function is the hyperbolic tangent or TanH function. Similar to the Sigmoid function, it squashes values to the range
signaling whether or not the neuron fired. Another common activation function is the hyperbolic tangent or TanH function. Similar to the Sigmoid function, it squashes values to the range![[-1,1]](/wp-content/ql-cache/quicklatex.com-4bdbf4ffe70a83081dc3d345be95ce20_l3.svg "Rendered by QuickLaTeX.com") :
:
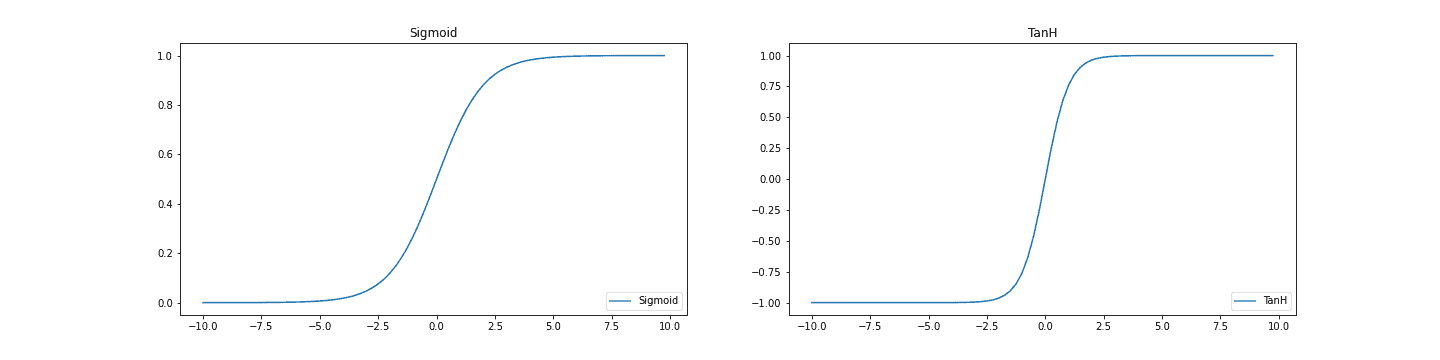
A saturating non-linearity is a function that squeezes the input into a fixed(bounded) interval. Saying this, it is easy to see that the sigmoid function is a saturating non-linearity.
We can also state that property more formally.
A function  is non-saturating iff
is non-saturating iff 
is saturating iff is not non-saturating
Using the formal definition, we see that if the non-linearity continues to grow towards infinity, then it is non-saturating. This insight will make it easy to see why the solution we propose to the problem of saturating non-linearities works.
We also note the definition of non-saturating only proposes that the function has to grow to infinity in one direction. The “Or” condition,  , shows that the value should grow to infinity as
, shows that the value should grow to infinity as  decreases or as increases. Importantly, it doesn’t have to grow to infinity in both directions.
decreases or as increases. Importantly, it doesn’t have to grow to infinity in both directions.
Why is saturation undesirable? For a neural network, saturating non-linearities will lead to a binary state for a neural network block. This is where the network block is predominantly outputting values close to the asymptotes of the non-linearity. This reduces the representational capacity of the block, and so the network as a whole.
For a saturated unit, a small change in the incoming weights will have almost no influence on the output of the unit. Therefore, a training algorithm used for weight optimization will struggle to determine whether the weight change positively or negatively affects the neural network’s performance. As a result, the training algorithm will stagnate, and no further learning will occur.
Thinking about training a neural network. To train a network, we perform the backpropagation algorithm. This means we must compute the gradient for each of the layers in our network. The problem with saturating non-linearities is that, when they saturate, their gradient is not very informative. Since there is only a small change in output, the gradient of the change is small. It is, therefore, more difficult to train the network.
It is also worth checking our intuitions when using a sigmoidal activation as a neural network output. If we are considering a binary-coded output, then, binary saturating outputs might appear to be appropriate. A downside of saturation is that the outputs don’t indicate a level of confidence. All patterns will be classified with the same or similar strength, even those that are not fit as well. This restricts the model when improving the solution.
