

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn about generative and discriminative machine learning algorithms.
First of all, we’ll learn the definitions of generative and discriminative algorithms. Then, we’ll compare and contrast the algorithms to understand their strengths and weaknesses.
Algorithms of this type try to model “how to populate the dataset.” Sampling the model gives generated, synthetic data points.
We estimate the probability distributions. Formally, the generative model estimates the conditional probability  for a given target
for a given target  . For example, the Naive Bayes algorithm models
. For example, the Naive Bayes algorithm models  and then transforms the probabilities into conditional probabilities
and then transforms the probabilities into conditional probabilities  by applying the Bayes rule.
by applying the Bayes rule.
Some popular generative algorithms are:
Discriminative algorithms focus on modeling a direct solution. For example, the logistic regression algorithm models a decision boundary. Then it decides on the outcome of an observation based on where it stands relative to the decision boundary.
Discriminative algorithms estimate posterior probabilities. Unlike the generative algorithms, they don’t model the underlying probability distributions. Formally, we model the conditional probability of target 
 given an observation
given an observation  .
.
Some popular discriminative algorithms are:
Let’s assume our task is to determine the language of a text document. How do we solve this task with the help of machine learning?
We can learn each language and then determine the language. This is how generative models work.
Alternatively, we can learn just the linguistic differences and common patterns of languages without actually learning the language. This is the discriminative approach. In this case, we don’t speak any language.
In other words, discriminative algorithms focus on how to distinguish cases. Hence, they focus on learning a decision boundary. On the other hand, generative algorithms learn the fundamental properties of the data and how to generate it from scratch:
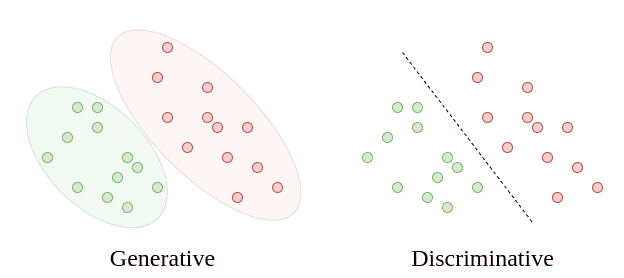
The generative approach focuses on modeling, whereas the discriminative approach focuses on a solution. So, we can use generative algorithms to generate new data points. Discriminative algorithms don’t serve that purpose.
Still, discriminative algorithms generally perform better for classification tasks. That’s because they focus on solving the actual problem directly instead of solving a more general problem first.
Yet, the real strength of generative algorithms lies in their ability to express complex relationships between variables. In other words, they have explanatory power. As a result, they have successful use cases in NLP and medicine.
On the other hand, discriminative algorithms feel like black-boxes, without the ability to express their decision boundaries in simple terms. The relationships between variables are not explicitly explainable. Therefore, we can’t visualize it easily.
Besides, generative models are suited to solve unsupervised learning tasks, as well as supervised learning tasks, since they have predictive ability. Discriminative models require labeled datasets and can’t deduce from a context. Consequently, generative models have more comprehensive applications in anomaly detection and monitoring areas.
Moreover, generative algorithms converge faster than discriminative algorithms. Thus, we prefer generative models when we have a small training dataset.
Even though the generative models converge faster, they converge to a higher asymptotic error. On the contrary, the discriminative models converge to a smaller asymptotic error. So, as the number of training examples increases, the error rate decreases for the discriminative models.
To summarize, generative and discriminative algorithms have their own strengths and weaknesses:
| Generative Model | Discriminative Model | |
|---|---|---|
| Learns | Probabilistic model | Decision boundary |
| Estimates | |
 |
| Strength | Converges faster | Smaller error |
| Explainability | Express complex relationships | Low to none |
| Examples | Naive Bayes Classifier, GAN | Linear Regression, SVM |
In this article, we’ve learned about two machine learning methods.
The generative models involve modeling, whereas the discriminative models directly focus on finding a solution.
The generative models have explanatory power and are more elegant. However, a discriminative approach usually performs better.
As usual, we need to decide on the algorithm to use based on the problem at hand.