Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Multithreaded Algorithms
Last updated: March 24, 2023

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Overview
In computer science, there are various parallel algorithms that can run on a multiprocessor computer, such as multithreaded algorithms.
In this tutorial, we’ll take a look at what this approach means. Then, we’ll use an example to understand it in a better way.
2. Concepts of Dynamic Multithreading
Multithreading is a crucial topic for modern computing. There exist many competing models of parallel computation that are essentially different. For example, one can have shared or distributed memory. Since multicore processors are ubiquitous, we focus on a parallel computing model with shared memory.
2.1. Dynamic and Static Multithreading
Static threading means that the programmer needs to specify how many processors to use at each point in advance. When it comes to evolving conditions, this can be inflexible.
In dynamic multithreading models, the programmer needs to specify opportunities for parallelism and a concurrency platform manages the decisions of mapping these opportunities to actual static threads.
2.2. Concurrency Constructs
A concurrency platform is a software layer that schedules, manages, and coordinates parallel-computing resources. We’ll use a simple extension of the serial programming model that reflects current parallel-computing practice:
- Spawn: Instead of waiting for the child to finish, the procedure instance that executes the spawn (the parent) may continue to execute in parallel with the spawned subroutine (the child)
- Sync: the procedure must wait for the completion of all of its spawning children. It is used when one cannot proceed without pending results
- Parallel: to indicate that each iteration can be done in parallel, we use a loop construct such as “for”
The “parallel” and “spawn” keywords do not impose parallelism. They just indicate that it is possible. This is known as logical parallelism. So, when parallelism is used, we respect “sync”. Every procedure has an implicit “sync” at the end for safety.
3. Example: Parallel Fibonacci
Let’s take a slow algorithm and make it parallel. Here is the definition of Fibonacci numbers:
![\[\begin{cases} F_{0} = 0 \\ F_{1} = 1 \\ F_{i} = F_{i-1} + F_{i-2} \text{, for } i \geq 2 \\ \end{cases}\]](/wp-content/ql-cache/quicklatex.com-b01ac532f3dde0fe0dd49de52f5d5792_l3.svg "Rendered by QuickLaTeX.com")
Here’s an algorithm (non-parallel) for computing Fibonacci numbers based on the above definition:
algorithm FIB(n):
// INPUT
// n = a non-negative integer
// OUTPUT
// The nth Fibonacci number
if n <= 1:
return n
else:
x <- FIB(n-1)
y <- FIB(n-2)
return x + yHere’s the recursion tree of the algorithm cited above:
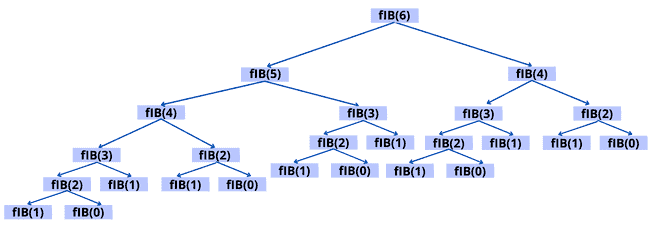
Let’s see what improvement we can get by computing the two recursive calls in parallel using the concurrency keywords:
algorithm P-FIB(n):
// INPUT
// n = non-negative integer
// OUTPUT
// The nth Fibonacci number computed in parallel
if n <= 1:
return n
else:
x <- spawn P-FIB(n-1) // parallel execution
y <- spawn P-FIB(n-2) // parallel execution
sync // wait for the results x and y
return x + y
4. Modeling Dynamic Multithreading
Let’s now look at a formal model for describing parallel computations.
4.1. Computation DAG
A computation DAG (directed acyclic graph) will be used to model a multithreaded computation  :
:
- Vertices: vertices (
 ) in the graph represent the instructions. To simplify, let’s think of each vertex as a strand (sequence of instructions containing no parallel control, such as sync, spawn, parallel, return from spawn)
) in the graph represent the instructions. To simplify, let’s think of each vertex as a strand (sequence of instructions containing no parallel control, such as sync, spawn, parallel, return from spawn) - Edges: edges (
 ) represent the dependencies between strands or instructions. An edge
) represent the dependencies between strands or instructions. An edge  in () indicates that instruction (
in () indicates that instruction ( ) must be executed before instruction (
) must be executed before instruction ( )
)
If there’s an edge between thread (a strand of maximal length will be called a thread) and they are logically in series; otherwise, they are logically parallel.
