

Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
Learn through the super-clean Baeldung Pro experience:
>> Membership and Baeldung Pro.
No ads, dark-mode and 6 months free of IntelliJ Idea Ultimate to start with.
In this tutorial, we’ll understand the concept of transactions.
We’ll go through the types of transactions and the different guarantees they provide. We’ll also explore different protocols and algorithms to deal with distributed transactions in heterogeneous environments.
In programming, we refer to a transaction as a group of related actions that need to be performed as a single action. In other words, a transaction is a logical unit of work whose effect is visible outside the transaction either in its entirety or not at all. We require this to ensure data integrity in our applications.
Let’s have a look at an example to understand this better. A typical requirement in event-based architecture is to update the local database and produce an event for consumption by other services:
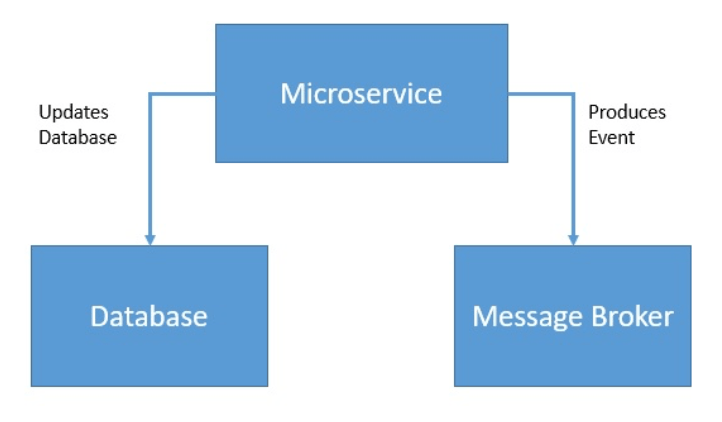
Here, we’d like these two operations to either happen together or not happen at all. We can achieve this by wrapping these operations into a single transaction:
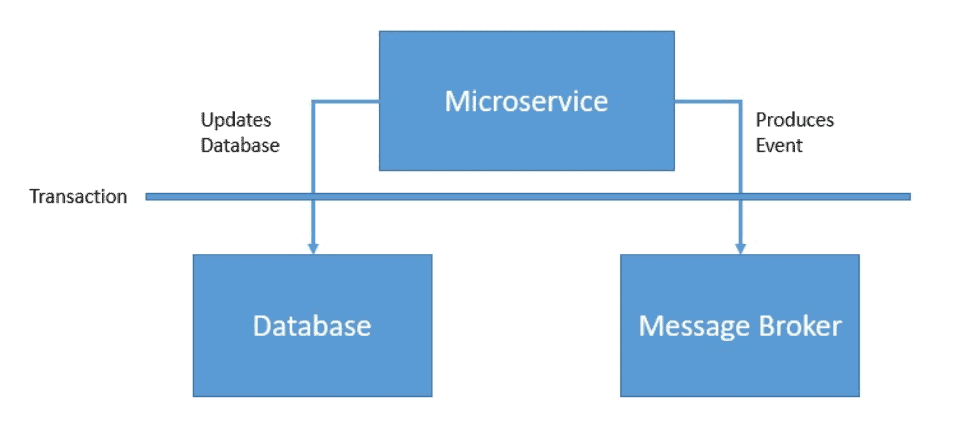
We typically refer to these components like database and message broker as participating resources in a transaction.
We mostly associate the concept of transactions with relational databases. Hence, the history and evolution of transactions are closely related to those of relational databases as well.
We largely attribute the introduction of the relational model of data to Edgar F. Codd, who published his seminal paper on this subject back in 1970.
The ease and flexibility of relational databases made them commonplace. This brought the complexities of large multi-user, concurrently accessible systems. Soon, it was realized that some consistency enforcement was necessary.
This gave birth to the ACID properties. Transactions adhering to ACID properties are guaranteed to be atomic and serializable. A transaction processing system is responsible for ensuring the ACID properties. This worked very well for flat transactions with short execution time, fewer concurrent users, and a single database system.
