Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: November 9, 2022

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Although we often think of microservices as completely independent and self-contained units, this isn’t always the case. Sometimes it’s more convenient to think at a system level and lose some of that autonomy.
Let’s dive into these cross-cutting concerns and find out what they are.
One of the first things to consider is how security is involved in this architectural style. Microservices architecture is, by its nature, more distributed than other patterns. The calls between components are larger and we must pay particular attention to policies aimed at preserving the security of data at rest, in transit, and use.
Given this nature, the most vulnerable parts are API. Building an API Gateway becomes advantageous as it acts as a single point of entry for calls coming from outside. In this way, it’s possible to reduce the attack surface, through appropriate whitelists, thus preventing potential attacks from malicious actors.
Securing endpoints is critical. For this reason, we must also explore the themes of Authorization and Authentication. Nowadays, the de facto standard for managing authorization is OAuth / OAuth2 flows. On the other hand, the two-factor authentication helps to prevent and detect unwanted and malicious accesses for the authentication part.
Microservice Configuration Management concerns the change tracking process of the microservices themselves and the applications that consume them. In a microservice architecture, changes to a single microservice potentially impact the entire architecture. This means that it can potentially impact every consumer.
That said, we must track the deployment of all microservices and their configurations. In this way, by also adding all the surrounding elements (e.g. Kubernetes cluster, info relating to the infrastructure that hosts them), we can have the complete picture in the game.
Let’s imagine we’ve hundreds or thousands of microservices running in our clusters: we need a centralized place where all microservices can take their specific configuration, also based on the environment they’re running on.
Logging is an important part of software applications, letting us know what the code did when it ran. It gives us the ability to see when things are executing as expected and, perhaps more importantly, helps us to diagnose problems when they aren’t.
Having a microservices architecture leads to having several microservices running on the infrastructure. We may also have several instances of the same microservice. Each microservice writes its own logs in a standard format and contains info, warnings, errors, and debug messages.
Due to its innate separation of concerns, we often need to involve multiple microservices in these kinds of systems to fulfill a single request.
This creates the need to collect and aggregate logs from across all microservices and, secondly, to have a mechanism that allows correlating all the internal calls necessary to observe the entire journey request:
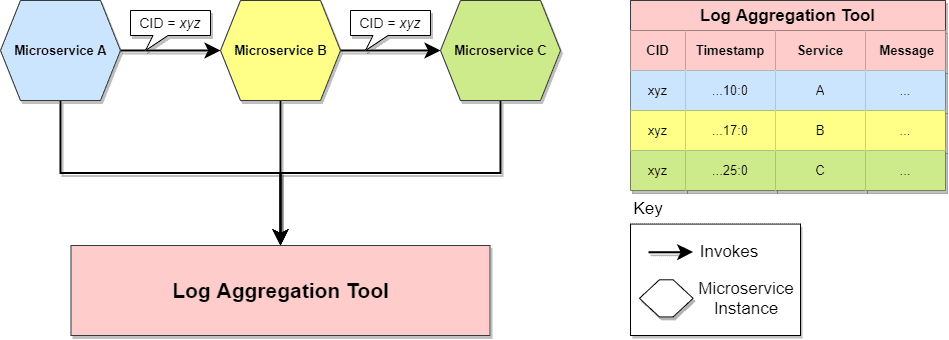
These log aggregation tools leverage Correlation IDs (CID) and we use a single ID for a related set of service calls. For example, the chain of calls that might be triggered as a result of a client request. By logging this ID as part of each log entry helps to isolate all the logs associated with a given call flow, making troubleshooting much simpler.
Elasticity and reliability are two of the -ilities that microservices are best able to support.
A microservices-based application typically runs in virtualized or containerized environments. The number of instances of a service and its locations change dynamically. This is where tactics such as Service Discovery and Load Balancing come into play. We need to know where these instances are and their names to distribute incoming calls from outside.
We can imagine Service Discovery as a Service Registry that keeps track of the location and name of each instance. In short, when a new instance is served and is ready to accept requests, it communicates its readiness to the designated node. The latter monitors the situation of all instances present, e.g., via ping/echo or heartbeat tactics.