4.2. Edge Classification
Here’s a categorization of the edges:
- Continuation edge : connects a thread to its successor within the same procedure instance
- Spawn edge : is called a spawn edge when a thread spawns a new thread in parallel
- Return edge
 : when a thread returns to its calling process and
: when a thread returns to its calling process and  is the thread following the parallel control, the graph includes the return edge
is the thread following the parallel control, the graph includes the return edge
4.3. Visualization of the Model
Before moving forward to the model for the computation DAG, let’s take a look at the parallel algorithm to compute Fibonacci numbers using threads:
algorithm P-FIB(n):
// INPUT
// n = non-negative integer
// OUTPUT
// The nth Fibonacci number, with thread annotations for clarity
if n <= 1:
return n // Thread A
else:
x <- spawn P-FIB(n-1) // Thread A continues
y <- spawn P-FIB(n-2) // Thread B
sync // wait for results
return x + y // Thread C combines resultsHere’s the model for the computation DAG for P-FIB( ):
):
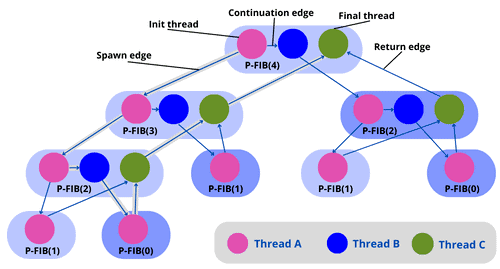
As we can see in the figure above, the purple thread in the block number spawns another purple thread in the block number  . Then the number points to the purple thread in the block number
. Then the number points to the purple thread in the block number  . The number points to the purple thread in the block number . Then we point to the green thread in the block number using the return edge. We continue pointing to the green thread in block number and until we reach the final thread.
. The number points to the purple thread in the block number . Then we point to the green thread in the block number using the return edge. We continue pointing to the green thread in block number and until we reach the final thread.
5. Measuring Dynamic Multithreading
Let’s walk through some measures and observations the characterizes dynamic multithreading.
5.1. Work
The work of a multithreaded computation is the total time required to execute the entire computation on one processor. So, the work represents the sum of the time taken by each thread.
An ideal parallel computer with  processors can perform up to units of work in a one-time step. In other words, it can do up to
processors can perform up to units of work in a one-time step. In other words, it can do up to  work in
work in  time ( is the running time of an algorithm on processors). Since the total work is
time ( is the running time of an algorithm on processors). Since the total work is  ,
,  . Hence, the work law is
. Hence, the work law is  .
.
5.2. Span
The span is the longest time it takes to execute threads along any path of the computational DAG.
An ideal parallel computer with processors cannot run faster than a machine with an infinite number of processors. A computer with an infinite number of processors, on the other hand, can imitate a processor machine by employing only of its processors. Therefore,  , which is known as the span law.
, which is known as the span law.
5.3. Speedup and Parallelism
The speedup of a computation on processors is  . So, this ratio defines how much speedup we get with the processor as compared to one. Using the work law (
. So, this ratio defines how much speedup we get with the processor as compared to one. Using the work law ( ), we can conclude that an ideal parallel computer cannot have any more speedup than the number of processors.
), we can conclude that an ideal parallel computer cannot have any more speedup than the number of processors.
The parallelism of a multithreaded computation is  . So, this ratio means the average amount of work that can be performed for each step of parallel execution time.
. So, this ratio means the average amount of work that can be performed for each step of parallel execution time.
5.4. Slackness
The parallel slackness of a multithreaded calculation performed on an ideal parallel computer with processors is defined as the parallelism by ratio:
![\[{Slackness = \frac{(\frac{T_{1}}{T_{\infty}})}{P}}\]](/wp-content/ql-cache/quicklatex.com-c5db451fc1c3e75ddeb6845b72dc53dd_l3.svg "Rendered by QuickLaTeX.com")
5.5. Performance Measure Example
Let’s use the Fibonacci example (P-FIB()). In the graph below, we use  threads ( vertices). As we can see, there are
threads ( vertices). As we can see, there are  threads on the longest path (red line in the graph).
threads on the longest path (red line in the graph).