But soon, as the demand started to surge, the complexities started to grow as well. Applications started to require long-living and complex transactions. This resulted in complex transaction models like sub-transaction and transaction groups.
This gave more precise control for failure scenarios, especially in the case of long-living transactions.
The next phase of evolution in transactions came through the support of distributed and nested transactions. The applications grew more complex and often required transactional access to multiple database systems. The distributed transaction takes a bottom-up approach while the nested transaction takes a top-down approach to decompose a complex transaction into subtransactions.
Distributed transactions provided global integrity constraints over multiple resources. These resources soon started to be heterogeneous as well. This gave birth to the X/Open DTP (Distributed Transaction Processing) model.
The other important evolution for transactions included chained transactions and sagas. While nested transactions worked well for federated database systems, it still was not suitable for long-lived transactions. Chained transactions presented the idea to decompose such transactions into small, sequentially executing sub-transactions.
Sagas were based on the concept of chained transactions and proposed a compensation mechanism to roll back already completed sub-transactions. The saga model is an important transaction model because of the relaxed consistency it proposes. It finds a lot of relevance in the present-day applications developed with microservice architecture.
We’ll discuss many of the terms and concepts presented here in more detail later in the tutorial.
Operations that are part of a transaction can all execute in a single participating resource or span across multiple participating resources. Hence, transactions can be local or distributed.
In local transactions, operations execute in the same resource. While in distributed transactions, operations are spread across multiple resources:
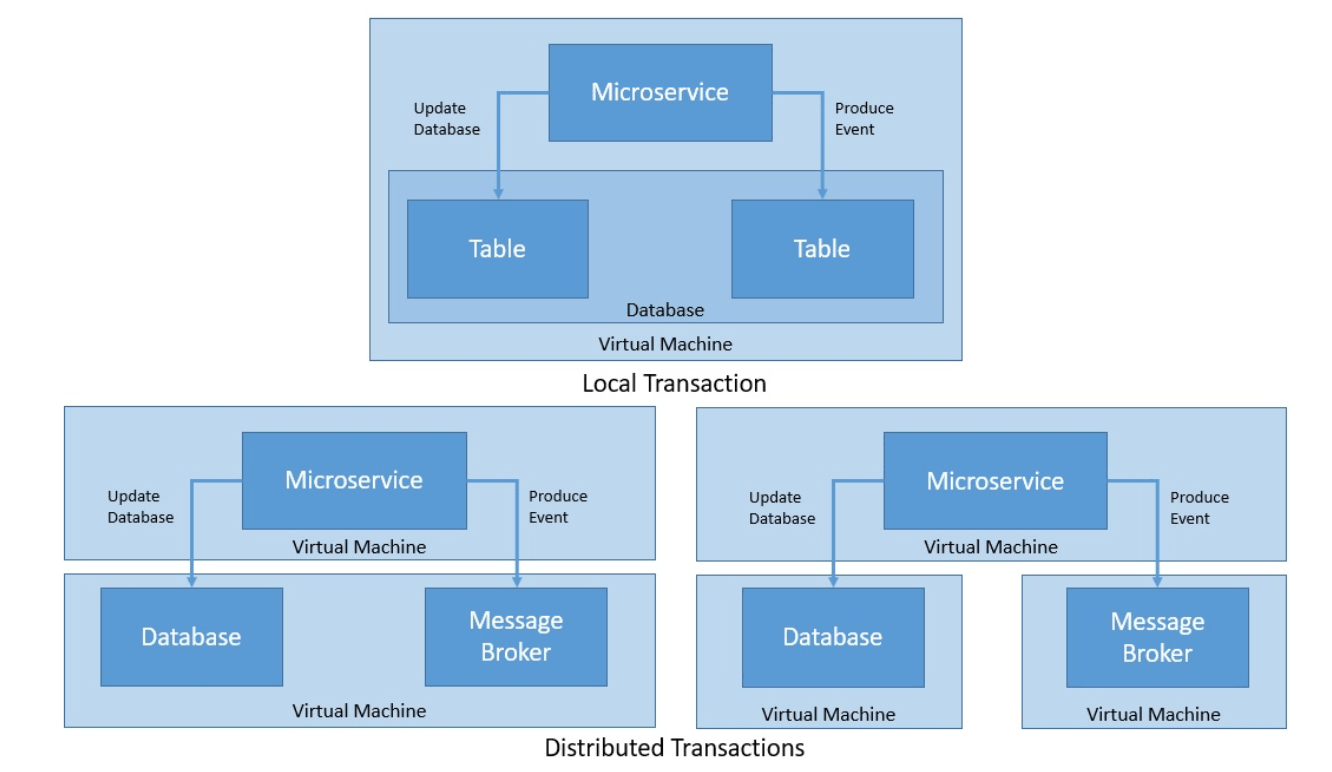
So far, we haven’t spoken about the location of participating resources in a transaction. A transaction can involve multiple independent resources like databases, message queues, or web services. These resources can execute on the same virtual machine, on different virtual machines in the same physical machine, or different physical machines altogether.