We can take the sigmoid function as a specific example. We see in the diagram that where the sigmoid function saturates, the gradient of the function is close to 0. It also does not change much with respect to the input. This produces an uninformative signal that can make learning slow, as we will only take very small update steps:
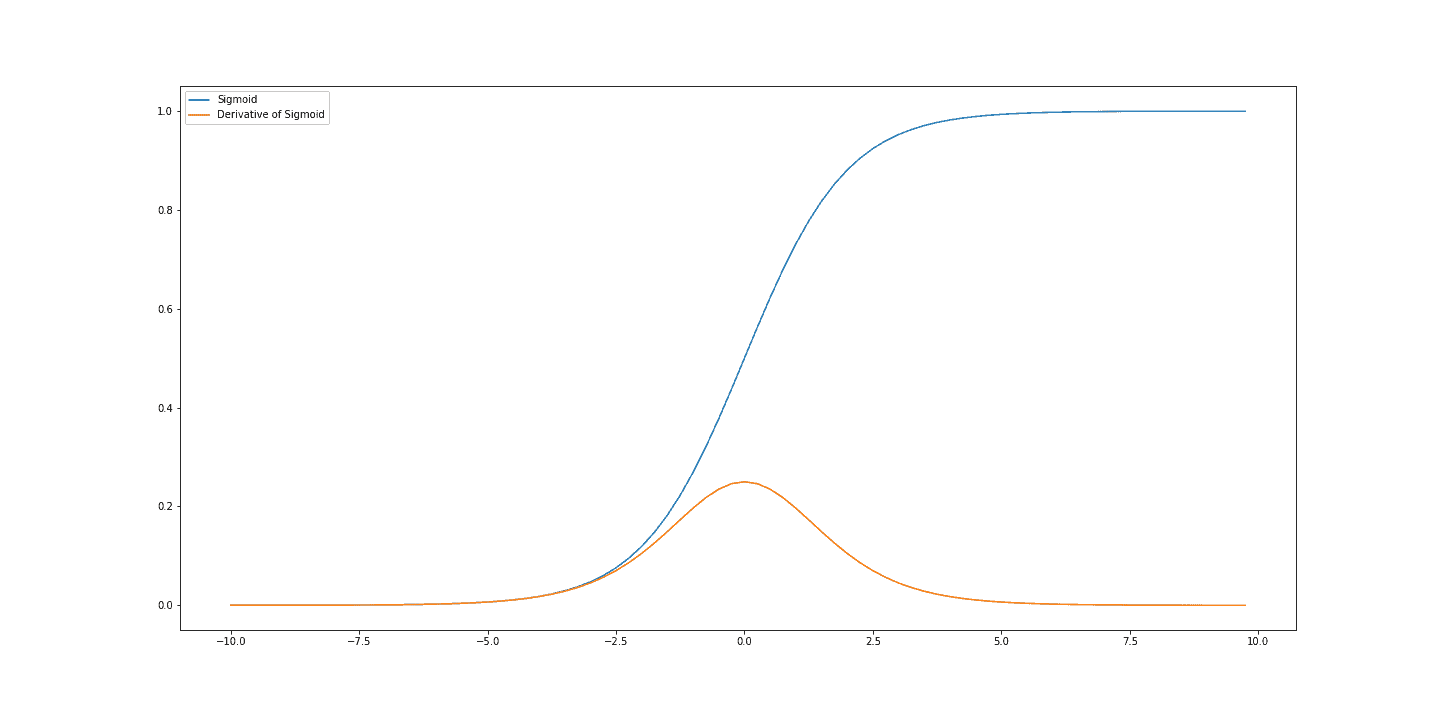
This issue of slow learning is compounded when we have deep neural networks. Since we must propagate the gradient back through the layers of the network, if the gradient is small, caused by a saturating non-linearity, then earlier layers will receive only a very limited signal. This problem is known as the vanishing gradients problem.
In the neural network context, the phenomenon of saturation refers to the state in which a neuron predominantly outputs values close to the asymptotic ends of the bounded activation function.
Saturation damages a neural network’s information capacity and learning ability. The degree of saturation is an important neural network characteristic that can be used to understand the behavior of the network itself, as well as the learning algorithm employed.
Saturation can be measured. The measure should be independent of the range of the function. It should also allow for direct comparisons between functions. Such a measure can be used to identify the source of problems during training.
One such measurement was proposed in this paper where the outputs for a bounded activation are binned to estimate a frequency distribution over the output range of the non-linearity. We take the average over every activation that falls into a given bin. The values are then normalized. Finally, a weighted average is computed using the bin-frequency as a weight.
This produces a bounded value that approaches when saturation is high. If the value is  , then the frequency distribution is approaching the normal distribution. The less saturation occurs, the value approaches . This value should be computed across a range of inputs to the network.
, then the frequency distribution is approaching the normal distribution. The less saturation occurs, the value approaches . This value should be computed across a range of inputs to the network.
For an activation  we compute:
we compute:

Where  is the number of elements in the given bin. We then perform a min-max normalization to scale everything to the range . Finally, we compute the frequency-weighted average activation:
is the number of elements in the given bin. We then perform a min-max normalization to scale everything to the range . Finally, we compute the frequency-weighted average activation:

To solve the problem of saturating non-linearities, we can look for non-linearities that don’t saturate. One popular family is the Rectified Linear Unit and its variants. The ReLU is as  . In this way, ReLU has a minimum value but no maximum value.
. In this way, ReLU has a minimum value but no maximum value.
The ReLu function may seem confusing, as it is limited when values are negative. If we recall our definition of non-saturating from earlier, we see that since for positive values it grows linearly and is unbounded, ReLU is non-saturating. That does not mean ReLU is problem-free. The dead neuron problem, where ReLU constantly spits out zeros, causes the same lack of gradient. The cause, however, is related to the weights being too small.
An alternative solution to the problem of saturating non-linearities is to apply batch-normalization while training. The normalization helps to scale the activations. This, in turn, reduces the risk of saturation.
Utilizing a weight initialization strategy such as He initialization is also considered good practice. Initializing the weights of the network to appropriate values has been shown to improve learning. This is in part due to reducing the chance of experiencing saturating non-linearities early on in training.
Further still, techniques such as residual connections, as used in the ResNet architecture, provide a bypass of the non-linearity and allow gradients to flow easily through the network. This is especially relevant as networks become deeper.
In this article, we discuss non-linearities – a key component of neural networks. The problems of saturating non-linearities have been identified. They slow down training by producing a small and uninformative gradient. Solutions, such as non-saturating non-linearities, have been proposed. These produce a more consistently informative gradient. Other solutions, such as batch-norm, can also address the problem.