

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Last updated: March 18, 2024
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll show how to plot the decision boundary of a logistic regression classifier. We’ll focus on the binary case with two classes we usually call positive and negative. We’ll also assume that all the features are continuous.
Let  be the space of objects we want to classify using machine learning. The decision boundary of a classifier is the subset of
be the space of objects we want to classify using machine learning. The decision boundary of a classifier is the subset of  containing the objects for which the classifier’s score is equal to its decision threshold.
containing the objects for which the classifier’s score is equal to its decision threshold.
In the case of logistic regression (LR), the score  of an object
of an object  is the estimate of the probability that is positive, and the decision threshold is 0.5:
is the estimate of the probability that is positive, and the decision threshold is 0.5:
![\[\{ x \in \mathcal{X} \mid f(x) = 0.5 \}\]](/wp-content/ql-cache/quicklatex.com-d47fb261cf50be4a816b5b752366f759_l3.svg "Rendered by QuickLaTeX.com")
Visualizing the boundary helps us understand how our classifier works and compare it to other classification models.
To plot the boundary, we first have to find its equation.
We can derive the equation of the decision boundary by plugging in the formula of LR into the condition  .
.
We’ll assume that ![x= [x_0, x_1, x_2, \ldots, x_n]^T](/wp-content/ql-cache/quicklatex.com-993644656bf38a4291d5cf706aa8a89c_l3.svg "Rendered by QuickLaTeX.com") is an
is an  vector with
vector with  to make the LR equation more compact. In preprocessing, we can always prepend to any
to make the LR equation more compact. In preprocessing, we can always prepend to any  -dimensional .
-dimensional .
Consequently, we have:
![\[f(x) = \frac{1}{1 + e^{-\theta x}} = \frac{1}{2}\]](/wp-content/ql-cache/quicklatex.com-a28c87ae0b258528b49bfac50c6f71dc_l3.svg "Rendered by QuickLaTeX.com")
where ![\theta = [\theta_1, \theta_2, \ldots, \theta_n]^T](/wp-content/ql-cache/quicklatex.com-e74d9cff8674354ce0d9b11d95cd1cfc_l3.svg "Rendered by QuickLaTeX.com") is the parameter vector of our LR model
is the parameter vector of our LR model  . From there, we get:
. From there, we get:
![\[\begin{aligned} \frac{1}{1 + e^{-\theta^T x}} &= \frac{1}{2} \\ 1 + e^{-\theta^T x} &= 2 \\ e^{-\theta^T x} &= 1 \\ - \theta^T x &= 0 \\ \theta^T x &= 0 \\ \sum_{i=0}\theta_i x_i &= 0 \end{aligned}\]](/wp-content/ql-cache/quicklatex.com-5c42252510fc800f68307c90546746e0_l3.svg "Rendered by QuickLaTeX.com")
If  , the boundary equation becomes:
, the boundary equation becomes:
![\[\theta_0 + \theta_1 x_1 + \theta_2 x_2 = 0\]](/wp-content/ql-cache/quicklatex.com-309ccdc364fd6952f75a5eab19fd4458_l3.svg "Rendered by QuickLaTeX.com")
That’s a line in the  ) plane. For example, if we use the iris dataset with
) plane. For example, if we use the iris dataset with  and