The number and location of participating resources is a crucial aspect in implementing transactions with certain guarantees, which we’ll elaborate more in the next section.
One of the fundamental reasons to use transactions in handling data is to ensure data integrity. Data integrity has been well defined by a set of guarantees that every transaction is supposed to provide.
Further, a distributed data system presents new challenges that can force us to forfeit some of these guarantees in favor of better leverage from data partitioning. We’ll explore these concepts in this section.
We often associate transactions with a set of guarantees, famously captured in the acronym ACID. The concept was originally suggested by Jim Gray and later expanded by Andreas Reuter and Theo Härder. ACID stands for Atomicity, Consistency, Isolation, and Durability:
These are the guarantees which we should expect from a transaction. But, a transaction doesn’t need to provide all of them. We can find many arguments in the literature that suggest that a transaction that does not provide ACID guarantees is not a transaction at all.
However, with more adoption of distributed systems where the emphasis is on availability, we often see the term transaction being used more liberally.
Distributed data systems are generally constrained by CAP theorem in what they can offer. Eric Brewer provided the original conjecture in 2000, while Seth Gilbert and Nancy Lynch provided a formal proof of this in 2002. CAP stands for Consistency, Availability and Partition tolerance:
CAP theorem states that a distributed data system can’t provide all three of consistency, availability, and partition tolerance simultaneously. In a more pragmatic sense, a distributed data system can only provide a strong guarantee of either availability or consistency.
This is because a distributed data system by default should not compromise partition tolerance anyways.
Under the constraints of the CAP theorem, many distributed data systems chose to favor consistency over availability. This gives rise to a new set of guarantees for distributed systems with the acronym as the BASE. The BASE stands for Basically-available, Soft-state, and Eventual consistency:
BASE is diametrically opposite to ACID in terms of the consistency model they propose. While ACID enforces consistency at the end of every transaction, BASE accepts that the consistency may be in a state of flux at the end of the transaction.
This relaxation in strong consistency requirements allows for a distributed data system to achieve high availability.
Almost all popular relational databases provide support for transactions by default. Since a local transaction involves just one database, the database can manage such transactions directly. Moreover, the application can control the transaction boundary through relevant APIs.
However, it starts to get complicated when we talk about distributed transactions. Since there are multiple databases or resources involved here, a database can’t manage such a transaction exclusively. What we need here is a transaction coordinator and individual resources like a database to cooperate in the transaction.
For a distributed transaction to guarantee ACID properties, what we need is a coordination protocol. Two-phase commit is a widely-used distributed algorithm to facilitate the decision to commit or rollback a distributed transaction.
