

Yes, we're now running our only Summer Sale. All Courses are 30% off until 20th July, 2026:
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
1. Introduction
In this tutorial, we’ll talk about tree isomorphism and how to check if two trees are isomorphic.
2. Tree Isomorphism
Since trees are connected acyclic graphs, tree isomorphism is a special case of graph isomorphism.
The word isomorphism means the same shape. So, intuitively, we say that two trees are isomorphic if they have the same structure.
How do we prove isomorphism? We can redraw one tree to take the same shape as the other and match their nodes. For instance:
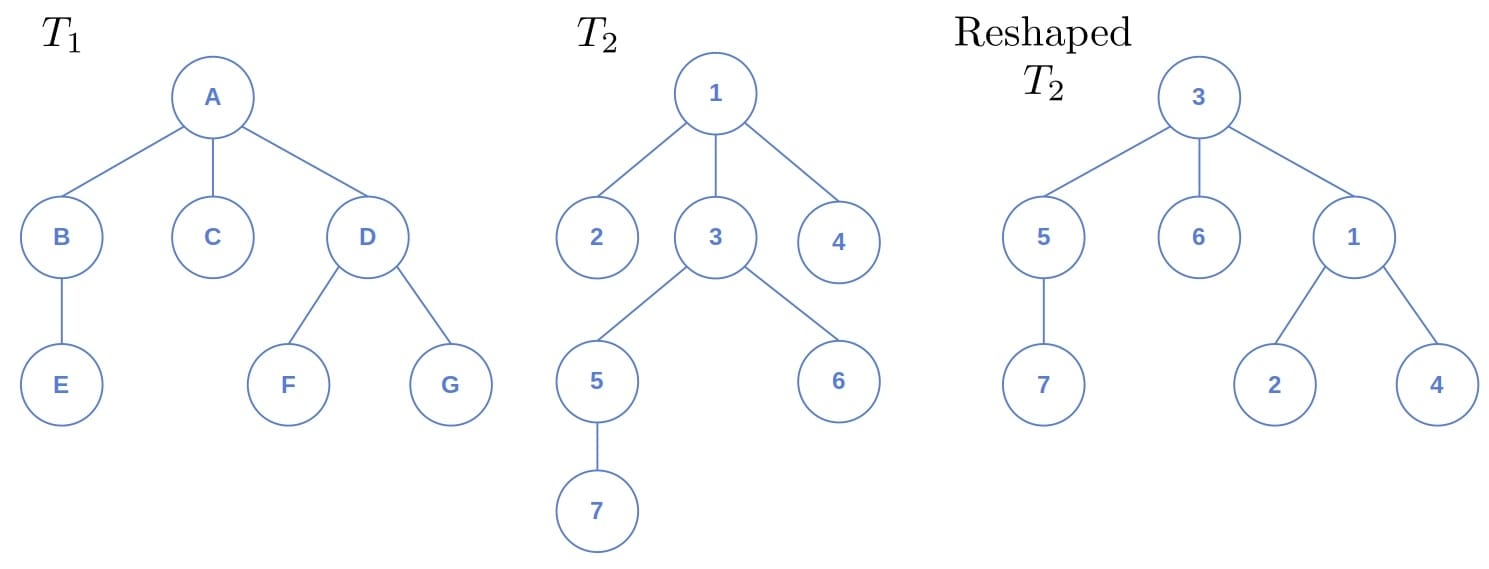
That, however, isn’t always easy to do by hand, so we need an efficient algorithm and a precise definition of isomorphism.
2.1. Mathematical Definition
We can define isomorphism rigorously. Let  and
and  be two trees, where
be two trees, where  and
and  denote their nodes, and
denote their nodes, and  and
and  their edges.
their edges.
We say that  and
and  are isomorphic if there exists a bijection
are isomorphic if there exists a bijection  such that any two nodes
such that any two nodes  are adjacent in if and only if they’re adjacent in :
are adjacent in if and only if they’re adjacent in :
![\[(u, v) \in E_1 \iff (f(u), f(v)) \in E_2\]](/wp-content/ql-cache/quicklatex.com-e8ef185c3c03a8182219abdca892fe6a_l3.svg "Rendered by QuickLaTeX.com")
We call such a mapping  the isomorphism of
the isomorphism of  and
and  .
.
