

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll delve into the intricacies of Linear Discriminant Analysis (LDA).
Dimensionality reduction simplifies datasets by reducing dimensions and categorizing them into unsupervised and supervised approaches.
Unsupervised methods like principal component analysis (PCA) and independent component analysis (ICA) don’t require class labels, offering versatility. Supervised approaches like mixture discriminant analysis (MDA), neural networks (NN), and linear discriminant analysis (LDA) integrate class labels. Our focus is on LDA.
LDA is a powerful dimensionality reduction technique. It seeks to transform our data into a lower-dimensional space, enhancing class separability while minimizing within-class variance:
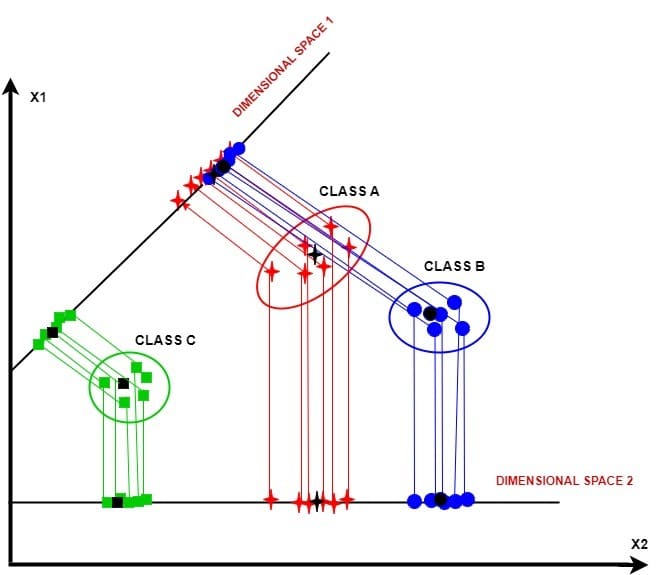
We observe three data clusters: class A, class B, and class C. Projecting along dimensional space 1 reduces within-class variance but loses between-class variance for classes A and B. Dimensional space 2 maintains both variances. Thus, we discard space 1 and use space 2 for LDA.
In tackling dimensionality reduction with LDA, we divide the process into three main steps.
The figure below illustrates these steps visually:
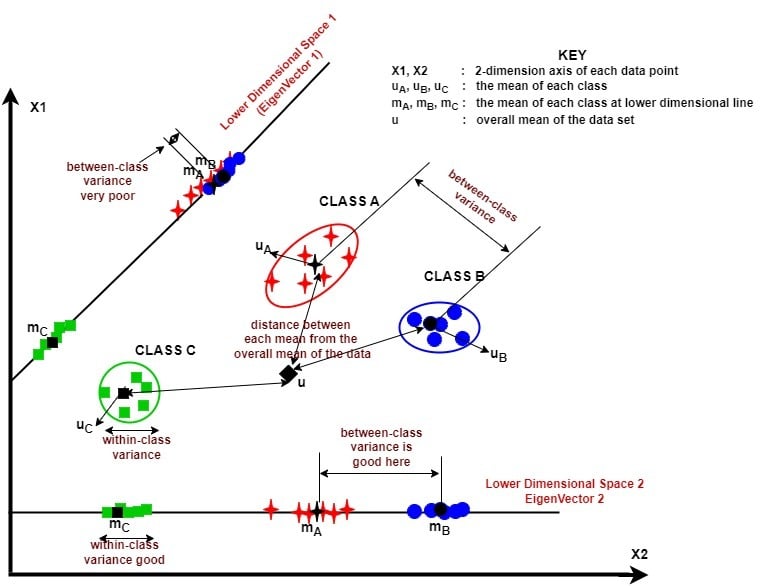
This newly constructed space simplifies our data and strengthens its power to distinguish between classes.
Exploring LDA, we encounter class-dependent and class-independent approaches. In class-dependent LDA, each class gets its own lower-dimensional space. Conversely, class-independent LDA treats each class separately but shares one lower-dimensional space.
In this section, we discuss the mathematical process for performing LDA.
To calculate the between-class variance  , we follow the following steps:
, we follow the following steps:
We first calculate the separation distance  as follows:
as follows:
(1) 
where,  represents the projection of the mean of the
represents the projection of the mean of the  class which we calculate as follows:
class which we calculate as follows:
 .
.
 is the projection of the total mean of classes which we calculate as follows:
is the projection of the total mean of classes which we calculate as follows:
 ,
,
where  represents the transformation matrix of LDA,
represents the transformation matrix of LDA,  represents the mean of the class and we calculate it as follows,
represents the mean of the class and we calculate it as follows,
 .
.
 is the total mean of all classes which we calculate as follows:
is the total mean of all classes which we calculate as follows:
 ,
,
where  is the total number of classes.
is the total number of classes.
The term  in equation 1 represents the between-class variance
in equation 1 represents the between-class variance  of the class.
of the class.
We substitute into equation 1 as follows:
(2) 
We now obtain the total between-class variance as follows:
(3) 
To calculate the between-class variance  , we take the following steps:
, we take the following steps:
The within-class variance of the class  is the difference between the mean and the samples of that class.
is the difference between the mean and the samples of that class.
We then search for a lower-dimensional space to minimize the difference between the projected mean  and the projected samples of each class
and the projected samples of each class  , which is the within-class variance.
, which is the within-class variance.
We capture these steps with the equations as follows:
(4) 
From equation 4, we calculate the within-class variance as follows;
 =
=  =
=  ,
,
where  represents the
represents the  sample in the class and
sample in the class and  is the centring data of the class, i.e.
is the centring data of the class, i.e.
=  =
=  .
.
To calculate the total within-class variance of our data, we sum up the within-class variance of all classes present in our data as follows;
=  =
=  +
+  + … +
+ … +  .
.
To transform the higher dimensional features of our data into a lower dimensional space, we maximize the ratio of to to guarantee maximum class separability by using Fisher’s criterion  , which we write this way:
, which we write this way:
(5) 
