

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: October 16, 2025
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll study the problem of the detection of emotion in a written text. In doing so, we’ll get familiar with the theoretical foundations for sentiment analysis in Natural Language Processing.
Further, we’ll point at the locations of some publicly available datasets on which we can train models for emotion detection.
At the end of this article, we’ll have a solid theoretical understanding as to when sentiment analysis functions and when it doesn’t. We’ll also know where to retrieve the datasets required to start playing with machine learning models for content analysis and emotion detection in texts.
Humans have emotions, which correspond to their mental statuses and behavioral patterns. There are two dimensions to the emotions felt by humans: an internal and an external dimension.
The internal or subjective component of emotions is the one that the individual immediately perceives. The individual can’t share this component with others, which therefore remains within that individual’s direct experience:
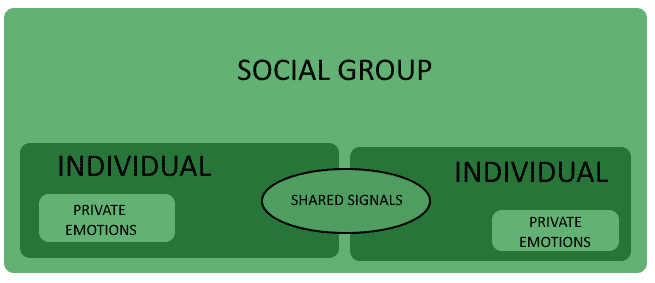
It corresponds to the psychological status of the person, but also to the activation of emotion-specific neural circuits of the brain. This internal dimension is not observable through the methodology of content analysis and it’s, for all purposes, a black box.
There’s also an external or shared dimension to emotions though. As the individual feels emotions, they share, voluntarily or not, this external component with the rest of the environment. This sharing is done by emitting signals that take the form of facial expressions; gestures; attitudes; and verbal signals, which are the focus of this article.
In that environment, surrounding the individual, live other humans who receive the signals associated with the individual’s emotions and interpret them. These signals activate analogous emotional statuses in the individual that perceives them and allow the replication of the signals in a community.
This in turn, in a decentralized and distributed manner, allows the coordination of emotional responses among individuals and the conduct of joint emotional behaviors:

If we’d just landed on this planet and knew nothing about humans, we’d still be able to learn something about emotions. We’d detect that some classes of signals tend to be diffused in human groups immediately before the conduct of some clusters of group behavioral patterns. We’d however not necessarily know what’s the subjective experience associated with a given emotional signal since we’d only perceive the external, but not the internal, dimension of the phenomenon.
This approach, the one that focuses exclusively on the external or communicative dimension of emotions, is the one that concerns Natural Language Processing. In machine learning, we can in fact observe only the shared or external dimension of emotions. In doing so, we try to infer something about the internal or private dimension of emotions, which we however never observe.
Humans differ from other mammals in the fact that the signals associated with their emotions tend to be very diversified. Most mammals are capable of emitting noises and modifying their posture, but humans can also create very articulated verbal signals which allow for the expression of more complex emotional responses:
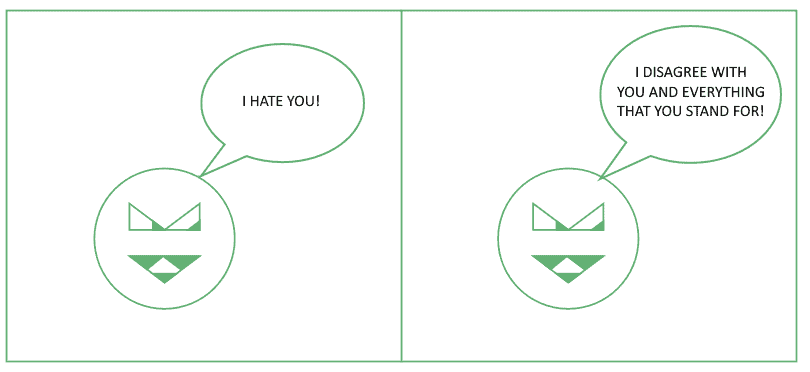
The question then becomes, how can we use these articulate responses in order to study the black box or internal component of emotions; that is, the subjective emotional status. To do this, we need an additional hypothesis that justifies the study of emotions by means of emotional signals.
The underlying hypothesis is, therefore, that some kind of unique mapping  exists, and that we can learn about it by means of machine learning.
exists, and that we can learn about it by means of machine learning.
In Natural Language Processing, we don’t observe the whole set of emotional behaviors associated with an individual. Instead, we select only a small behavioral subset, the verbal signals, and imagine that they represent well the overall emotional behavior of the individual.
In other words, we imagine that there’s a mapping  , which implies the existence of a composed function
, which implies the existence of a composed function  . If this function exists, we can then learn it by means of machine learning.
. If this function exists, we can then learn it by means of machine learning.
This function doesn’t exist. Yet, it’s a good idea to assume that it does. There are many arguments in favor of refusing the idea that the inner emotional status of an individual can be studied by analyzing their sole verbal behavior. Here we discuss the primary reasons.
The complexity of emotional signals in other primates is significantly lower than that of humans, especially because verbal signals are almost absent. At the same time, the complexity of their emotional behaviors in small groups seems to be comparable to that of small human groups. This suggests that language and emotions don’t have a perfect correspondence to one another.
The possibility to map language to emotion requires that there’s an agreed-upon ontology of emotions. This agreement doesn’t exist, and different scholars have a different understanding of what primary or base emotions exist. This, in turn, makes the association of verbal signals to emotions fuzzy.
