

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Prime numbers have always been an interesting topic to dive into. However, no one has been able to find a clean and finite formula to generate them. Therefore, mathematicians have relied on algorithms and computational power to do that. Some of these algorithms can be time-consuming while others can be faster.
In this tutorial, we’ll go over some of the well-known algorithms to find prime numbers. We’ll start with the most ancient one and end with the most recent one.
Most algorithms for finding prime numbers use a method called prime sieves. Generating prime numbers is different from determining if a given number is a prime or not. For that, we can use a primality test such as Fermat primality test or Miller-Rabin method. Here, we only focus on algorithms that find or enumerate prime numbers.
Sieve of Eratosthenes is one of the oldest and easiest methods for finding prime numbers up to a given number. It is based on marking as composite all the multiples of a prime. To do so, it starts with  as the first prime number and marks all of its multiples (
as the first prime number and marks all of its multiples ( ). Then, it marks the next unmarked number (
). Then, it marks the next unmarked number ( ) as prime and crosses out all its multiples (
) as prime and crosses out all its multiples ( ). It does the same for all the other numbers up to
). It does the same for all the other numbers up to  :
:
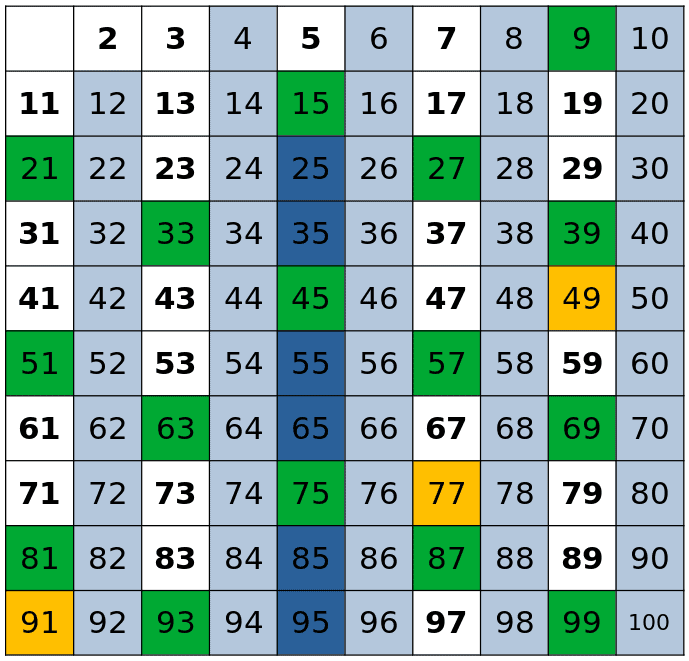
However, as we can see, some numbers get crossed several times. In order to avoid it, for each prime  , we can start from
, we can start from  to mark off its multiples. The reason is that once we get to a prime in the process, all its multiples smaller than have already been crossed out. For example, let’s imagine that we get to
to mark off its multiples. The reason is that once we get to a prime in the process, all its multiples smaller than have already been crossed out. For example, let’s imagine that we get to  . Then, we can see that
. Then, we can see that  and
and  have already been marked off by
have already been marked off by  and . As a result, we can begin with
and . As a result, we can begin with  .
.
We can write the algorithm in the form of pseudocode as follows:
algorithm FindPrimesEratosthenes(n):
// INPUT
// n = an arbitrary number
// OUTPUT
// prime numbers smaller than n
A <- an array of size n with boolean values set to true
for i <- 2 to sqrt(n):
if A[i] is true:
j <- i^2
while j <= n:
A[j] <- false
j <- j + i
return the indices of A corresponding to trueIn order to calculate the complexity of this algorithm, we should consider the outer  loop and the inner
loop and the inner  loop. It’s easy to see that the former’s complexity is
loop. It’s easy to see that the former’s complexity is  . However, the latter is a little tricky. Since we enter the loop when
. However, the latter is a little tricky. Since we enter the loop when  is prime, we’ll repeat the inner operation
is prime, we’ll repeat the inner operation  number of times, with being the current prime number. As a result, we’ll have:
number of times, with being the current prime number. As a result, we’ll have:
![\[\sqrt{n} \sum_{p<\sqrt{n}} \frac{\sqrt{n}}{p} = n \sum_{p<\sqrt{n}} \frac{1}{p} \]](/wp-content/ql-cache/quicklatex.com-d9de7b5cd06c870f4545d618a0131205_l3.svg "Rendered by QuickLaTeX.com")
In their book (theory of numbers), Hardy and Wright show that  . Therefore, the time complexity of the sieve of Eratosthenes will be
. Therefore, the time complexity of the sieve of Eratosthenes will be  .
.
This method follows the same operation of crossing out the composite numbers as the sieve of Eratosthenes. However, it does that with a different formula. Given and  less than , first we cross out all the numbers of the form
less than , first we cross out all the numbers of the form  less than . After that, we double the remaining numbers and add
less than . After that, we double the remaining numbers and add  . This will give us all the prime numbers less than
. This will give us all the prime numbers less than  . However, it won’t produce the only even prime number ().