To calculate the transformation matrix , we transform equation 5 into equation 6 as follows:
(6) 
where  represents the eigenvalues of the transformation matrix
represents the eigenvalues of the transformation matrix
Next, we transform equation 6 into equation 7 as follows:
(7) 
we can then calculate the eigenvalues  and their corresponding eigenvectors
and their corresponding eigenvectors  of given in equation 7.
of given in equation 7.
In LDA, eigenvectors determine the direction of the space, while eigenvalues indicate their magnitude. We select the  highest eigenvalue eigenvectors to form a lower dimensional space
highest eigenvalue eigenvectors to form a lower dimensional space  , neglecting others. This reduces our original data
, neglecting others. This reduces our original data  from dimension
from dimension  to . We write this new dimensional space
to . We write this new dimensional space  as:
as:
(8) 
Here, we describe the slight difference between the class-independent and class-dependent LDA approaches and also provide the algorithms for both.
In the class-independent method, we use only one lower-dimensional space for all classes. Thus, we calculate the transformation matrix  for all classes, and we project the samples of all classes on the selected eigenvectors.
for all classes, and we project the samples of all classes on the selected eigenvectors.
Here is the algorithm for the class-independent LDA approach:
In class-dependent LDA, we compute distinct lower-dimensional spaces for each class using  . We find eigenvalues and eigenvectors for each separately, then project samples onto their respective eigenvectors.
. We find eigenvalues and eigenvectors for each separately, then project samples onto their respective eigenvectors.
We provide the algorithm for the class-dependent LDA approach as follows:
In this section, we provide the computational complexities of the two classes of LDA
In analyzing the computational complexity of class-dependent LDA, we consider various steps. First, computing the mean of each class has complexity  . Second, calculating the total mean has complexity
. Second, calculating the total mean has complexity  . Third, computing within-class scatter involves
. Third, computing within-class scatter involves  . Fourth, calculating between-class scatter has complexity
. Fourth, calculating between-class scatter has complexity  . Fifth, finding eigenvalues and eigenvectors involves
. Fifth, finding eigenvalues and eigenvectors involves  . Sorting eigenvectors is
. Sorting eigenvectors is  . Selecting eigenvectors is
. Selecting eigenvectors is  . Finally, projecting data onto eigenvectors is
. Finally, projecting data onto eigenvectors is  . Overall, class-independent LDA has complexity
. Overall, class-independent LDA has complexity  for
for  , otherwise .
, otherwise .
In analyzing computational complexity, both class-dependent and class-independent LDAs follow similar steps. However, class-dependent LDA repeats the process for each class, increasing complexity. Overall, class-dependent LDA complexity is  for , or
for , or  , surpassing class-independent LDA in complexity.
, surpassing class-independent LDA in complexity.
In this section, we will present a numerical example explaining how to calculate the LDA space step by step and how LDA is used to discriminate two different classes of data using the class-independent and class-dependent approach.
The first class  is a
is a  x
x  matrix with the number of samples
matrix with the number of samples  . The second class
. The second class  is a
is a  x matrix with
x matrix with  . Each sample in both classes has two features (i.e.,
. Each sample in both classes has two features (i.e.,  ) as follows:
) as follows:
 , and,
, and,  .
.
First, we calculate the mean  for each class, and then the total mean for both classes. The resulting answers are as follows;
for each class, and then the total mean for both classes. The resulting answers are as follows;
 ,
,  , and
, and  .
.
Next, we calculate the between-class variance  of each class, and the total between-class variance of the given data, as follows:
of each class, and the total between-class variance of the given data, as follows:
 , so that,
, so that,