The protocol consists of two phases:
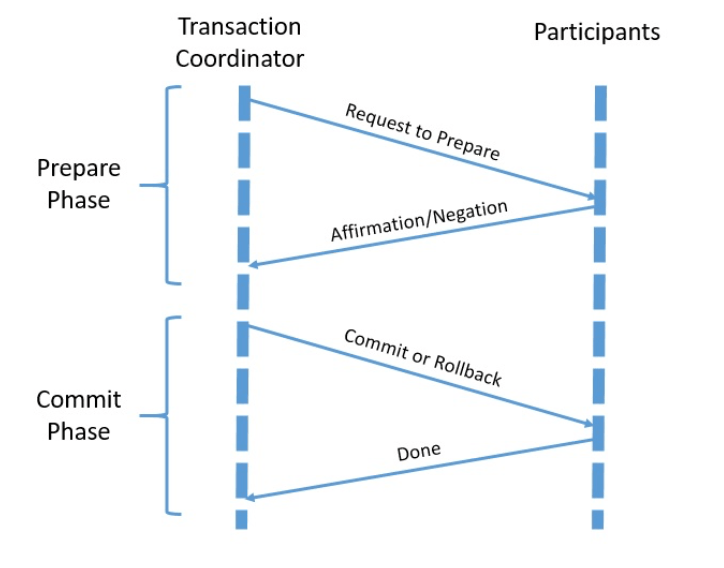
A transaction coordinator facilitates the two-phase commit with all the participants. For a participant to participate in a two-phase commit, it must understand and support the protocol.
The two-phase commit protocol, although quite useful, is not quite as robust as we may imagine. One of the key problems is that it can not dependably recover from a failure of both the coordinator and one of the participants during the commit phase.
The three-phase commit protocol is a refinement over the two-phase commit protocol which addresses this issue. It introduces the third phase by splitting the commit phase into pre-commit and commit phases:
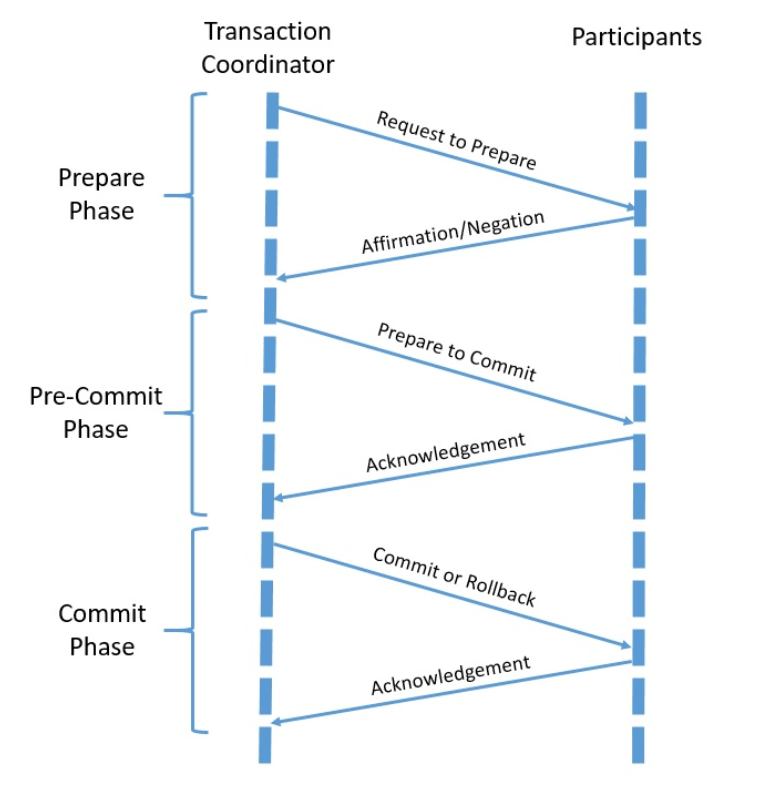
The pre-commit phase here helps to recover from the failure scenario where either a participant fails or both the coordinator and a participant fails during the commit phase. The recovery coordinator can use the pre-commit phase to safely decide if it has to proceed with the commit or abort.
While these commit protocols ensure us the ACID guarantees in a distributed transaction, it’s not free from its one share of problems. The biggest challenge with these protocols is that these are blocking protocols which, as we’ll see later, isn’t always suitable.
Vendors can independently implement distributed transaction protocols like two-phase commit. However, this will make interoperability quite a challenge, especially when working with multiple vendors. The complexity further grows when we start to include heterogeneous resources like message queues in the transaction.