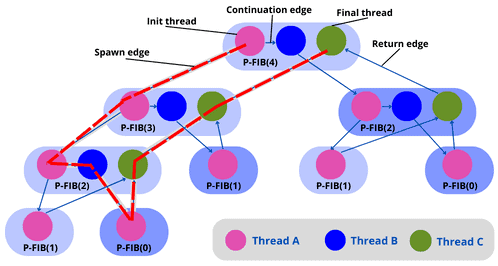
Let’s assume the unit time for each thread:
- Work: time units
- Span: time units
Let’s now take a look at the work and span of the Fibonacci computation (using the parallel algorithm above of P-FIB( )) to compute the parallelism:
)) to compute the parallelism:
- The work is simple since it computes the execution time of the serialized algorithm:
![\[{T_{1} = \theta((\frac{1+\sqrt{5}}{2})^n )}\]](/wp-content/ql-cache/quicklatex.com-fdf424a15900cb80f21c7f5f4255394c_l3.svg "Rendered by QuickLaTeX.com")
- We know that the span
 is the longest path in the computational DAG. So, P-FIB() spawns: P-FIB(
is the longest path in the computational DAG. So, P-FIB() spawns: P-FIB( ) and P-FIB(
) and P-FIB( ). Then, here’s the longest path :
). Then, here’s the longest path :
![\[{T_{\infty}(n) = max( T_{\infty}(n-1) , T_{\infty}(n-2) ) + \theta(1) = T_{\infty}(n-1) + \theta(1) \text{ which yields } T_{\infty}(n) = \theta(n)}\]](/wp-content/ql-cache/quicklatex.com-069f7a8dd1e64e71970cd1b9e5f34948_l3.svg "Rendered by QuickLaTeX.com")
- Here’s the parallelism of the P-FIB computation:
![\[{\frac{T_{1}(n)}{T_{\infty}(n)} = \theta(\frac{(\frac{1+\sqrt{5}}{2})^n )}{n}) \text{ which grows dramatically as n gets large }}\]](/wp-content/ql-cache/quicklatex.com-677842f864498e2e3cd8921782b2b13b_l3.svg "Rendered by QuickLaTeX.com")
6. Additional Examples
Let’s now use an example to understand the multithreading algorithm and its operations (parallel, spawn, sync).
6.1. Multithreaded Matrix Multiplication Algorithm
Here’s an algorithm for multithreaded matrix multiplication, using the  algorithm:
algorithm:
algorithm P-Matrix-Multiply(A, B):
// INPUT
// A, B = square matrices of size n x n
// OUTPUT
// C = the product of A and B, computed in parallel
n <- the number of rows in A
C <- initialize an empty n x n matrix
parallel for i <- 1 to n:
parallel for j <- 1 to n:
c[i, j] <- 0
for k <- 1 to n:
c[i, j] <- c[i, j] + a[i, k] * b[k, j]
return CIn this algorithm, the longest path is when spawning the outer and inner parallel loop executions, and then the executions of the innermost for loop. So, the span of this algorithm is  . Hence, the parallelism is
. Hence, the parallelism is  .
.
6.2. Multithreaded Merge Sort Algorithm
We employ divide-and-conquer algorithms for parallelism because they divide the problem into independent subproblems that can be addressed individually. Let’s take a look at merge sort:
algorithm Merge-Sort(a, p, r):
// INPUT
// a = array to sort
// p = starting index
// r = ending index
// OUTPUT
// Array a sorted in place from indices p to r
if p < r:
q <- (p + r) / 2
spawn Merge-Sort(a, p, q)
Merge-Sort(a, q+1, r)
sync // wait for parallel processes to complete
Merge(a, p, q, r)As we can see, the dividing is in the main procedure Merge-Sort, then we parallelize it by using spawn on the first recursive call. Merge remains a serial algorithm, so its work and span are  as before.
as before.
Here’s the recurrence for the work  of Merge-Sort (it’s the same as the serial version):
of Merge-Sort (it’s the same as the serial version):
![\[{T_{1}(n) = 2 \times T_{1}(\frac{n}{2}) + \theta(n) = \theta(n \times \log(n))}\]](/wp-content/ql-cache/quicklatex.com-9a37580b45bceb1eab3bf99fdd41bf3d_l3.svg "Rendered by QuickLaTeX.com")
The recurrence for the span  of Merge-Sort is based on the fact that the recursive calls run in parallel:
of Merge-Sort is based on the fact that the recursive calls run in parallel:
![\[{T_{\infty}(n) = T_{\infty}(\frac{n}{2}) + \theta(n) = \theta(n)}\]](/wp-content/ql-cache/quicklatex.com-f0c2be3fba0f8a8c87b772a2e091ced9_l3.svg "Rendered by QuickLaTeX.com")
Here’s the parallelism:
![\[{\frac{T_{1}(n)}{T_{\infty}(n)} = \theta(\frac{n \times \log(n)}{n}) = \theta(\log(n))}\]](/wp-content/ql-cache/quicklatex.com-1fbb2485be1f1bd0a557e8cf686606cf_l3.svg "Rendered by QuickLaTeX.com")
As we can see, this is low parallelism, which means that even with massive input, having hundreds of processors would not be beneficial. So, to increase the parallelism, we can speed up the serial Merge.
7. Application of Multithreading
Here are some applications of using multithreading:
- Simultaneous access to a dataset
- Web server handling new connections while still listening on a port
- Encrypting files on a background thread, while an application runs on the main thread
8. Conclusion
In this tutorial, we’ve discussed the basic concept of multithreaded algorithms using an example to unlock its mechanism. We’ve also gone over the directed acyclic graph (DAG).