similarly,
 , so that,
, so that,

becomes,
 .
.
Next, we calculate the within-class variance . To do this, we perform the mean-centering data process by subtracting the mean of each class from each sample in that class. We achieve this as follows:  . Where is the mean-centering data of the class
. Where is the mean-centering data of the class  . The values of
. The values of  and
and  becomes:
becomes:
 , and
, and  .
.
In the next two sub-sections, we’ll present how the two LDA approaches solve this numerical example.
In this approach, after the data centering process, we calculate the within-class variance  as follows:
as follows:  . The values of is as follows:
. The values of is as follows:
 , and
, and  .
.
becomes,
 .
.
 .
.
Next, we calculate the transformation matrix as follows:  . The values of
. The values of  are
are  . The values of the transformation matrix become;
. The values of the transformation matrix become;
 .
.
We then calculate the eigenvalues and eigenvectors  from . Their values are as follows:
from . Their values are as follows:
 , and
, and 
Next, we project and onto the first column vector ![V^{[1]}](/wp-content/ql-cache/quicklatex.com-994aac57e28274035a885a5b54f88f96_l3.svg "Rendered by QuickLaTeX.com") and the second column vector
and the second column vector ![V^{[2]}](/wp-content/ql-cache/quicklatex.com-5c9306e021474cd742f126fe35f6b1fc_l3.svg "Rendered by QuickLaTeX.com") of the matrix to investigate which of the columns is more robust in discriminating the data.
of the matrix to investigate which of the columns is more robust in discriminating the data.
Using , we project on the lower dimensional space as follows:
![y_1 = w_1V^{[1]}](/wp-content/ql-cache/quicklatex.com-9c56593b5d940fc544af5b7e048cba49_l3.svg "Rendered by QuickLaTeX.com") ,
,

Using the same eigenvector , we project on the lower dimensional space as follows:
![y_2 = w_2V^{[1]}](/wp-content/ql-cache/quicklatex.com-a0cfd2de6a0889946dbfe0127be4db6d_l3.svg "Rendered by QuickLaTeX.com") ,
,
 .
.
Next, we project and to eigenvector as follows:
![y_1 = w_1V^{[2]}](/wp-content/ql-cache/quicklatex.com-586b91b43831905ac7e7218ada44f12b_l3.svg "Rendered by QuickLaTeX.com") ,
,

and
![y_2 = w_2V^{[2]}](/wp-content/ql-cache/quicklatex.com-6ca7da2569c6c119b8dec520292aade6_l3.svg "Rendered by QuickLaTeX.com") ,
,
 .
.
From our results, we observe that is more robust in discriminating the classes and than . This is because ![\lambda^{[2]}](/wp-content/ql-cache/quicklatex.com-a79bad39edbb2f53b8feb68a5de01250_l3.svg "Rendered by QuickLaTeX.com") is larger than
is larger than ![\lambda^{[1]}](/wp-content/ql-cache/quicklatex.com-531fbf4d8b9ff163ecc911f4d0d4c05b_l3.svg "Rendered by QuickLaTeX.com") . Hence, we choose to discriminate and instead of .
. Hence, we choose to discriminate and instead of .
In this approach, we aim to calculate a separate transformation matrix for each class . The within-class variance for each class is the same as we calculated it in the class-independent approach, we then calculate of each class as follows: . The values of  and
and  becomes:
becomes:

 , and
, and

 .
.
Next, we calculate the eigenvalues  and the corresponding eigenvectors
and the corresponding eigenvectors  of each transformation matrix .
of each transformation matrix .
The values of  and
and  of for are as follows:
of for are as follows:
 , and the corresponding eigenvectors are;
, and the corresponding eigenvectors are; 
Similarly,the values of the eigenvalues  and the corresponding eigenvectors
and the corresponding eigenvectors  of for the second class data are as follows:
of for the second class data are as follows:
 , and the corresponding eigenvectors are;
, and the corresponding eigenvectors are;  .
.
From the results above, we observe that ![V_{w1}^{[2]}](/wp-content/ql-cache/quicklatex.com-7f748532baaf9e6f1a4a3af15ad6b299_l3.svg "Rendered by QuickLaTeX.com") of for has a bigger corresponding eigenvalue than
of for has a bigger corresponding eigenvalue than ![V_{w1}^{[1]}](/wp-content/ql-cache/quicklatex.com-e563190411faa57d9f3a41c01590824d_l3.svg "Rendered by QuickLaTeX.com") , this implies that will discriminate better than the , thus, we chose as the lower dimensional space to project as follows;
, this implies that will discriminate better than the , thus, we chose as the lower dimensional space to project as follows;
![y_1 = w_1V_{w1}^{[2]}](/wp-content/ql-cache/quicklatex.com-5a0cb711c94c0b54d6f1973f96946e68_l3.svg "Rendered by QuickLaTeX.com")
 .
.
For the second class , we also see that the second column eigenvector ![V_{w2}^{[2]}](/wp-content/ql-cache/quicklatex.com-cf129c38c8a65738c29e7895ffef15b0_l3.svg "Rendered by QuickLaTeX.com") of has a higher eigenvalue than the first column eigenvector
of has a higher eigenvalue than the first column eigenvector ![V_{w2}^{[1]}](/wp-content/ql-cache/quicklatex.com-8ac56c0b1d8e63dd2969c765f09809d9_l3.svg "Rendered by QuickLaTeX.com") , this also implies that will discriminate better than the . We obtain the projected data
, this also implies that will discriminate better than the . We obtain the projected data  for as follows;
for as follows;
![y_2 = w_2V_{w2}^{[2]}](/wp-content/ql-cache/quicklatex.com-369a753a1b9619d4a0ecd66d9496b733_l3.svg "Rendered by QuickLaTeX.com")
 .
.
In the next sub-section, we present the visual illustration of the performance of LDA on the two classes of data and and then draw our conclusions.
First, let us consider the class-independent LDA approach.
The next figures illustrate the probability density function (pdf) graphs of the projected data  and on the two eigenvectors and of matrix :
and on the two eigenvectors and of matrix :
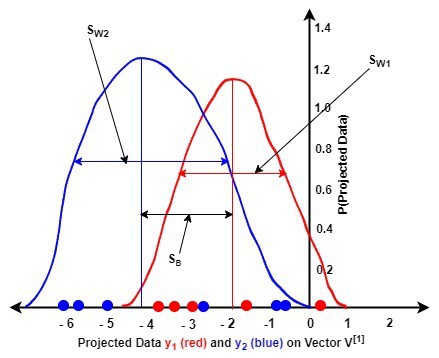
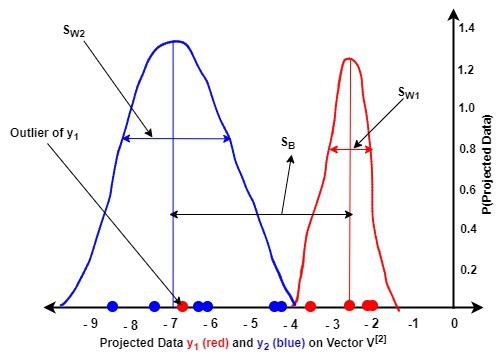
A comparison of the two figures reveals the following:
(second figure) showed a better discrimination of the data of each class than (first figure). This means that maximizes the between-class variance than minimized the within-class variance of the data of both classes than in the second figureLet us investigate the class-dependent LDA approach:
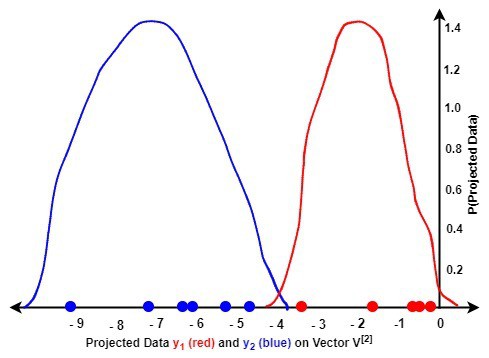
We observe that by projecting onto of the first eigenvector and onto of the second eigenvector, we were able to discriminate the data efficiently. The corresponding eigenvectors achieved this by maximizing and minimizing of the data.
8. Conclusion
In our article, we explored linear discriminant analysis (LDA) through class-independent and class-dependent approaches. Our analysis revealed that while the class-dependent method is efficient, it demands more computational time than the class-independent approach. Consequently, the class-independent approach is commonly favoured as the standard method for LDA.