To exactly address this issue, there have been several industry collaborations to define standard specifications for distributed transactions.
XA refers to eXtended Architecture, which is a specification for distributed transaction processing. It was first released in 1991 by X/Open consortium, which later merged with The Open Group. The goal of this specification is to provide atomicity in global transactions involving heterogeneous components.
The XA specification provides data integrity using the two-phase commit protocol and standardizes the components and interfaces involved:
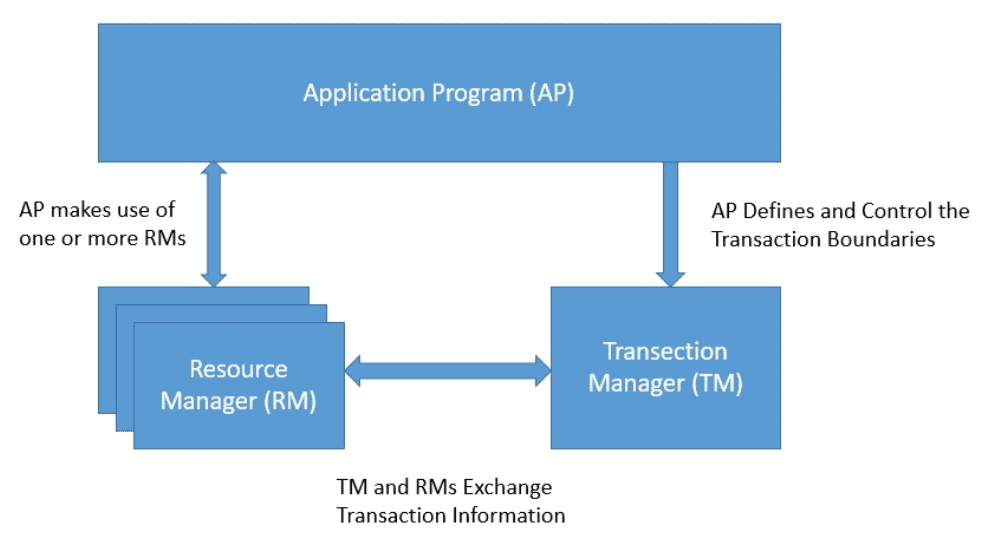
XA describes several components to facilitate a two-phase commit based distributed transaction:
XA also describes the interface between these components to facilitate how they work with each other. This explanation has just mentioned the important parts of the XA specification and is not a complete description.
OTS stands for Object Transaction Service which describes a communication infrastructure for distributed application in an object-oriented manner. This is part of the Object Management Architecture (OMA) of the Object Management Group (OMG).
OTS enables the use of distributed two-phase commit transactions in CORBA applications by defining several components along with their interworking:
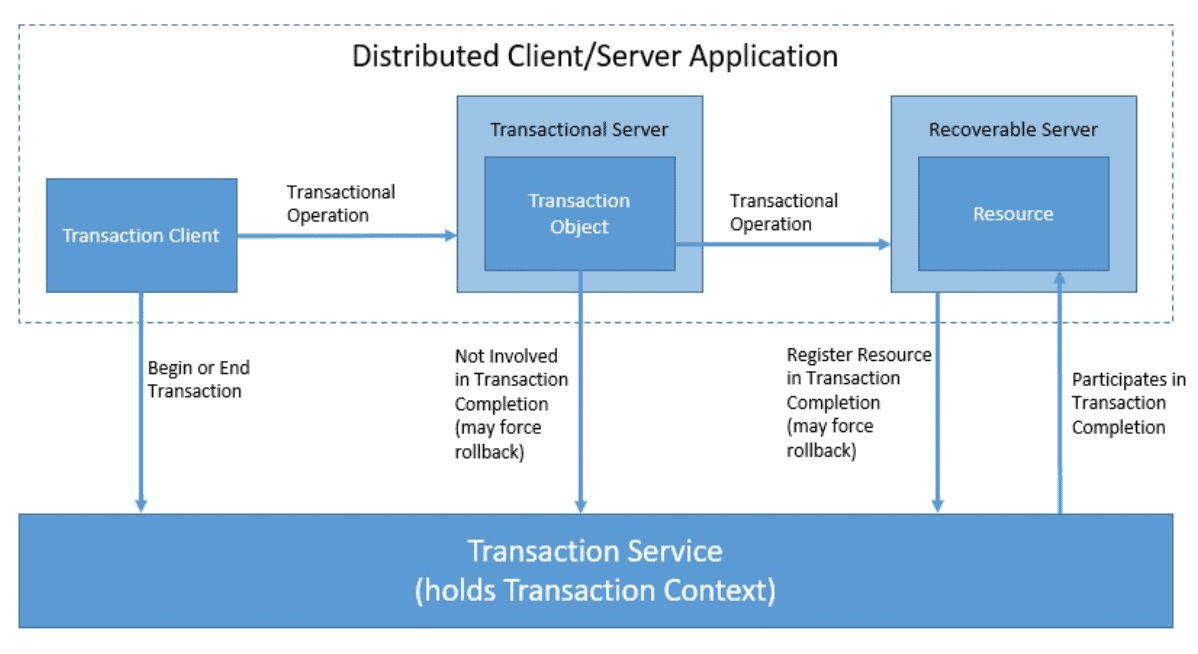
Let’s understand these components in little more detail:
OTS is one of the several object services provided by OMG under OMA. The kernel of the OMA architecture is Object Request Broker (ORB) defined in the CORBA specification.
