

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’re going to present the MapReduce algorithm, a widely adopted programming model of the Apache Hadoop open-source software framework, which was originally developed by Google for determining the rank of web pages via the PageRank algorithm.
MapReduce is capable of expressing distributed computations on large data with a parallel distributed algorithm using a large number of processing nodes. Each job is associated with two sets of tasks, the Map and the Reduce, which are mainly used for querying and selecting data in the Hadoop Distributed File System (HDFS).
First of all, key-value pairs form the basic data structure in MapReduce. The algorithm receives a set of input key/value pairs and produces a set of key-value pairs as an output. In MapReduce, the designer develops a mapper and a reducer with the following two phases:
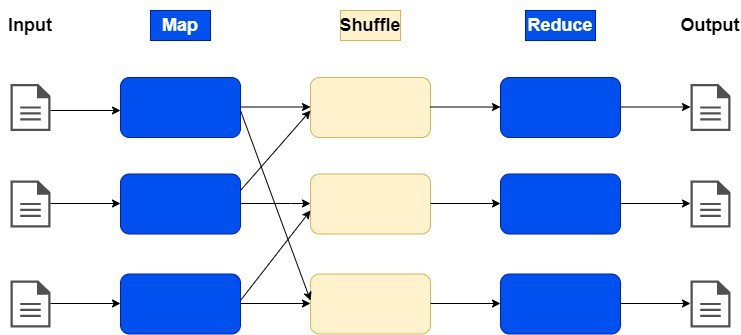
The order of operations: Map|Shuffle|Reduce
The first phase of MapReduce takes an input pair and produces a set of intermediate key-value pairs (key_1, value_1)  [(k_2, v_2)]. The MapReduce library groups together all intermediate values associated with the same intermediate key
[(k_2, v_2)]. The MapReduce library groups together all intermediate values associated with the same intermediate key  and passes them to the reduce function:
and passes them to the reduce function: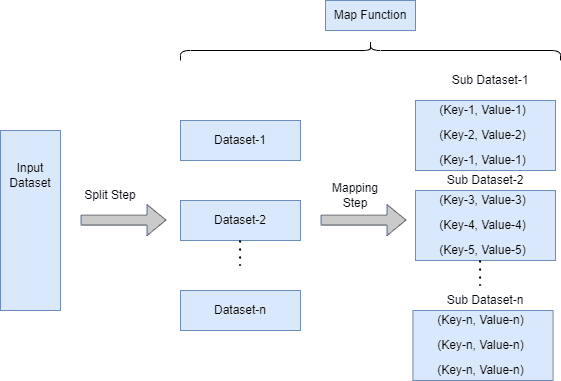
The second phase of MapReduce receives an intermediate key and a set of values for that key as an input and reduces the data to a simplified form (key_2, [value_2])[(k_3, v_3)]. It combines and merges these values to form a possibly smaller set of values and performs a reduce operation. An iterator is supplied to the reduce function corresponding to the in-between values:
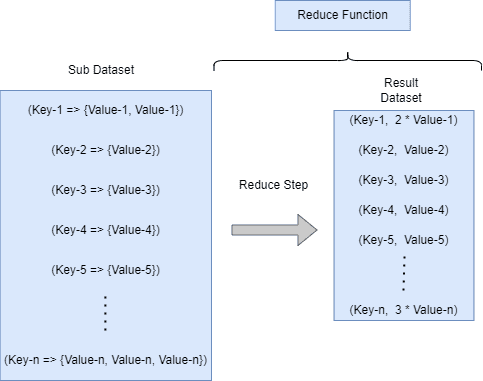
When the reduce phase is completed successfully, the results are sent to the Hadoop server.
A MapReduce program includes code for mappers and reducers along with configuration parameters (such as the location and storage information of the input). The developer submits the job to a node of a cluster, and the execution framework handles the rest.
Specific jobs of MapReduce include:
Typical database servers face too many bottlenecks and struggle when dealing with massive amounts of data. Also, several data-intensive works suffer from bottlenecks caused by the separation of compute and storage nodes, even if the work that needs to be done is not very processor-demanding. This problem is overcome by using the MapReduce algorithm, which assigns tasks to different nodes and handles every job independently.
In addition, the distributed file system improves the performance of the executions as it is responsible for organizing the computations so that data is processed sequentially on different nodes and avoiding random data accesses.
Typical problems/examples that involve the MapReduce algorithm are:
We consider the problem of counting the number of occurrences of each word in a large collection of documents. The pseudo-code of this problem:
function Map(docid, doc):
// INPUT
// docid = document identifier
// doc = the content of the document
// OUTPUT:
// Emits key-value pairs where
// key is a term and
// value is the count 1
for term in doc:
EMIT(term, 1)
function Reduce(term, [c1, c2, ...]):
// INPUT
// term = a unique term from the document
// counts = list of counts of occurrences of the term
// OUTPUT
// Emits key-value pair where
// key is the term and
// value is the total count of occurrences of that term
sum <- 0
for c in [c1, c2, ...]:
sum <- sum + c
EMIT(term, sum)Initially, the mapper produces a key-value <docid, doc> pair for every word. Every word works as the key, and the integer works as the value frequency. Then, the reducer sums up all counts that are associated with every single word and creates the desirable key pair.
In this article we introduced MapReduce, a widely used algorithm due to its capability of handling big data effectively and achieving high levels of parallelism in cluster environments. The ability to process terabytes of data concurrently and accelerate certain algorithms has led this algorithm to gain strong popularity and be widely applied in companies that handle large and complex data.