and  being the sepal length and width, and with versicolor and virginica classes blended into one, we’ll get a straight line:
being the sepal length and width, and with versicolor and virginica classes blended into one, we’ll get a straight line:
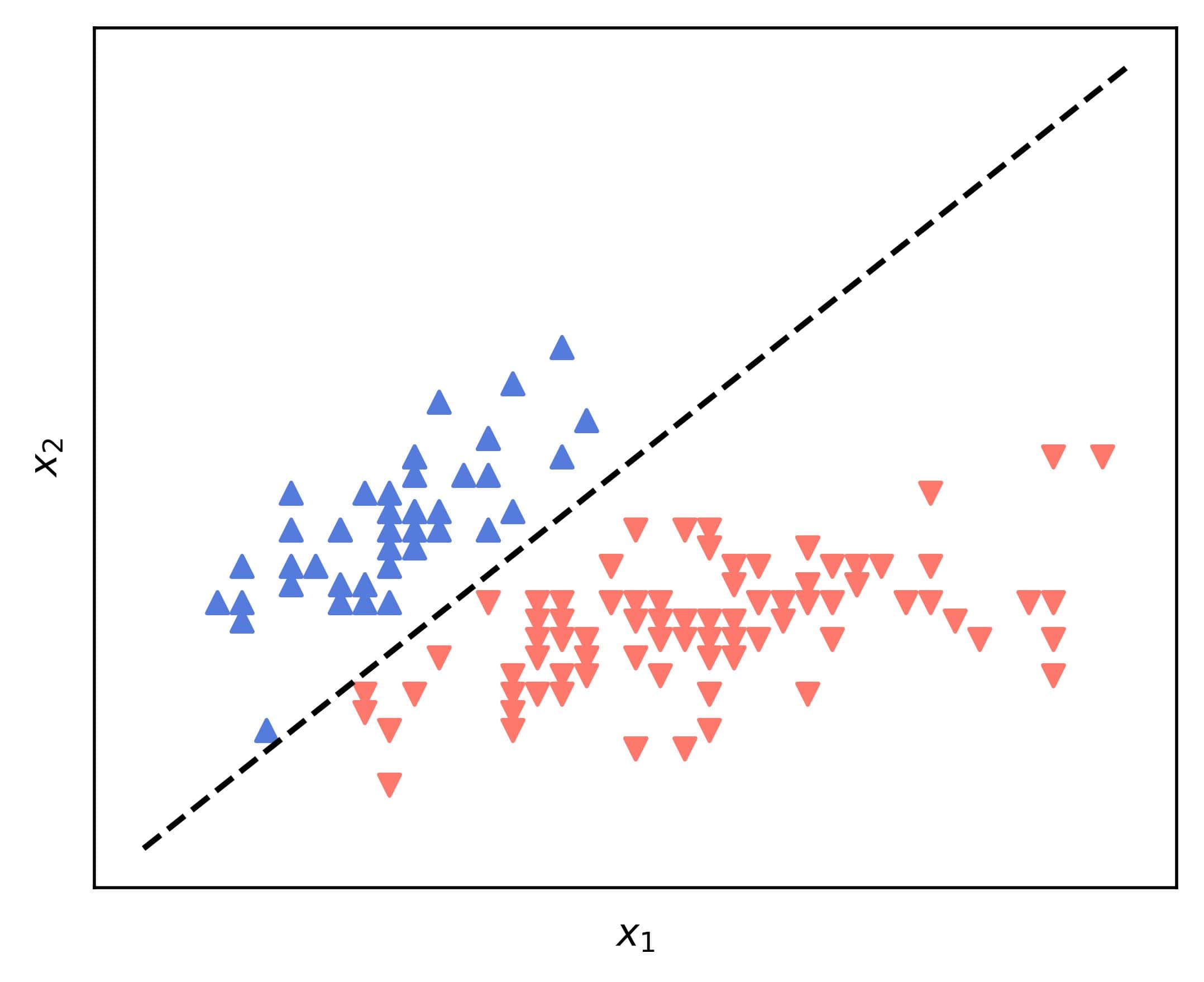
We don’t have to consider the degenerate case where  . That implies that no features of are used, so we won’t use such a model anyway. Let’s say
. That implies that no features of are used, so we won’t use such a model anyway. Let’s say  . The explicit boundary’s equation is then:
. The explicit boundary’s equation is then:
![\[x_2 = -\frac{\theta_1}{\theta_2}x_1 - \frac{\theta_0}{\theta_2}\]](/wp-content/ql-cache/quicklatex.com-1b0142f7fc203913f6ec8922aea8059e_l3.svg "Rendered by QuickLaTeX.com")
If  , we have a plane given by:
, we have a plane given by:
![\[\theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_3 = 0\]](/wp-content/ql-cache/quicklatex.com-cd9c49021ff779b9d5a916e09eb89a29_l3.svg "Rendered by QuickLaTeX.com")
Let  . Then, we can write the equation in the explicit form:
. Then, we can write the equation in the explicit form:
![\[x_3 = -\frac{\theta_2}{\theta_3} x_2 -\frac{\theta_1}{\theta_3}x_1 - \frac{\theta_0}{\theta_3}\]](/wp-content/ql-cache/quicklatex.com-374077bf4c95f7a11e65231f6531d22d_l3.svg "Rendered by QuickLaTeX.com")
We can use any plotting tool to visualize lines and planes corresponding to these equations. If we have to do it from scratch, we can iterate over the independent features in small increments and calculate the dependent feature using the explicit forms:
The limits  and
and  determine the part of the boundary we want to focus on.
determine the part of the boundary we want to focus on.
We have two questions at his point:
Let’s find out.
If our objects have more than three features, we can visualize only the boundary’s projections onto the planes and spaces defined by pairs and triplets of features.
One way we deal with this is to choose the features for visualization and keep the others at constant values, such as means or constants of interest we know from theory. Values that mean “the feature is absent or neutral” can also be helpful. In most, but not all cases, that would mean setting those other features to zeros.
With 10 features  , we have
, we have  feature pairs. Let’s say we choose and
feature pairs. Let’s say we choose and  for visualizing the boundary. In that case, we set
for visualizing the boundary. In that case, we set  to some constant values. Let them be
to some constant values. Let them be  .
.
Then,  is another constant. We add it to
is another constant. We add it to  and proceed as if and are the only two features of interest:
and proceed as if and are the only two features of interest:
![\[x_2 = -\frac{\theta_1}{\theta_2} - \frac{1}{\theta_2}\left(\theta_0 + \sum_{i = 3}^{10} \theta_i \chi_i \right)\]](/wp-content/ql-cache/quicklatex.com-24db2bb41a198bc9016f33f47560dfff_l3.svg "Rendered by QuickLaTeX.com")
This can work for any pair or triplet of  .