Moreover, the OTS model is based on the X/Open DTP model, where it replaces the XA and TX interfaces with CORBA IDL interfaces. A thorough analysis of OTS is beyond the scope of this tutorial.
While most of the distributed transaction protocols focus on providing ACID guarantees, they all suffer from the fact that they are blocking. While they work perfectly well for transactions with short execution time, they are unsuitable for long-running business transactions.
It can make an application extremely difficult to scale. Traditional techniques using resource locking don’t agree well with modern applications that require business transactions in a loosely-coupled, asynchronous environment; for instance, business transactions in an application built with microservices architecture.
There have been several attempts to define patterns and specifications to address long-running transactions, and we’ll discuss some of them in this section.
The saga interaction pattern attempts to break a long-running business process to multiple small and related business actions and interactions. Further, it coordinates the whole process by managing based on messages and timeouts. This was first defined back in 1987 by Hector Garcia-Molina and Kenneth Salem.
Let’s see how Saga decomposes a business process:
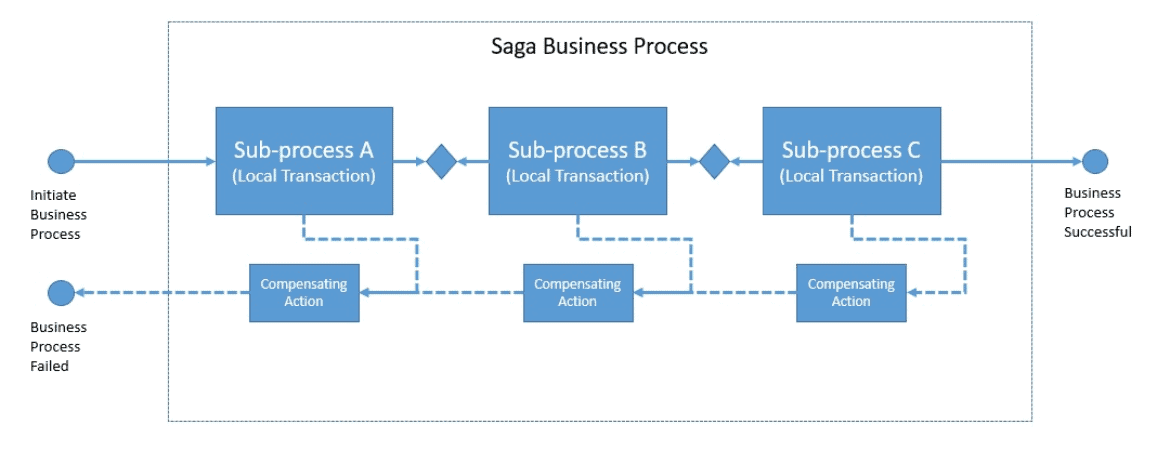
Contrary to an ACID transaction, we can not rollback in the case of Saga when a failure occurs. Here, what we do instead is called counteraction, or compensating action. A counteraction is, however, just a best effort to undo the effect of the original action. It may not be possible to completely revert the effect of every transaction always.