On the other hand, load balancing is when we need to distribute the load to one of several instances based on an algorithm, removing instances when they are no longer healthy and putting them back on when they come back up. Other useful features can be for example SSL Termination to manage data security in transit of incoming call traffic and between microservices:
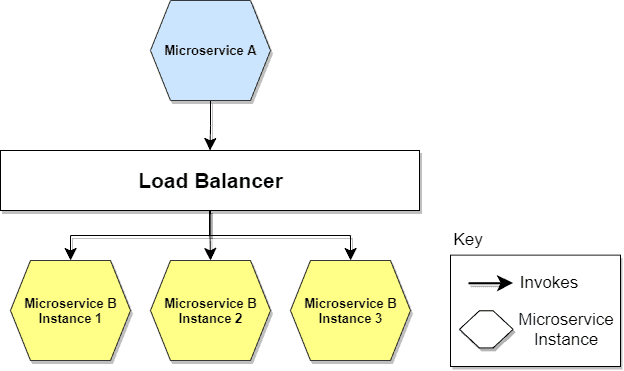
Both Service Discovery and Load Balancing are provided by tools such as Service Mesh or orchestration systems such as Kubernetes.
DRY (Don’t Repeat Yourself) is what leads us to create reusable code. In general, it makes sense. An evergreen topic when it comes to microservices is whether or not to use shared libraries. Of course, just because it can be done doesn’t mean it’s right to do it.
The first point is that if we’re talking about sharing code, we’re reducing the freedom to have heterogeneous technologies. A Java Shared Library can influence us to build other Java-based microservices. This isn’t necessarily a con, but it should be emphasized.
Basically, implementing microservices means sharing responsibilities and reducing coupling. Introducing shared libraries goes against the main philosophy of this architectural style. It’s important to understand why we want to introduce a shared library. If we’ve applied techniques such as DDD correctly, we’ll have a very cohesive and poorly coupled architecture. We would like to preserve these concepts.
When we’ve got a shared library within our microservices, we must accept that a change to its code forces us to redistribute those microservices, undermining one of the fundamental properties of microservices: independent deployability.
This property is best preserved if we don’t want to increase deployment complexity or, taken to the extreme, find ourselves dealing with a distributed monolith.
Sharing code in microservices isn’t necessarily always wrong, but definitely something to think twice about.
The Sidecar Pattern is perhaps the most cross-cutting concern of all. When we talk about microservice architectures, we also talk about the possibility of having a polyglot system. In other words, we’ve got the freedom to choose the language, technology, or framework based on the task we need to solve.
This leads, potentially, to having microservices that speak different languages making it more difficult to maintain cross-cutting libraries of concern.
One solution to this is the sidecar pattern. The logic for cross-cutting concerns is placed in its own processor container (known as a sidecar container) and then linked to the primary application. Similar to how a motorcycle sidecar is connected to a motorcycle, the sidecar application is connected to the primary application and runs alongside it:
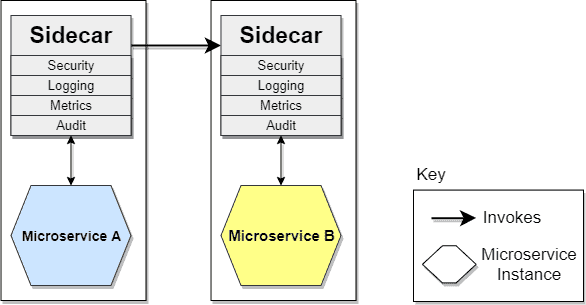
The sidecar application can then deal with concerns such as logging, monitoring, authorization and authentication, and other cross-cutting concerns. In this way, each microservice would have its sidecar instance equal to the other microservices, thereby increasing cross-cutting concerns maintainability and management.
This article went over some of the more interesting and useful cross-cutting concerns related to Microservices Architecture. As we have seen, we can decide to create reusable implementations to use in many microservices or implement such concerns in each microservice. In the case of the former, we create coupling between microservices, while the latter will require some extra effort. Depending on the context of our system it will be necessary to choose the right tradeoff.