The analysis of language through Natural Language Processing restricts itself to the syntactic analysis of words and sentences. Semantic analysis, the one required for human-like understanding of language, is not yet solvable through machine learning.
For these reasons, even if the composed function  described above existed, there are good reasons to refuse the idea that machine learning can work with it. Are we lost then, and do we need to drop the idea of working with emotions through computer methods?
described above existed, there are good reasons to refuse the idea that machine learning can work with it. Are we lost then, and do we need to drop the idea of working with emotions through computer methods?
Most of the emotional responses of humans are simple and stereotypical. This means that, if we can learn what signals are produced by humans in response to a given emotional status, this same signal will likely be used in future situations, where the same emotional status will be experienced. This is because words, the verbal signals, don’t change their meaning frequently or rapidly.
The reason why natural languages generally stay unchanged for decades is that they map well the relationship between syntactic value and semantic meaning of words. While words may change their meaning, they do so slowly enough that their capacity to map internal states of the individuals doesn’t change in the short term.
Furthermore, while humans have the capacity to reassign meaning to words “on-the-go”, they generally don’t do that often. If a word is used in association with a given emotion in one context, that word will generally be associated with the same emotion in any other context. Examples of this are:
In these examples, there is a bijective correspondence between words and emotions.
In those three sentences, we can generally assume that the word “happy” refers to the same emotional status, even though its context is wildly different. Examples against this idea also however exist:
In these three sentences, the word “sad” is the same unique verbal signal, associated with three different emotions felt by the speakers. We can immediately understand that no unique correspondence between words and emotions exists in this case. If such a correspondence doesn’t exist, then machine learning obviously can’t learn it.
Natural languages are open systems, which means that we can’t aprioristically enumerate the possible elements (say, sentences) in a given language. On the contrary, we know it’s possible to construct an unlimited number of sentences, by chaining them appropriately.
This means that we can’t ever solve the problem of determining through a reductionist approach what relationship exists between words and sentiments. It also means that, in order to work with them, we assume that there is some kind of correspondence between words and sentiments which we know in practice to be fuzzy at best, or simply and plainly wrong.
We can now sum-up the conditions and preliminary hypotheses enumerated above. There are some assumptions that our system must respect before we’re able to perform the detection of emotions in texts.
The first assumption is that there’s a function that maps the relationship between words or sentences and emotions. We also imagine this function to be surjective or bijective.
We imagine that words and their meanings do not change over time. This allows the comparison between words and sentences, and their associated emotions, over prolonged periods.
We lastly imagine that there’s a general agreement about what classes of emotions exist, and presume that all humans would agree on the emotional labels to associate to any given word or words.
Scientists believe or suspect these assumptions to be false. However, some heuristics and tricks, and some special situations, allow us to preserve them and thus conduct sentiment analysis.
We can impose the assumption that emotions are stereotypically simple and that the ways to express them are limited. This is the case if, for instance, we assume that the emotions in a text are exceedingly simple; such as “positive” or “negative”, but not much more complex than that.
We can presume that language doesn’t change, and neither does the meaning of words. This is true if we study corpora which are collected over a relatively short period of time; say, a decade or two, in a very homogeneous human population.
We can assume that any random individual would generally agree on the emotional labels associated with any given sentence or word. This is the most problematic assumption. It’s believed that emotion detectors learn the individual-specific criteria to tag sentiments in texts, but don’t generalize well from one human tagger to the next.
If we assume all of that, we can then build systems for the detection of emotions in texts. The way to do it is to conduct text classification on a labeled corpus or parts thereof. In doing so, a machine learning algorithm can be trained to learn the association between documents and labels, or words and tags.
The development of a system for the detection of emotions starts with the identification of a labeled dataset. This dataset must respect the specific set of assumptions we decided to adopt for our system. Let’s see here the most common ones, and identify the tasks for which we can use them:
Any of the datasets indicated here are equally suitable for the initial introduction to the topic of sentiment analysis. The real-world implementation of machine learning systems for emotion detection will, however, require a more complex approach. It will in fact need to take into account the finality for which the identification of emotions matters.
It’s rarely the case that we want to just identify emotions in texts. Rather, we normally want to learn about user preferences or predict behavior on the basis of their emotional responses.
This latter task relies only partially on the identification of emotional values in texts. This means that sentiment analysis is often a small part of a larger system that models user preferences and behaviors. If we’re building one, we thus often have to complement sentiment analysis with other machine learning techniques.
However, sentiment analysis by itself also serves an important function. Real-world systems for emotion detection can be used to identify clusters of texts with analogous emotional values so that human analysts can be asked to extract actionable insights from them. That’s useful if we want to understand the reasons for negative feedbacks to our products in terms of user experiences.
In this article, we’ve studied the theoretical foundations of the problem of emotion detection in texts. We’ve first seen what is the relationship between emotions and communications in humans; then we’ve learned how words are only part of the emotional responses of individuals.
We’ve also discussed how the subjective emotional experience can only partially be studied through the analysis of language. In doing so, we’ve also identified under what conditions analysis of sentiments in texts is possible. These conditions include the assumption of a surjective function between words or sentences and emotions, the immutability of language, and the sharing among individuals of emotional labels associated with words and sentences.
Lastly, we’ve enumerated publicly available datasets for the classification of texts, and in particular for the identification of emotions. These datasets are accessible to all and allow us to train basic models for sentiment analysis.