Further, the Saga pattern requires individual actions and their corresponding counteractions to be idempotent for a successful recovery from failures.
The saga interaction pattern finds a great fit for SOA-based architecture with SOAP service-based interactions. Several protocol extensions have been defined for SOAP to address specific communication requirements. These collectively fall under WS* and include protocols for supporting distributed transactions.
Web Services – Business Activity (WS-BA) defines an orderly protocol and states for both the participating services and the coordinator in a Saga-based business process. WS-BA defines two protocols:
Further, WS-BA defines two coordination types. First is the Atomic Outcome, where all participants have to close or compensate. Second is the Mixed Outcome, where the coordinator treats each participant differently.
Business Transaction Process (BTP) provides a common understanding and a way to communicate guarantees and limits on guarantees between organizations. This provides formal rules for the distribution of parts of the business process outside the boundaries of an organization.
While BTP provides coordination and forces a consistent termination of the business process, it relies on local compensating actions from participating organizations. BTP provides two different protocols:
Hence, BTP provides a compensation-based transaction semantic for distributed business processes operating in heterogeneous environments.
The decision, whether to commit a transaction to a database is part of a broader set of problems in distributed computing known as the consensus problem. The problem is to achieve system reliability in the presence of random failures. Consensus refers to a process for distributed processes to agree on some state or decision. Other such decisions include leader election, state machine replication, and clock synchronization.
What we need to solve the consensus problem is a consensus protocol. A consensus protocol must provide eventual termination, data integrity, and agreement between distributed processes or nodes. Different consensus protocols can prescribe different levels of integrity here. Important evaluation criteria for consensus protocols include running time and message complexity.
The distributed commit protocols that we have discussed so far like two-phase commit and three-phase commit, all are types of consensus protocols. The two-phase commit protocol has a low message complexity and low overall latency, but blocks on the coordinator failure. The three-phase commit protocol improves upon this problem at the cost of higher overall latency. Even the three-phase commit protocol comes apart in the face of network-partition.
What we’re going to discuss in this section are some advanced consensus protocols that address the problems associated with failure scenarios.
Paxos is a family of protocols originally proposed in 1989 by Leslie Lamport. These protocols solve consensus problems in an asynchronous network of unreliable processes. Paxos provides durability even with the failure of a bounded number of replicas in the network. Paxos has been widely regarded as the first consensus protocol that is rigorously proved to be correct.
Since its proposal, there have been several versions of the Paxos protocol proposed. We’ll examine the most basic Paxos protocol here. The basic Paxos protocol proposes multiple rounds, each with two phases, both further divided into two sub-phases:
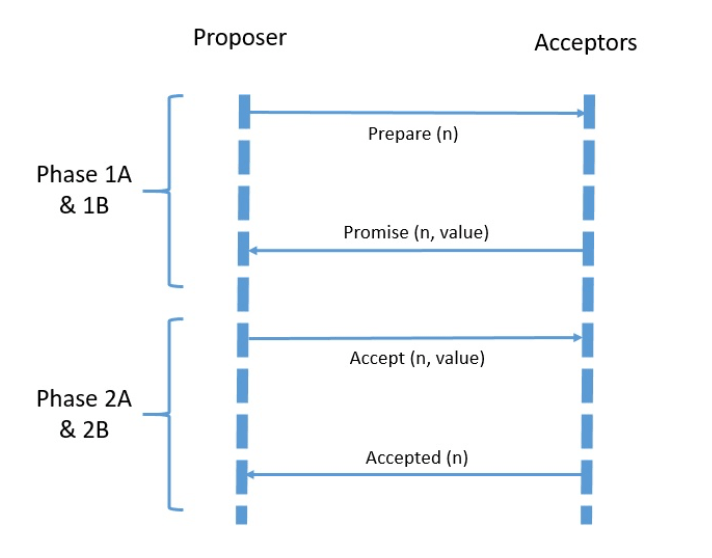
Note that Paxos allows multiple proposers to send conflicting messages and acceptors to accept multiple proposals. In the process, rounds can fail but Paxos ensures that the acceptors ultimately agree on a single value.