Although we didn’t call it that way, we formulated the following isomorphism by reshaping in the previous example:
![\[\begin{pmatrix} u & 1 & 2 & 3 & 4 & 5 & 6 & 7\\ f(u)& D & F & G & A & B & C & E\\ \end{pmatrix}\]](/wp-content/ql-cache/quicklatex.com-c167bd132587a06acf70447d5108c8ad_l3.svg "Rendered by QuickLaTeX.com")
3. Encoding
The idea is to encode each tree so that only the nodes of the trees sharing the same structure have the same encoding.
3.1. AHU Encoding
We’ll use a variation of the AHU (Aho, Hopcroft, Ullman) encoding scheme. It maps nodes to strings representing the structures of their subtrees.
If the node  is a leaf, its AHU encoding
is a leaf, its AHU encoding  is just the symbol 0.
is just the symbol 0.
In contrast, let be a non-leaf node and  its children. Its encoding is the string containing its children’s encodings in the non-descending order:
its children. Its encoding is the string containing its children’s encodings in the non-descending order:  where
where  .
.
Finally,  .
.
For example:
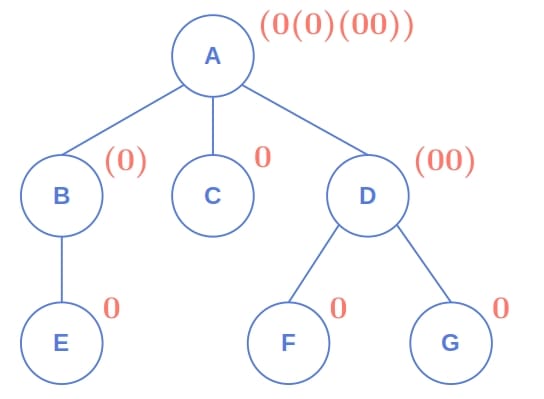
3.2. Pseudocode
Here’s the pseudocode:
algorithm AHUEncoding(T):
// INPUT
// T = a tree
// OUTPUT
// The AHU encoding of T
D <- make a dictionary mapping each level to the nodes at it
// Let h be the tree's height and root's level be 1
for u in D[h]:
AHU(u) <- '0'
k <- h - 1
while k >= 1:
for u in D[k]:
if u is a leaf:
AHU(u) <- '0'
else:
AHU(u) <- '(' + sort the AHU codes of the children of u non-decreasingly + ')'
k <- k - 1
return AHU(T.root)Before we start encoding the nodes, we first need to traverse the tree to assign each node its level so that we can iteratively compute the AHU strings starting from the bottom. Using the postorder traversal, we can get the levels in time linear in the number of nodes.
4. Checking for Isomorphism
Now, we can extend the AHU encoding algorithm to isomorphism testing.
4.1. Root
If and are isomorphic, they’ll have the same AHU encoding only if their roots are at the same place in their shared structure:
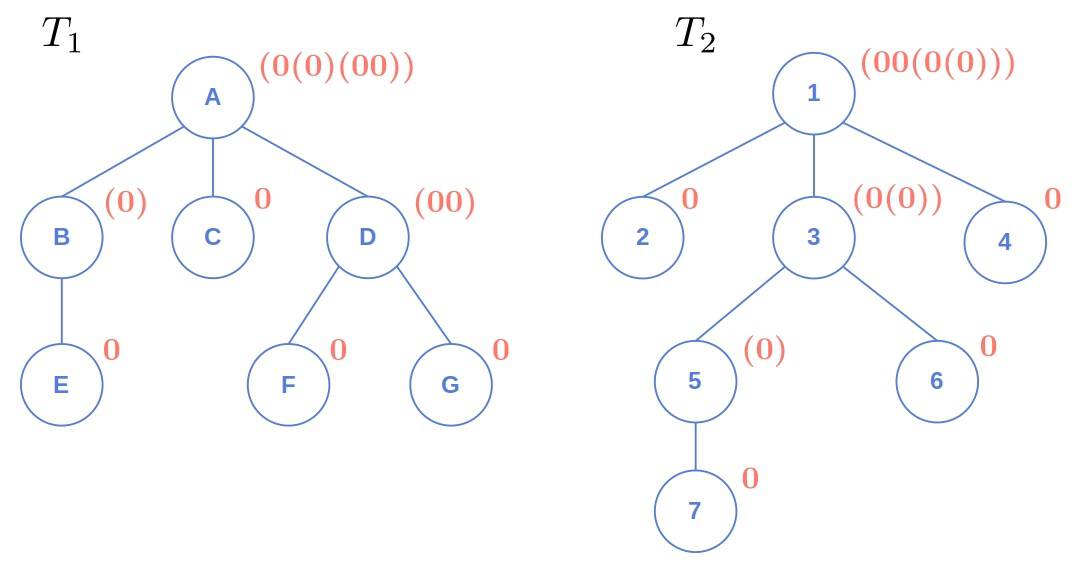
On the right, we have the same tree as on the left but rooted at a different node. As we see, their AHU encodings differ.