.
However, a disadvantage of this approach is that the boundary depends on the chosen constants  .
.
We can introduce curvatures with feature engineering.
Let’s say that our original features are ![[x_1, x_2]](/wp-content/ql-cache/quicklatex.com-1dedfa817216ee3888102ca38c9a614f_l3.svg "Rendered by QuickLaTeX.com") . Before pretending
. Before pretending  , we can add
, we can add  . Then, the decision boundary becomes:
. Then, the decision boundary becomes:
![\[\theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_1^2 = 0 \implies x_2 = -\frac{\theta_0}{\theta_2} - \frac{\theta_1}{\theta_2}x_1 - \frac{\theta_3}{\theta_2}x_1^2\]](/wp-content/ql-cache/quicklatex.com-b1cdbf5a5c1cbd58c8261e7bd9f4367d_l3.svg "Rendered by QuickLaTeX.com")
which is a curve in the original  space. For instance:
space. For instance:
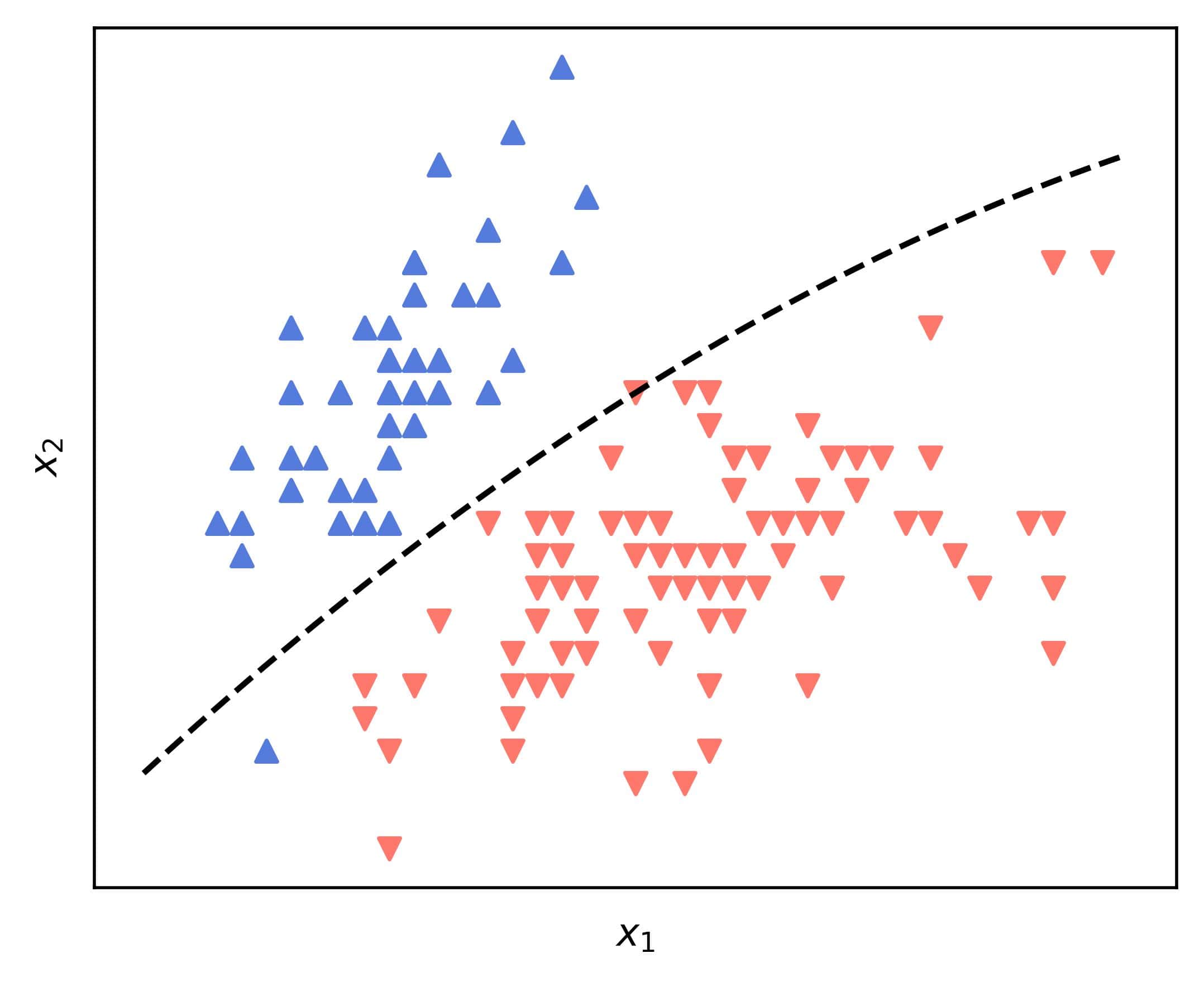
However, the same boundary is a plane in the augmented  space.
space.
In this article, we showed how to visualize the logistic regression’s decision boundary. Plotting it helps us understand how our logistic model works.