. However, it won’t produce the only even prime number ().
Here’s the pseudocode for this algorithm:
algorithm FindPrimesSundaram(n):
// INPUT
// n = an arbitrary number
// OUTPUT
// Prime numbers smaller than n
k <- floor((n-1) / 2)
A <- an array of size k+1 with boolean values set to true
for i <- 1 to sqrt(k):
j <- i
while i + j + 2 * i * j <= k:
A[i + j + 2 * i * j] <- false
j <- j + 1
T <- the indices of A corresponding to true
T <- 2 * T + 1
return TWe should keep in mind that with as input, the output is the primes up to . So, we divide the input by half, in the beginning, to get the primes up to .
We can calculate the complexity of this algorithm by considering the outer loop, which runs for  times, and the inner loop, which runs for less than
times, and the inner loop, which runs for less than  times. Therefore, we’ll have:
times. Therefore, we’ll have:
![\[\sqrt{n} \sum_{i<\sqrt{n}} \frac{\sqrt{n}}{i} = n \sum_{i<\sqrt{n}} \frac{1}{i} \]](/wp-content/ql-cache/quicklatex.com-82379926910badca73f8b5819caf8150_l3.svg "Rendered by QuickLaTeX.com")
This looks like a lot similar to the complexity we had for the sieve of Eratosthenes. However, there’s a difference in the values can take compared to the values of in the sieve of Eratosthenes. While could take only the prime numbers, can take all the numbers between and . As a result, we’ll have a larger sum. Using the direct comparison test for this harmonic series, we can conclude that:
![\[ \sum_{i=1}}^{i=\sqrt{n}} \frac{1}{i} \geq 1 + \frac{\texttt{log\,n}}{4}\]](/wp-content/ql-cache/quicklatex.com-10c6549661275b94c35a8c8715f5f915_l3.svg "Rendered by QuickLaTeX.com")
As a result, the time complexity for this algorithm will be  .
.
Sieve of Atkin speeds up (asymptotically) the process of generating prime numbers. However, it is more complicated than the others.
First, the algorithm creates a sieve of prime numbers smaller than 60 except for  . Then, it divides the sieve into
. Then, it divides the sieve into  separate subsets. After that, using each subset, it marks off the numbers that are solutions to some particular quadratic equation and that have the same modulo-sixty remainder as that particular subset. In the end, it eliminates the multiples of square numbers and returns along with the remaining ones. The result is the set of prime numbers smaller than .
separate subsets. After that, using each subset, it marks off the numbers that are solutions to some particular quadratic equation and that have the same modulo-sixty remainder as that particular subset. In the end, it eliminates the multiples of square numbers and returns along with the remaining ones. The result is the set of prime numbers smaller than .
We can express the process of the sieve of Atkin using pseudocode:
algorithm FindPrimesAtkin(n):
// INPUT
// n = an arbitrary number
// OUTPUT
// Prime numbers smaller than n
S <- {1, 7, 11, 13, 17, 19, 23, 29, 31, 37, 41, 43, 47, 49, 53, 59}
A <- an array of size n with boolean values set to false
for x <- 1 to sqrt(n):
for y <- 1 to sqrt(n) by 2:
m <- 4 * x^2 + y^2
if (m mod 60 in {1, 13, 17, 29, 37, 41, 49, 53}) and (m <= n):
A[m] <- not A[m]
for x <- 1 to sqrt(n) by 2:
for y <- 2 to sqrt(n) by 2:
m <- 3 * x^2 + y^2
if (m mod 60 in {7, 19, 31, 43}) and (m <= n):
A[m] <- not A[m]
for x <- 2 to sqrt(n):
for y <- x - 1 to 1 by -2:
m <- 3 * x^2 - y^2
if (m mod 60 in {11, 23, 47, 59}) and (m <= n):
A[m] <- not A[m]
M <- {60 * w + s | w in {0, 1, 2, ..., n / 60} and s in S}
for m in M \ {1}:
if (m^2 > n):
break
else:
mm <- m^2
if A[m] is true:
for m2 in M:
c <- mm * m2
if (c > n):
break
else:
A[c] <- false
primes <- {2, 3, 5}
Append to primes the elements of A that are true
return primesIt is easy to see that the first three loops in the sieve of Atkin require  operations. To conclude that the last loop also runs in time, we should pay attention to the condition that will end the loop. Since when
operations. To conclude that the last loop also runs in time, we should pay attention to the condition that will end the loop. Since when  and
and  , which is a multiple of a square number, are greater than , we get out of the loops, they both run in time. As a result, the asymptotic running time for this algorithm is
, which is a multiple of a square number, are greater than , we get out of the loops, they both run in time. As a result, the asymptotic running time for this algorithm is  .
.
Comparing this running time with the previous ones shows that the sieve of Atkin is the fastest algorithm for generating prime numbers. However, as we mentioned, it requires a more complicated implementation. In addition, due to its complexity, this might not even be the fastest algorithm when our input number is small but if we consider the asymptotic running time, it is faster than others.
In this article, we reviewed some of the fast algorithms that we can use to generate prime numbers up to a given number.