To fix this, we’ll first find the centers of and and root the trees at them. If they have the same structure, their encodings, when rooted at the centers, will be the same.
If or have two centers, we’ll try all pairings.
4.2. Pseudocode
Here’s the pseudocode:
algorithm CheckIsomorphicTrees(T1, T2):
// INPUT
// T1 and T2 = two trees
// OUTPUT
// true if T1 and T2 are isomorphic, false otherwise
for center1 in FIND-CENTERS(T1):
T1.root <- center1
for center2 in FIND-CENTERS(T2):
T2.root <- center2
if AHU(T1) = AHU(T2):
return true
return falseSo, we first find the centers. Then, we use the centers as the roots and try to match the encodings. If any combination gives a match, we’ll prove the isomorphism of and . However, if we find no match, the trees aren’t isomorphic, so we return  .
.
4.3. Improvement
However, we don’t use the fact that the nodes at the same levels will have the same AHU tuples in the case of isomorphism, so a mismatch at any level means we can start with the next pair of centers. In the previous algorithm, we computed the entire AHU encodings even though we can stop if we find the levels that differ.
Also, since we’ll compare the trees level by level, we can shorten the encodings as follows. After computing the strings for all the nodes at the level  , we find the distinct encodings. Then, sort them, and we map the shortest unique string to 0, the second one to 1, and so on. When computing the encodings of the nodes at the level
, we find the distinct encodings. Then, sort them, and we map the shortest unique string to 0, the second one to 1, and so on. When computing the encodings of the nodes at the level  , we use the unique integers we assigned to the strings instead of the actual strings:
, we use the unique integers we assigned to the strings instead of the actual strings:
algorithm FasterIsomorphismCheck(T1, T2):
// INPUT
// T1 and T2 = two trees
// OUTPUT
// true if T1 and T2 are isomorphic, false otherwise
for center1 in FIND-CENTERS(T1):
T1.root <- center1
for center2 in FIND-CENTERS(T2):
T2.root <- center2
D1 <- make a dictionary mapping each level of T1 to the nodes at it
D2 <- do the same for T2
// Let h1 and h2 be the heights of T1 and T2
if h1 != h2:
return false
h <- h1
for u in (D1[h] + D2[h]):
AHU(u) <- 0
k <- h - 1
while k >= 1:
Determine the unique strings at level k in both trees
L1 <- sort the strings of the nodes of T1 at level k
L2 <- sort the strings of the nodes of T2 at level k
if L1 != L2:
return false
else:
Set the the encodings of the nodes
to the ranks of their strings in L1 and L2
k <- k - 1
return true
return falseAfter rooting the input tree at the centers, we check their heights because only trees with the same height can be isomorphic.
4.4. Complexity
In the worst case, both trees will have two centers. So, the while loop is executed at most four times. Its worst-case complexity is  . Why? First, every node is processed exactly once in the entire algorithm. That amounts to time.
. Why? First, every node is processed exactly once in the entire algorithm. That amounts to time.
Second, if  is the trees’ arity, in each iteration, we sort at most strings, each having no more than characters. Since is fixed and doesn’t grow with respect to
is the trees’ arity, in each iteration, we sort at most strings, each having no more than characters. Since is fixed and doesn’t grow with respect to  , the overhead is
, the overhead is  per iteration. As there are
per iteration. As there are  iterations in the worst case, where
iterations in the worst case, where  is the height, the total overhead is
is the height, the total overhead is  . Since
. Since  , we get the overhead.
, we get the overhead.
Finally, the postorder traversal is also . So, the algorithm has the  time complexity in the worst case.
time complexity in the worst case.
5. Conclusion
In this article, we showed how to check if two trees are isomorphic. We do this by rooting them at their centers and trying to match their AHU encodings. If the threes are indeed isomorphic, we’ll get a match.