Raft is a consensus algorithm developed by Diego Ongaro and John Ousterhout in their seminal paper and later expanded in a doctoral dissertation. It stands for Reliable, Replicated, Redundant, And Fault-Tolerant.
Raft offers a generic way to distribute a state machine across a cluster of computing nodes. Further, it ensures that each node in the cluster agrees upon the same series of state transitions. Raft works by keeping a replicated log and only a single node, the leader can manage it.
Raft divides the consensus problem into three sub-problems:
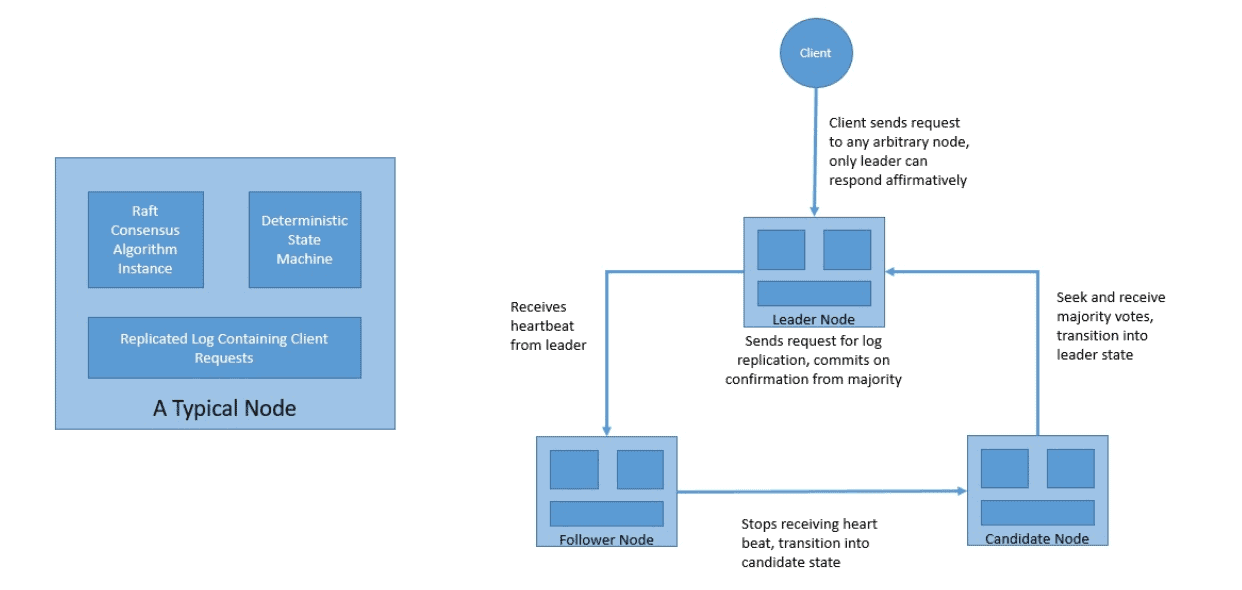
Please note that Raft is equivalent to Paxos in fault-tolerance and performance. Like Paxos, Raft is also formally proven to be safe. But importantly, Raft is easier to understand and develop than its much more complex predecessor Paxos.
In this tutorial, we had a look at what is meant by a transaction and differences between local and distributed transactions.
We also went through some of the popular protocols for handling distributed transactions. Further, we touched upon the industry specifications that are available and their support in Java.
We also discussed the long-running transactions and finally about some of the complex consensus algorithms.