

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll learn how to find and extract dates, times, and addresses from any text data.
Whether we need to process emails, documents, or any other text corpus, the logic is the same. This task is a classic NLP task that is very common in practice.
It can encompass constructing an automated system for date-time extraction from emails, extracting addresses of customers and clients from a large number of documents, and similar other processes.
Named Entity Recognition (NER) is a problem that has the goal of finding and classifying named entities mentioned in a text. These entities are classified into predefined categories, such as a person’s name, organization, location, address, time expression, etc. This problem is part of the natural language processing (NLP) area within the field of machine learning.
In the past 10 years, there has been a lot of research done on named entity recognition. We can now witness how more sophisticated methods, like transformer-based GPT-3, BERT, and others, are starting to dominate in solving every NLP-related problem. They’re even capable of writing the code of a function based on comments.
NER is not an exception. First, we’ll describe more classical approaches to solving this problem. Then we’ll learn how to utilize the power of transformers, and present a real example.
A rule-based parser is an algorithm that’s defined using a set of instructions that usually have hard-coded parts. A general method for parsing employs both a lexical analyzer and a syntax analyzer. The lexical analyzer breaks up words into their constituent characters, while the syntax analyzer determines what these characters mean in terms of language structure.
In our case, this approach might be useful when the format of dates, times, and addresses is consistent throughout the whole corpus. Therefore, we won’t need to use more complicated and time-complex methods.
For instance, if our documents have a date format of dd-mm-yyyy most of the time, then we can easily define a parser constructed of regular expressions or regex. They’re more or less similar in every programming language. In addition, we can define a dictionary with keywords for the recognition of our entities.
For example, the address extraction keyword might be street or st.
To summarize, we recommend this approach when the problem is simple, and can often be easily defined using rules or keywords. This approach is the fastest and doesn’t require setting up additional packages or dependencies.
One interesting way of solving this problem is to build a machine learning classifier. For instance, we can define the problem as binary classification, where the goal is to classify a word as address or not address. Similarly, the sketch of the problem might be multi-class classification, with classes date, time, address, and others.
For this solution, the first step will be to construct features. These features may consist of some statistical indicators of the current word, or indicators of words in the neighborhood. For example, let’s consider the sentence:
“On Wall Street, the financial industry officially started on May 17, 1792.”
The first step is to split the sentence into tokens (words), where each token represents one sample (row) of a data set for a classifier. In terms of features engineering, we need to be very creative, trying to construct as many different features as possible. Some features that might be represented include the number of letters or symbols in the word, does it have a capital letter or not, does it have a number or keyword, etc. Additionally, the label or target is the class of the word.
In our case, the data set with features from the aforementioned sentence would look like:
| token | nLetters | nSymb | hasCap | hasNum | hasStreet | prevW | nextW | … | label |
|---|---|---|---|---|---|---|---|---|---|
| On | 2 | 0 | 1 | 0 | 0 | NaN | Wall | … | other |
| Wall | 4 | 0 | 1 | 0 | 0 | On | Street | … | address |
| Street | 6 | 0 | 1 | 0 | 1 | Wall | the | … | address |
| … | … | … | … | … | … | … | … | … | … |
| May | 3 | 0 | 1 | 0 | 0 | on | 17 | … | date |
| 17 | 0 | 0 | 0 | 1 | 0 | May | 1792 | … | date |
| 1792 | 0 | 0 | 0 | 1 | 0 | 17 | NaN | … | date |
In summary, this approach might provide good results if there’s a large corpus of text so that the classifier can recognize patterns during training.
Also, we should note that this approach may demand more time to work out because of the iterative process between features engineering and training.
Transformers are the innovative architecture in NLP. They’re now used for almost every text-related task where there’s a need for semantic understanding of the text. Briefly, they’re neural networks with attention mechanisms, trained with a huge corpus of text sans supervision, and later fine-tuned for specific tasks. One of the most popular transformers is the BERT (Bidirectional Encoder Representations from Transformers) model.
Although all of this sounds very complicated, today the usage of BERT is simplified thanks to the increasingly popular and most used NLP library, Hugging Face. We can even try some of their models for token classification on-site, where the API for inference is provided. The idea is to take the existing model and use it directly, or additionally, fine-tune it for our purpose.
In general, this approach can be very useful when we need to extract some specific terms, such as terms from medicine, protein names, or names of chemical materials. However, for that, we would need to have annotated text for model fine-tuning.
So why not combine some of the previously mentioned methods into one model. Basically, that’s the NER model from the popular NLP library spaCy. It uses a neural network classifier with features such as POS tags, prefixes, suffixes, and other statistical attributes supported by vectors from word embedding.
As a result, we can easily test this model with a few lines of code:
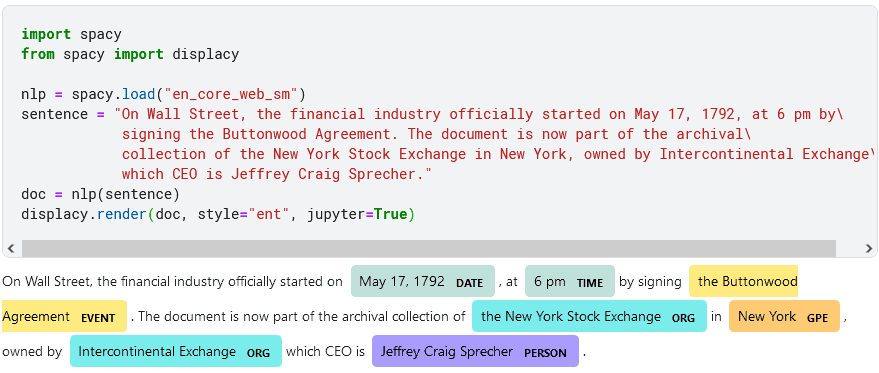
Although it’s not capable of recognizing address or street names, we can see that it successfully found and extracted other entities, such as date, time, event, organization, geopolitical entity, and person name.
In this article, we examined several ways of solving the named entity recognition problem. In general, there’s no one correct solution, and the approach heavily depends on the complexity of our task.
It’s upon us to know if we only need to extract dates using regex expression, or multiple entities using transformers. One thing is for sure, there are several different methods, and plenty of information available about this topic.