

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we discuss in what cases should we avoid using regular expressions when working with text.
At the end of this article, we’ll be able to identify those cases and know what tools to use in place of RegExes.
Regular expressions are a powerful tool for working with formal languages. They aren’t useful, though, when working with languages that aren’t formal, such as markup languages.
A common mistake when working with RegExes is to attempt to use them to parse HTML and XML. With the exception of files with a structure that can be predicted aprioristically, such as those originating from an XML repository that we, ourselves, manage, these attempts are bound to fail.
This is because the tree structure of HTML and XML files requires a RegEx to keep track of all opening and closing of the markup tags. Further, the search space for the tree that contains markup tags is arbitrarily large, which means two things:
When we’re working with HTML or XML, therefore, we should use an HTML or XML parser instead of RegExes.
Sometimes we can erroneously try to solve a problem with regular expressions when the problem itself can be simply tackled with a plain search.
Let’s imagine we’re searching for the color of paint used on the walls of a house:
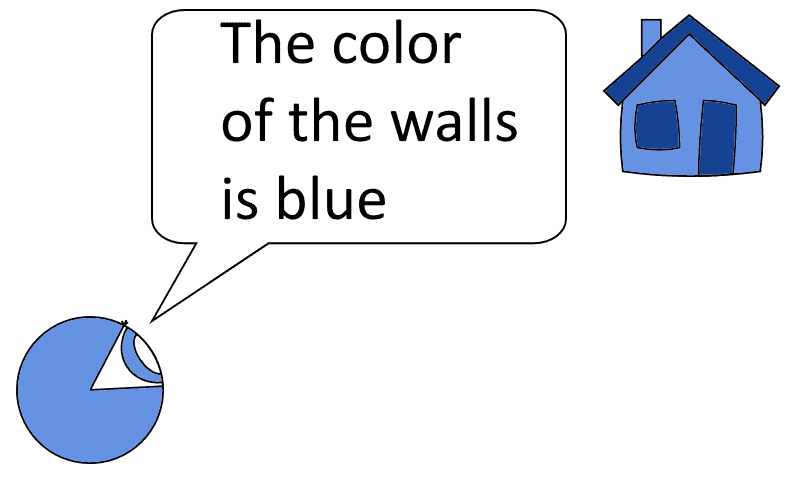
We could try to formulate a RegEx that matches any of the possible colors that a wall could have:
 “(gr(a|e)y|white|black|blue|red|green| … )”
“(gr(a|e)y|white|black|blue|red|green| … )”
Or we could simply use the search function and find the word “color”, and read the specific color indicated in the proximity of this word:

If we used a RegEx for this task, we would spend more time coming up with the formula than applying it. In this case, the usage of RegExes is unwarranted.
This problem characterizes not only color names but most tasks where the information being sought occurs only once in a text. As a consequence, it’s a problem that’s encountered very commonly in practice. If a problem can be solved with a simple search, we should avoid using regular expressions.
Another case involves the usage of RegExes for the censoring of user behavior. This type of interaction between a programmer and a user base can sometimes assume an adversarial character. This is, for instance, the case in which we’re building a spam filter, a filter for profanities, or a system for shadow banning.
In this context, while RegExes can be used to bootstrap a filter, we have to expect the users to eventually learn how the filter works, and to try to get around it.
Let’s imagine we have a website for bicycle lovers who hate cars:
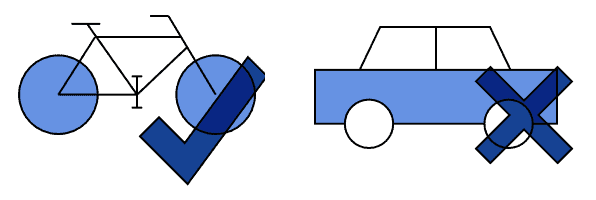
We may think to identify and filter comments that talk about “cars” with RegExes, by including common character substitutions:
“c(a|4)r”
Our users could, however, get through the filter by using the words “automobile”, or “the thing with four wheels”, or other compound expressions that humans understand but filters can’t recognize.
One last case concerns the usage of RegExes that contain Boolean operations. As we discussed in our article on the basic laws of Boolean algebra, there are methods for simplifying Boolean expressions that allow their algorithmic evaluation.
The standard implementations of RegExes don’t have the and operator  ; they do however have the or operator “|” and the negation lookahead operator “?!”. This means that it’s possible to use De Morgan’s laws to build expressions that equate to the logical operator and:
; they do however have the or operator “|” and the negation lookahead operator “?!”. This means that it’s possible to use De Morgan’s laws to build expressions that equate to the logical operator and:
 “(?![^P]|[^Q])”
“(?![^P]|[^Q])”
In this formula, we can replace the uppercase letters  and
and  with any sets of characters such that
with any sets of characters such that  .
.
If a RegEx with Boolean operators uses a succession of Boolean operators, it’s, therefore, possible that a simplification exists that always evaluates to false. If this is the case, the RegEx will never match and its usage is thus unwarranted.
This also means that, when we use Boolean operations inside RegExes, we must make sure that the formula actually evaluates to true for at least some values.
In this tutorial, we studied some common cases in which we shouldn’t use RegExes.